A couple of weeks ago, Helene looked at me hunched over on my computer and said “You’re working like a caveman”. She is a bigwig in her company and her team does things I can’t share that we will call “AI stuff”. What she meant was that I was still lovingly hand crafting every single line of code I was writing. I was using zero AI. I was living under a rock. In my defense, I’m 47 years old, which might as well be considered “dead” in developer age. My age group is supposed to be in the “Late Majority” or “Laggards” category of the innovation adoption curve. Her team is building entire applications in weeks using AI and I am lucky to get a small feature a day. She told me to take my old RageDB project and use it to learn.
If you’re a long time reader, you know I have a thing against declarative languages. I find them all liars, so RageDB never got Cypher or some made up graph query language. Instead I was using Lua to create what boils down to “query plans” by hand as my way of talking to it. It’s cool, but realistically nobody is going to do that. So I decided to let the AI do something I would have hated doing (and probably never done) which is write a GQL interface for RageDB.
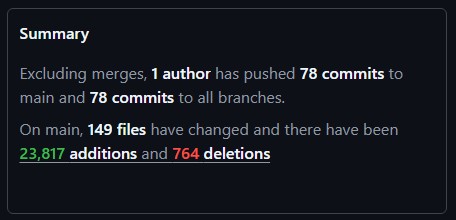
I fired up Google Antigravity, and pointed it to my ragedb repository. I told it to look at other GQL implementations by Kuzu, Ladybug, FroGQL, Nebula Graph, Ultipa. I told it to look at their documentation, their test suites and then add GQL to RageDB. Twenty Three Thousand Lines of code in a flash. That flash was a few evening hours over a few days, but what it was able to do in a short time would have taken me ages. Maybe 9 months if I’m being generous, but really an infinite amount of time since I don’t have much expertise in grammars, lexers and implementing query optimizers. I know how to use mechanical sympathy to build query plans by hand, been doing that for ever, but not automating that process.
While I was there I told it to implement the type checker from FrogQL, implement the factorizer from Kuzu, implement the query cache from Neo4j, implement the documentation from Nebula, implement query plan optimizations from everybody. I told it to build an optimized K-Hop counts function. I told it to build a shortest path and a weighted shortest path function. I told it to build an exact index, and a full text search index. These features would normally take a team months and months to do, and it did them all like if it was nothing. I can imagine the blood, sweat and tears any software team would have suffered doing this work, and to AI, it was child’s play. If you can think it, it can build it…fast.
Dump your two week sprints, dump your prioritization meetings, dump your agile coaches and scrum teams. Zed Shaw was right all along. The software development world has changed. I get it now.