
A few years ago I was really angry at the traversal performance I was getting on some slow query. So angry that I wrote a couple thousand lines of C code just to calm myself down. This is how Neo4c came about. This blog post explains the just of it. Neo4c was able to crank out 330 million traversals per second on a single core (because it was single threaded code) for a hand crafted “query” written in C using 32 bit ids (so limited to 4b nodes and 4b relationships). It wasn’t really a fair comparison to Neo4j, but it made me realize there was a lot of performance out there to be had. Let’s see where we are today.
In RageDB, we first have to create a Schema for our Data to fit into. In this case we have Person and Item nodes and LIKES relationships between them, so it looks like this:
NodeTypeInsert("Person")
NodePropertyTypeAdd("Person", "username", "string")
NodeTypeInsert("Item")
NodePropertyTypeAdd("Item", "name", "string")
RelationshipTypeInsert("LIKES")
RelationshipPropertyTypeAdd("LIKES", "weight", "double")
NodeTypesGet(), RelationshipTypesGet(), NodeTypeGet("Person"), NodeTypeGet("Item"), RelationshipTypeGet("LIKES")
Now that we have our schema, we need to create our data. So let’s do that with some Lua code. Here we’ll create 2000 Item nodes with ids of “itemX” where X is a number between 1 and 2000 and give them a name with the same value. We will also create 100k Person nodes with a “personY” id and a username property of the same value where Y is between 1 and 100000. Then for each Person node we’ll create a LIKES relationship to 100 random Item nodes with random weight values.
for i = 1,2000 do
NodeAdd("Item", "item"..i, "{\"name\":".."\"item"..i.."\"}")
end
for i = 1,100000 do
NodeAdd("Person", "person"..i, "{\"username\":".."\"person"..i.."\"}")
for j = 1,100 do
RelationshipAdd("LIKES", "Person", "person"..i, "Item", "item"..math.random(2000), "{\"weight\":"..10 * math.random().."}")
end
end
NodeTypesGetCountByType("Item"), NodeGet("Item", "item1"), NodeTypesGetCountByType("Person"), NodeGet("Person", "person1"), RelationshipTypesGetCountByType("LIKES")
It takes about 1 minute to create the 102k nodes and 10m relationships on a 4 core cloud instace. Let’s try running our query. It starts off by getting a count of all the Person nodes and randomly picking one of them. From there it gets all the LIKES relationships in the outgoing direction. At the end of these relationships are the Item nodes this one Person likes. So now we traverse all the incoming LIKES relationships for all the Item nodes to get all the Person nodes that liked these Items. Finally we traverse out the LIKES relationship one more time to get the Items these Person nodes also liked.
Basically this is a building block for a recommendation engine. We would group count the Item nodes found, remove those the original Person already LIKES, take the top 25 or so left and display them back to our user as Items they may also like. Let’s run the query. Notice the time next to the Clock:
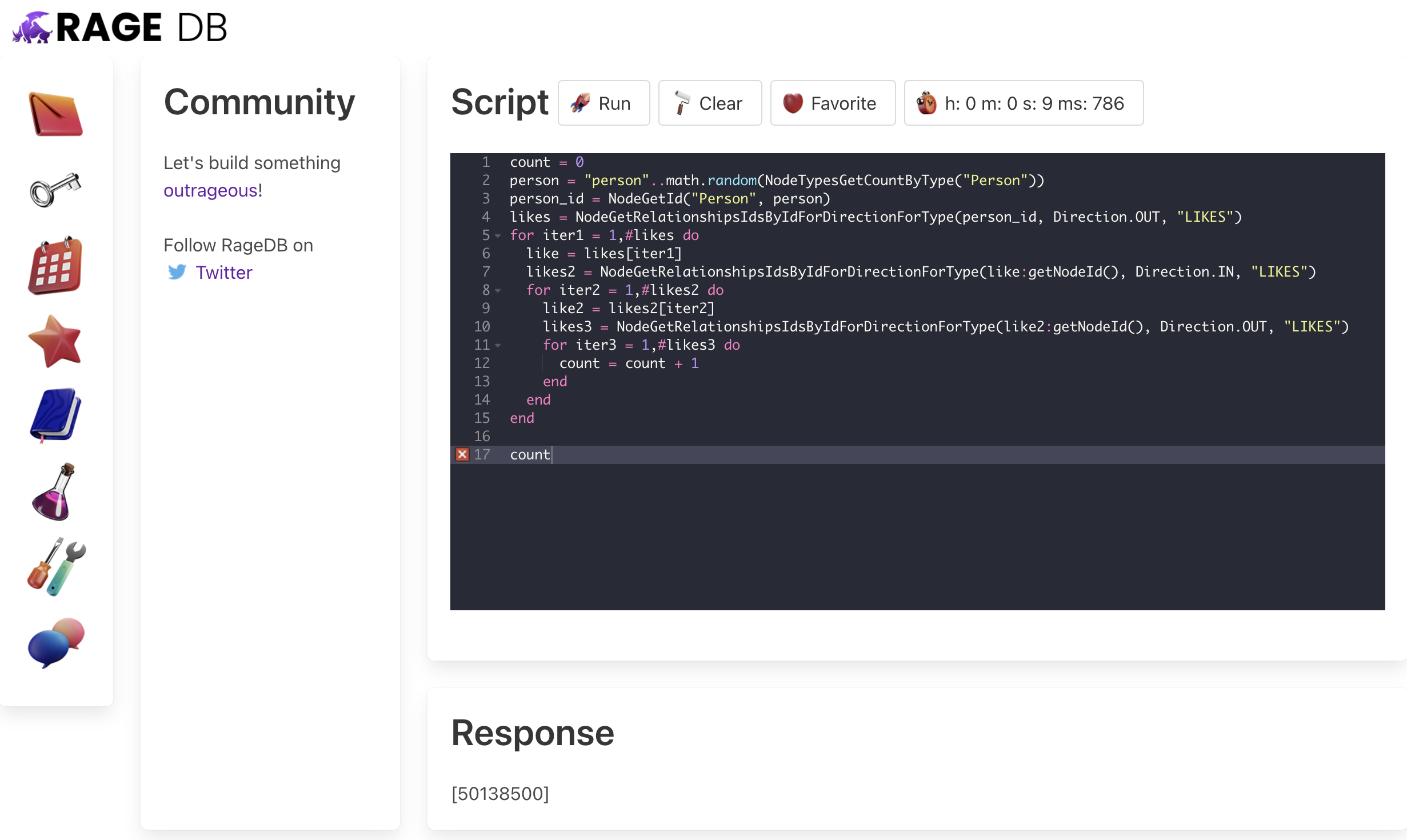
It took about 10 seconds on this r5.2xlarge AWS instance to return about 50 million relationships traversed. That gives us about 5 million relationships per second. That’s not great, but we have more than 1 core. So we can run multiple queries at the same time…. but it doesn’t help us in this case. 5 million divided by 4 cores is 1.5 million relationships traversed per second per core. Ouch.
So what’s the problem? We’re creating 500k individual requests from Lua to C++ as we traverse. We’re taking the hit on the method, we’re taking a hit on the transition from Lua to C++ and back, we’re creating a ton of work that does very little. Funny enough this is a complaint Peter Boncz had about Graph Databases back in 2018. Amongst many things, having a backend API that worked one object a a time and the failure to provide “bulk APIs”.

