
As much as we all love graphs, the rest of the world hasn’t quite caught on yet. They are still sending CSV files to each other like some sort of cavemen. We have a few options for dealing with them. One is to convert them to a specific file format and bulk load them into the database as fast as possible. Another is to stream them one row at a time as-is and potentially do some transformations on the fly as needed and turn each row into one or more pieces of data. Today we’re going to go with option 2.
One of the amazing things about just slapping Lua as our “query” language on RageDB is that we can take advantage of the Lua ecosystem and all the libraries that already exist for the language. So I went to LuaRocks to look for a CSV package.

There I found a few and settled on ftcsv. Adding it to RageDB was a matter of copying one file and requiring it when wiring up the sol2 library alongside the make shift json library we have. No really.
lua.open_libraries(sol::lib::base, sol::lib::package, sol::lib::math, sol::lib::string, sol::lib::table, sol::lib::io, sol::lib::os);
lua.require_file("json", "./lua/json.lua");
lua.require_file("ftcsv", "./lua/ftcsv.lua");
So let’s try it out. We’ll create a simple.csv file with a header that looks like this:
name,weight
tyler,90
ronnie,95
nicky,5
nelly,8
peanut,7
Now we can create some nodes with this data, but before we do that we need to create the Schema. Actually we can do both at the same time! Let’s create an Item node with a “name” property that is a string and a “weight” property that is an integer. We’ll use the parseLine method to process one row at a time, but it reads it in 64kb chunks from disk (it’s configurable, see the docs) so it reads the whole file in one go. For each row, we’ll add the node to our database creating the key using the iterator “i” and adding the “name” and “weight” properties into a json blob that the server will parse and deal with.
NodeTypeInsert("Item")
NodePropertyTypeAdd("Item", "name", "string")
NodePropertyTypeAdd("Item", "weight", "integer")
for i, item in ftcsv.parseLine("/home/max/CLionProjects/tmp/simple.csv", ",") do
NodeAdd("Item", "item"..i, "{\"name\":".."\""..item.name.."\", \"weight\":"..item.weight.."}")
end
AllNodes()
At the end of our “query” we’re returning “AllNodes()” to get the 5 nodes we created back from the database, and this is our result:
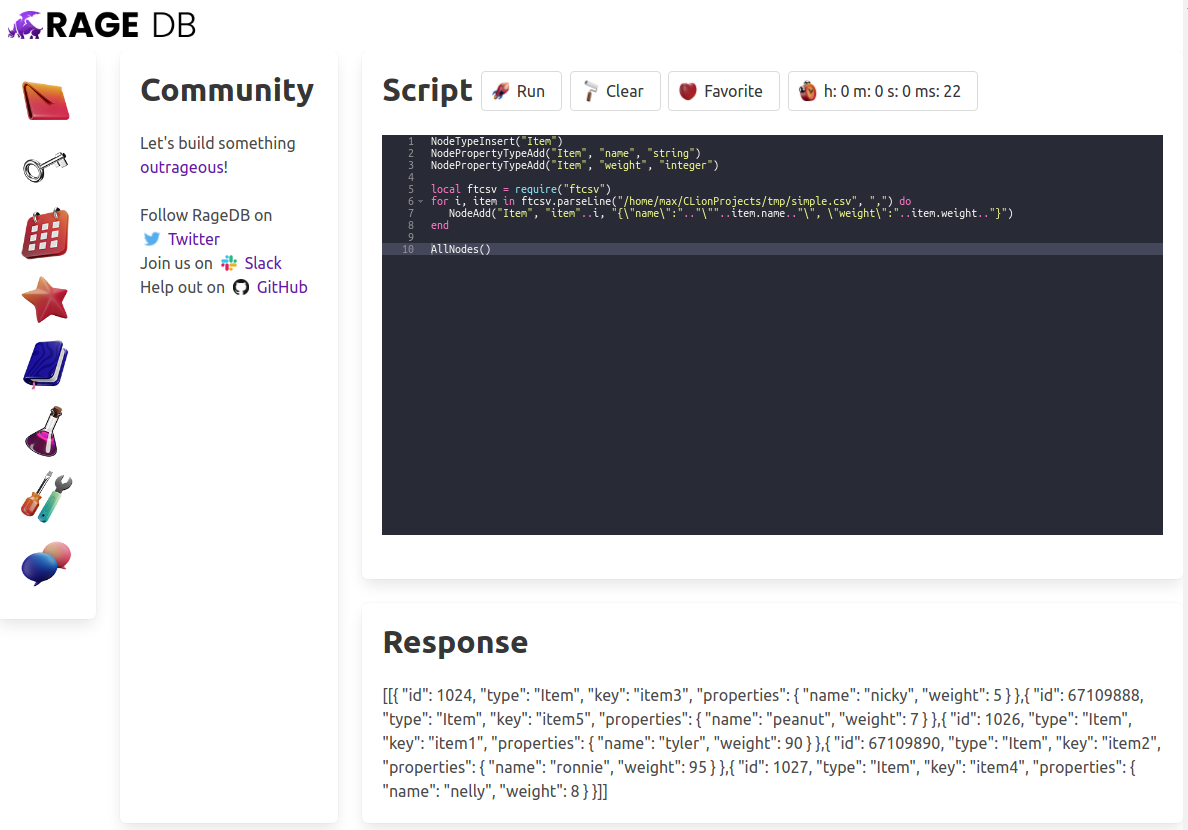
Take a look at that hotness! We just added a whole lot of awesome functionality to our database in literally 5 minutes. Sure 10x developers are cool, but you what’s better?

