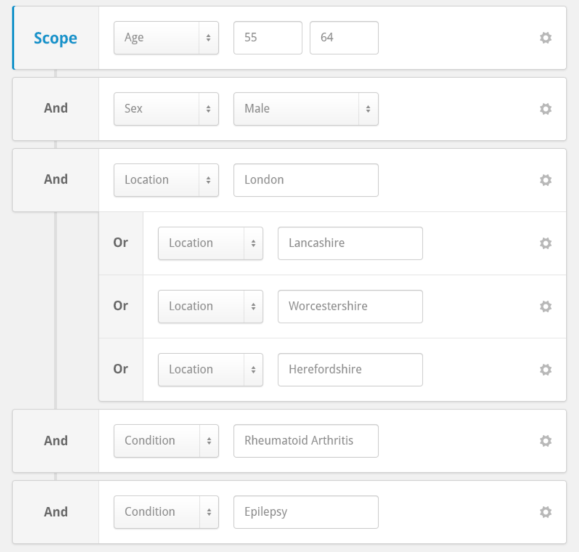
I’ve written a ton of SQL and Cypher queries over the last 20 years…and I’ve rewritten those queries as stored procedures more times than I can count. The issues with the expressivity of the query language and the ability of the query optimizer to “do the right thing” have been around longer than my career. I’ve written about this problem before. I went so far as to completely give up. In RageDB I let the developer write the query in a programming language directly. Skipping the “middle man” and letting the user be the query optimizer. Because in the end… this is what always happens. Well almost always.
Continue reading