We are going to rectify this long standing mistake by adding Bulk methods to RageDB. We’ll add “LinksGetRelationships”, “LinksGetNeighbors”, “LinksGetRelationshipsIds” and their variants which will take a list of Links and then in bulk do their thing. The code for these things is pretty gnarly so those interested can take a look, I’ll spare the rest. So we’ll rewrite the query to use these methods, and now it looks like this:
local count = 0
local person = "person"..math.random(NodeTypesGetCountByType("Person"))
local person_id = NodeGetId("Person", person)
local liked_items = NodeGetRelationshipsIdsByIdForDirectionForType(person_id, Direction.OUT, "LIKES")
local item_likes = LinksGetRelationshipsIds(liked_items, Direction.IN, "LIKES")
for item, likes in pairs(item_likes) do
local other_person_likes = LinksGetRelationshipsIdsForDirectionForType(likes, Direction.OUT, "LIKES")
for other_person, likes2 in pairs(other_person_likes) do
for iter = 1,#likes2 do
count = count + 1
end
end
end
count
But the proof is in the pudding, so let’s run our query:

From about 10 seconds to about 1.4 seconds and change. That’s a huge drop… so we’re traversing at about 35 million relationships per second. Hold on a second, we have multiple cores remember? Let’s try running 4 at a time:
./wrk -c 4 -t 1 -d 60s -s bulk.lua --latency --timeout 60 http://x.x.x.x:7243
Running 1m test @ http://x.x.x.x:7243
1 threads and 4 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 2.80s 991.18ms 4.35s 67.86%
Req/Sec 5.34 5.83 20.00 93.44%
Latency Distribution
50% 2.16s
75% 4.17s
90% 4.28s
99% 4.35s
84 requests in 1.00m, 11.57KB read
Requests/sec: 1.40
Transfer/sec: 197.18BWould you look at that? We’re able to do about 1.4 requests per second, and each request is looking at 50 million relationships so that puts us at 70 million relationships on an r5.2xlarge. Since it has 4 cores, that’s about 17.5 million relationships per second per core. More than ten times better than what we started with.
How can we improve on this? Maybe we need to move more of the work to happen in the back-end and less on the front-end? Maybe we need a Traversal API? One that can do Bulk operations? Who knows. Want to help build RageDB? Get an invite to the Slack.

Inspiring work you are doing with RageDB! Great series of posts.
I thought I’d remind that after bulk comes… streaming. Streaming is the future, as you know.
single → bulk → streaming
It’s the natural way of things.
I can even imagine users having “standing queries”, where they continuously receive updates as they come in, when others update nodes that trigger the listening/standing query.
Not sure if this is merely a personal pet project of yours or if you want to create a full blown DB?
If the latter, I would recommend building the DB in Rust (for memory safety), if you are serious about putting RageDB into production. It’s the language for the next 40 years, as they say: https://www.youtube.com/watch?v=A3AdN7U24iU
But you might have too much C++ code at this point… so you will have to make the call if it is worth the switch.
Just found Materialize which seems to be precisely “standing queries” aka. “materialized views”. https://github.com/MaterializeInc/materialize