So we can eat through a 6 row csv file in 22 milliseconds that’s great, but not very satisfying. Let’s tackle a bigger challenge. One of the gauntlets graph databases must face is the LDBC Social Network Benchmarks. Yeah… we’ve seen this before due to some controversy when one vendor measures another vendors product. Don’t do that.

We’re not going to get into the query writing just yet, we’ll save that for another post. Instead we’ll work on just loading the data, but first we need a schema… and before we get a schema we need to figure out just what in the world we are modeling. Luckily they provide a lovely graphic to help us out:
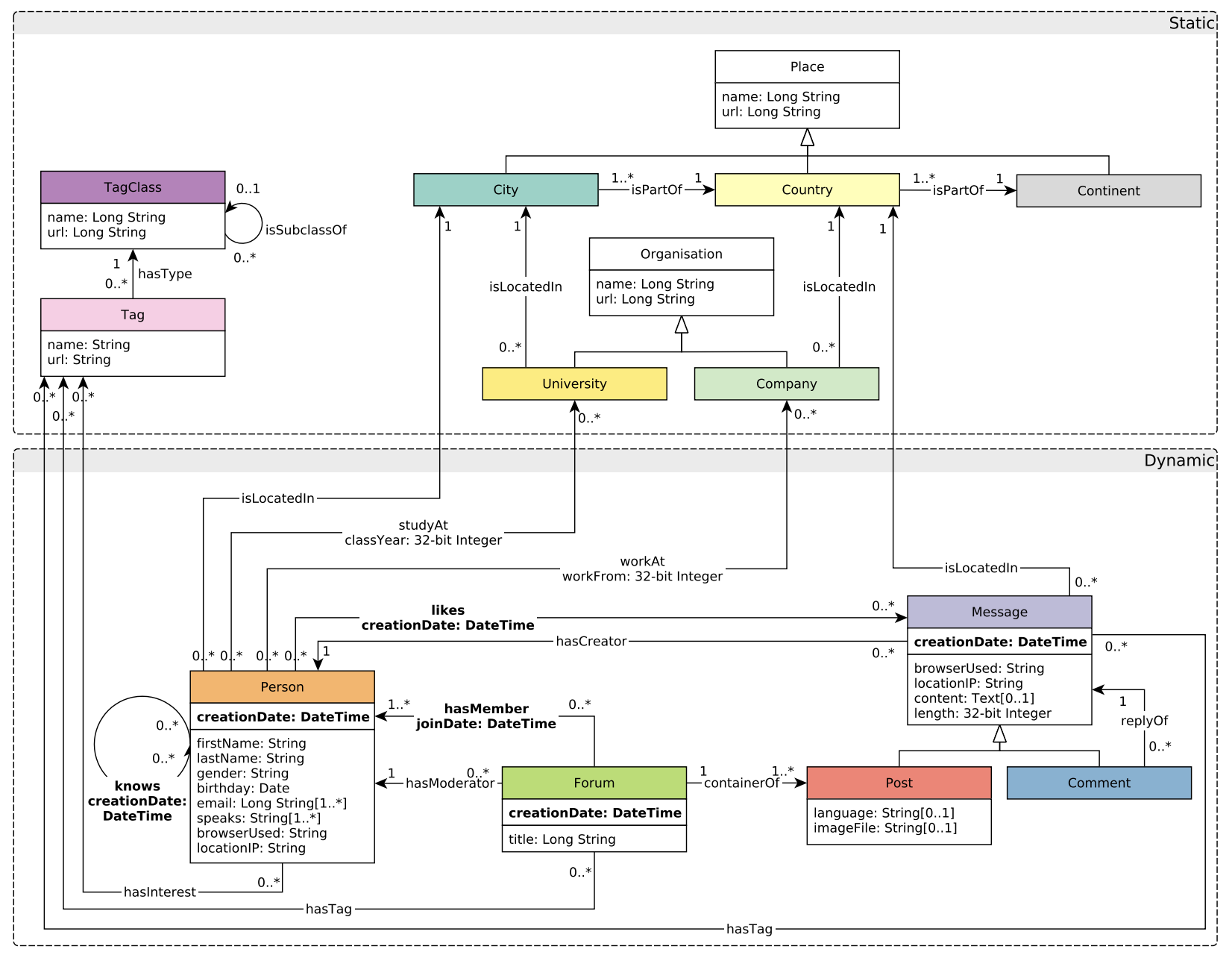
So there are a couple of things I already hate about this. The City, Country and Continent should be their own models, but for some reason they’ve grouped them up to Place and made a mess. The same is true for University and Company rolling up to Organisation with an “s” ’cause Europe that’s why. Same problem with Post and Comment both rolling up to Message. Nodes do not need to have more than one Label. It’s a terrible idea, just pick one and make life easy. Because of how they structured the data and the queries we don’t really get a choice, so we’ll use the top level model for all of these and save a “type” property for the second Label when we load it.
We have another problem. RageDB doesn’t have a Date or DateTime property type. Ok, adding that is going to be a lot of work. Haha, just kidding. I went to LuaRocks again, looked for a datetime library and found “date” which handles milliseconds as required by the LDBC specs. Just like before, I copied the lua file and added it to our requires.
lua.open_libraries(sol::lib::base, sol::lib::package, sol::lib::math, sol::lib::string, sol::lib::table, sol::lib::io, sol::lib::os);
lua.require_file("json", "./lua/json.lua");
lua.require_file("ftcsv", "./lua/ftcsv.lua");
lua.require_file("date", "./lua/date.lua");
There is one small problem however. The simplest way to create a date is date(number) but the “number” represents the number of seconds in Universal Coordinated Time between the specified value and the System epoch. So we would lose milliseconds if we stored it as an integer. We could store it as an integer times 1000 and divide by 1000 every time we retrieve it to get milliseconds, but nah, let’s just store it as a double with the fractional part representing milliseconds. So we just need a way to convert this date to a double. We can add that to the Lua code of the date file:
local SPAN_SECONDS = 62135596800 -- date.epoch():spanseconds() = 62135596800
function dobj:todouble()
