Yes, I’m slowly but surely getting on the generative AI bandwagon. The eye catching image above was generated in Lexica, it’s not perfect but our mind tricks us into accepting it. I am not a fan of asking these new AI systems questions and getting answers that only look like correct answers… but we’re not talking about that today. Instead we’ll be looking at improving the performance of RageDB using “perf” and “FlameGraphs“. Which really should have been called “FlameCharts” since it’s a chart not a graph but let’s not go there either.
Our last post was about a Triangle Count query. It referenced another blog post from Kuzu where they explained their use of a Multi Way Join Algorithm to count 41 million triangles in 1.62 seconds. Using only binary joins it would take them 51.17 seconds to achieve the same result. My attempts to run the query using Lua on Rage landed at 9.5 seconds one node at a time and 5.6 seconds using the batch queries. So that got me thinking, how about Neo4j?
In this blog post, KuzuDB creator Semih Salihoğlu makes the case that graph databases need new join algorithms. If you’ve read the blog post and came away still a bit confused then look at the image above. This image shows what happens when you try to join 3 tables. The problem is that traditionally databases have used binary joins (two tables at a time) to execute queries. The intermediate result build up of these joins can get massive and eat a ton of memory and processing power. The more binary joins you have, the worse it gets.
How is the Graph Database category supposed to grow when vendors keep spouting off complete bullshit? I wrote a bit about the ridiculous benchmark Memgraph published last month hoping they would do the right thing and make an attempt at a real analysis. Instead these clowns put it on a banner on top of their home page. So let’s tear into it.
At first I considered replicating it using their own repository, but it’s about 2000 lines of Python and I don’t know Python. Worse still, the work is under a “Business Source License” which states:
In Cypher, we call any unbounded star query a “Death Star” query. You’ll recognize it if you see a star between two brackets in any part of the query:
-[*]-
the deadly pattern of a death star query
The “star” in Cypher means “keep going”, and when it is not bound by a path length -[*..3]- or relationship type(s) -[:KNOWS|FRIENDS*]- it tends to blow up Alderaaning servers. It’s hard to find a valid reason for this query, but its less deadly cousins are very important in graph workloads.
For example when looking at fraud, we may start with a Customer node and ask, which known Fraudulent nodes are within 4 hops away? A Customer HAS an Account that was ACCESSED by a Device that ACCESSED another Account that BELONGS_TO a known Fraudster. A Customer HAS a mailing Address that is very SIMILAR to an Address that BELONGS_TO a Business that is partially OWNED by a known Fraudster. These are just two out of many valid patterns in our graph. Graph databases were designed to handle these kind of queries. The trick is thatevery node KNOWS its relationships, every node KNOWS how it is connected.
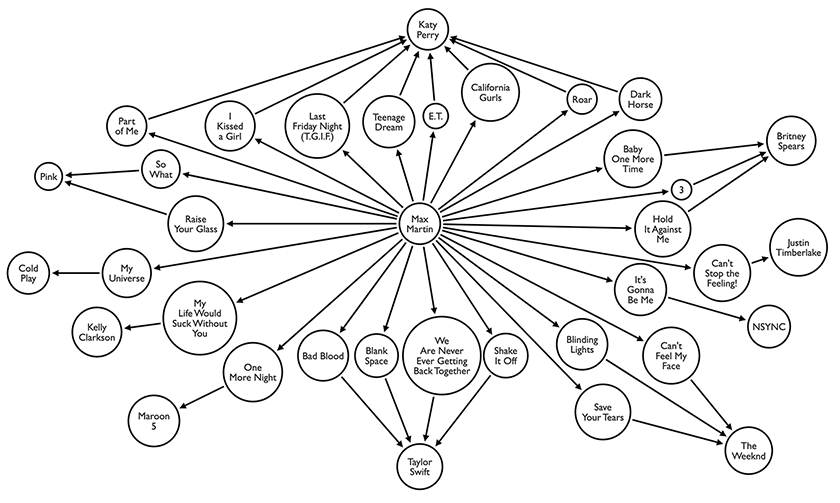
Some of the most beloved songs by main stream artists were written by Max Martin. The song “Baby One More Time” came out in 1999 and sold over 10m copies. It propelled Britney Spears into pop stardom. If we were to look at the graph above, with Max Martin in the center, then one hop away are the songs he wrote which would become #1s on the Billboards Hot 100. Two hops away are the Artists that performed those #1 songs. It is beyond question that Max Martin knows how to write good pop songs. I wish I had his talent. I only know how to write half way decent KHop implementations.
I tend to only find time to work on RageDB at night. Staring at code in CLion using the “Darcula” theme works great. But like a vampire exposed to direct sunlight, things go horribly wrong when I try to test what I am working on using the RageDB front-end. You see, besides the code-editor, the rest of the interface is very bright. Blindingly so:
I’m still trying to figure out the right look for the language folks will use to talk to RageDB. Instead of waiting until I have it figured out, I decided I should write all the queries for the LDBC SNB Benchmark to prepare for a full run in the next few months. Now that we added “stored procedures” to RageDB, the benchmark code is trivial. I send a post request to the Lua url with the name of the query plus any parameters it may need which are in a CSV file. Here is Short Query 4 for example and they all look like this besides the different parameters:
I was watching The Marvelous Mrs. Maisel and one of the more jarring issues of the first two episodes is that Midge keeps getting arrested for the things she says. It reminded me of the song “Me So Horny” from 2 Live Crew that landed the hip hop group in jail charged with obscenity. Record store owners were getting arrested for selling CDs to undercover cops. How insane does that all sound? But it strikes the point that language matters. The things we say and how we say them are powerful. They convey meaning and emotion, language can be pleasant or it can be foul.
I’ve written a ton of SQL and Cypher queries over the last 20 years…and I’ve rewritten those queries as stored procedures more times than I can count. The issues with the expressivity of the query language and the ability of the query optimizer to “do the right thing” have been around longer than my career. I’ve written about this problem before. I went so far as to completely give up. In RageDB I let the developer write the query in a programming language directly. Skipping the “middle man” and letting the user be the query optimizer. Because in the end… this is what always happens. Well almost always.