return ((self.daynum*TICKSPERDAY + self.dayfrc)/TICKSPERSEC) - SPAN_SECONDS
end
Now we can do “date(person.creationDate):todouble()” to convert the string into a date and then into a double in our database and “date(value in database as a double)” to get the date back from the database as date if we need to do date arithmetic or format it in a certain way. We’ll also tweak the formatting a bit to show us the fractional seconds up to 3 decimal places for milliseconds. Alright with that in place, the Schema looks like this:
NodeTypeInsert("Forum")
NodePropertyTypeAdd("Forum", "title", "string")
NodePropertyTypeAdd("Forum", "creationDate", "double")
NodeTypeInsert("Message")
NodePropertyTypeAdd("Message", "creationDate", "double")
NodePropertyTypeAdd("Message", "locationIP", "string")
NodePropertyTypeAdd("Message", "browserUsed", "string")
NodePropertyTypeAdd("Message", "length", "integer")
NodePropertyTypeAdd("Message", "language", "string")
NodePropertyTypeAdd("Message", "content", "string")
NodePropertyTypeAdd("Message", "imageFile", "string")
NodePropertyTypeAdd("Message", "type", "string")
NodeTypeInsert("Organisation")
NodePropertyTypeAdd("Organisation", "name", "string")
NodePropertyTypeAdd("Organisation", "url", "string")
NodePropertyTypeAdd("Organisation", "type", "string")
NodeTypeInsert("Person")
NodePropertyTypeAdd("Person", "firstName", "string")
NodePropertyTypeAdd("Person", "lastName", "string")
NodePropertyTypeAdd("Person", "gender", "string")
NodePropertyTypeAdd("Person", "birthday", "string")
NodePropertyTypeAdd("Person", "creationDate", "double")
NodePropertyTypeAdd("Person", "locationIP", "string")
NodePropertyTypeAdd("Person", "browserUsed", "string")
NodePropertyTypeAdd("Person", "email", "string_list")
NodePropertyTypeAdd("Person", "speaks", "string_list")
NodeTypeInsert("Place")
NodePropertyTypeAdd("Place", "name", "string")
NodePropertyTypeAdd("Place", "url", "string")
NodePropertyTypeAdd("Place", "type", "string")
NodeTypeInsert("Tag")
NodePropertyTypeAdd("Tag", "name", "string")
NodePropertyTypeAdd("Tag", "url", "string")
NodeTypeInsert("TagClass")
NodePropertyTypeAdd("TagClass", "name", "string")
NodePropertyTypeAdd("TagClass", "url", "string")
RelationshipTypeInsert("CONTAINER_OF")
RelationshipTypeInsert("HAS_CREATOR")
RelationshipTypeInsert("HAS_INTEREST")
RelationshipTypeInsert("HAS_MEMBER")
RelationshipPropertyTypeAdd("HAS_MEMBER", "joinDate", "double")
RelationshipTypeInsert("HAS_MODERATOR")
RelationshipTypeInsert("HAS_TAG")
RelationshipTypeInsert("HAS_TYPE")
RelationshipTypeInsert("IS_LOCATED_IN")
RelationshipTypeInsert("IS_PART_OF")
RelationshipTypeInsert("IS_SUBCLASS_OF")
RelationshipTypeInsert("KNOWS")
RelationshipPropertyTypeAdd("KNOWS", "creationDate", "double")
RelationshipTypeInsert("LIKES")
RelationshipPropertyTypeAdd("LIKES", "creationDate", "double")
RelationshipTypeInsert("REPLY_OF")
RelationshipTypeInsert("STUDY_AT")
RelationshipPropertyTypeAdd("STUDY_AT", "classYear", "integer")
RelationshipTypeInsert("WORK_AT")
RelationshipPropertyTypeAdd("WORK_AT", "workFrom", "integer")
NodeTypesGet(), RelationshipTypesGet()
Now to import the Size 01 of the LDBC Social Network Benchmark Dataset. Let’s start with nodes which has a lot of properties. Notice the delimiter is a “|” instead of a comma like before. Here we are taking advantage of the newly added date feature to parse a string to a date and then convert it to a double.
for i, person in ftcsv.parseLine("/home/max/CLionProjects/ldbc/sn-sf1/person_0_0.csv", "|") do
NodeAdd("Person", person.id, "{\"firstName\":".."\""..person.firstName.."\",
\"lastName\":".."\""..person.lastName.."\",
\"gender\":".."\""..person.gender.."\",
\"birthday\":".."\""..person.birthday.."\",
\"creationDate\":"..date(person.creationDate):todouble()..",
\"locationIP\":".."\""..person.locationIP.."\",
\"browserUsed\":".."\""..person.browserUsed.."\"}")
end
Then we run into our the first problem we have to deal with. The Place csv file has the data for City, Country, and Continent. So we’ll take the “type” property in the csv and uppercase just the first character as our “type”. We really didn’t have to do this, but I wanted to show you some per row data manipulation.
local type = ""
for i, place in ftcsv.parseLine("/home/max/CLionProjects/ldbc/sn-sf1/place_0_0.csv", "|") do
type = place.type:sub(1,1):upper()..place.type:sub(2)
NodeAdd("Place", place.id, "{\"name\":".."\""..place.name.."\",
\"url\":".."\""..place.url.."\",
\"type\":".."\""..type.."\"}")
end
The rest of the nodes are pretty much a variation of one of the two ways above so I’m going to skip them. I’ll link the whole file here. Next up is our first relationship. Here we have the problem of a Comment and a Post both being “Message” so we’ll use that as our single label and the ids of the Comments and Posts as the keys to those nodes:
for i, replyOf in ftcsv.parseLine("/home/max/CLionProjects/ldbc/sn-sf1/comment_replyOf_post_0_0.csv", "|") do
RelationshipAdd("REPLY_OF", "Message", replyOf['Comment.id'], "Message", replyOf['Post.id'])
end
Most of it is pretty straight forward until you get to something like person_knows_person where the original file had a header with just “Person.id, Person.id” which doesn’t help us much. So I added a 1 and a 2 to make our life easier. They tell me this has been “fixed” in the next version of the benchmark.
for i, knows in ftcsv.parseLine("/home/max/CLionProjects/ldbc/sn-sf1/person_knows_person_0_0.csv", "|") do
RelationshipAdd("KNOWS", "Person", knows['Person1.id'], "Person", knows['Person2.id'], "{\"creationDate\":"..date(knows.creationDate):todouble().."}")
end
Then we get to the csv file with the list properties. In this case a person can have many emails, but instead of them being represented as email nodes, they want them represented as an array list of strings. Luckily the csv rows are in order by the “Person.id” that has them So what we will do is collect these multiple emails for each person and when we change the person.id we are dealing with we’ll save the list as the nodes “email” property and reinitialize our values. At the end of the file we will have one last person to handle, so we’ll take care of their email as well.
local person_id = 0
local next_id = 0
local count
local emails = {}
for i, person in ftcsv.parseLine("/home/max/CLionProjects/ldbc/sn-sf1/person_email_emailaddress_0_0.csv", "|") do
next_id = person['Person.id']
if (person_id == 0) then person_id = next_id end
if (next_id ~= person_id) then
NodePropertySet("Person", person_id, "email", emails)
count = #emails
for e=0, count do emails[e]=nil end
person_id = next_id
else
table.insert(emails, person['email'])
end
end
NodePropertySet("Person", next_id, "email", emails)
When I run it, it takes about 2 minutes and 40 seconds to import the files from the LDBC SNB Dataset Size 01 which add up to about 853MB on disk.
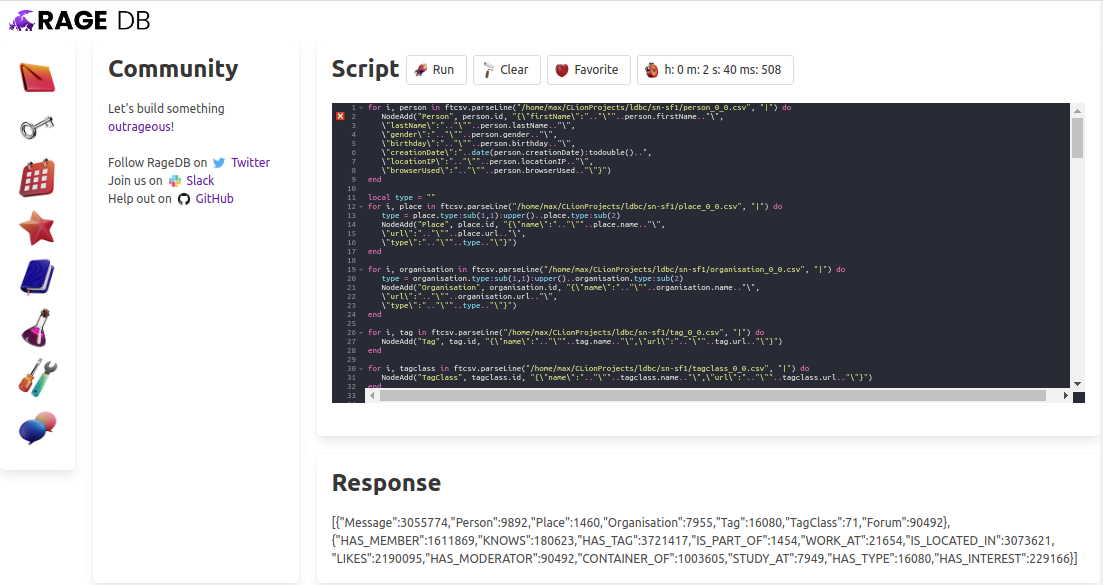
Let’s try the bigger dataset, the LDBC SNB Dataset Size 10 which is about 8.8 GB on disk:

That takes about 28 minutes, which is not bad. I can probably speed up the import by adding nodes and relationships in bulk a hundred or so at a time. That could be interesting to try along with building a bulk loader. I’ll save the writing of the LDBC SNB queries for another day. If you want to keep track of the progress on the queries, take a sneak peek by going to this repository on github. As always I’m looking for help, get an invite to the Slack. Follow me or the project on Twitter.
