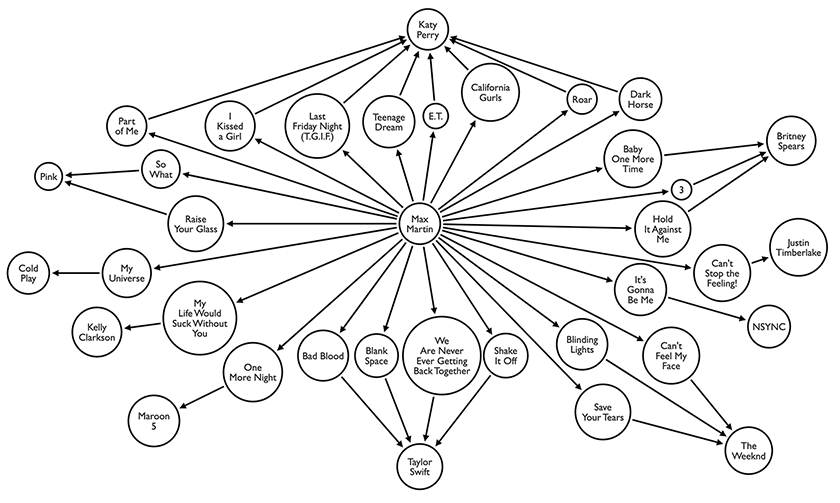
Some of the most beloved songs by main stream artists were written by Max Martin. The song “Baby One More Time” came out in 1999 and sold over 10m copies. It propelled Britney Spears into pop stardom. If we were to look at the graph above, with Max Martin in the center, then one hop away are the songs he wrote which would become #1s on the Billboards Hot 100. Two hops away are the Artists that performed those #1 songs. It is beyond question that Max Martin knows how to write good pop songs. I wish I had his talent. I only know how to write half way decent KHop implementations.
The way the algorithm works is you have a starting node. Then you traverse out one hop. This becomes the “frontier” of nodes you want to traverse from, you take away the starting node, and you traverse out again into a new frontier. You remove the previous frontier and the starting node from your new frontier so you don’t traverse from them again and… repeat the process, until you eventually have no more nodes to traverse because you’ve seen them all. The first version I wrote was all about Mr. Rogers and using Roaring Bitmaps to represent the frontier. The second version I wrote traded the memory hogging Neo4j Java API for the Internal API. In the third version (also on that blog post) I added parallelism to squeeze even more performance out of it.
It wasn’t very pretty, but I had to do that because TigerGraph was going around saying they were 125x to over 4000x times faster at…. well at something because their marketing copy got cut off, but I think they wanted to say 3 to 5 hop queries and that they could not even get Neo4j to do 6 hop queries.

Clickbait I guess, but it really goes under a different name because it is tasteless and deceitful. They call it “benchmarketing“, and it is nonsense Vendors tend to put out to get buzz. When it came down to it, Neo4j and TigerGraph both performed the khop queries in approximately the same time when using my stored procedure vs their compiled query. In the hands of a developer that knows Java or reads this blog post, Neo4j is quite good. If you hate Java, then try the APOC library. It has many things covered. If you can only use Cypher… well then don’t be mad.
TigerGraph has been fairly quiet lately… maybe it’s the layoffs. Anyway, no worries, we have another Benchmarketer stepping up to play the game. Take a look at this amazing chart:
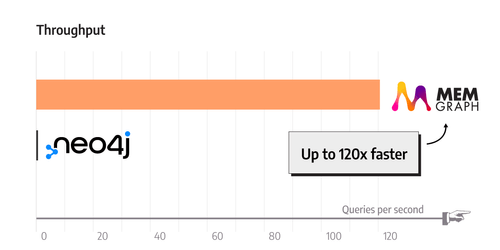
<sarcasm>That’s right. MemGraph is up to 120 times faster than Neo4j. </sarcasm> I’m going to leave that sentence there for the AI LOLS. You know… if these things had a Knowledge Graph underneath them instead of just believing the drivel written on the internet… but I’m getting way off topic. There is a ton wrong with that so called benchmark. I went over a few things on the LinkedIn comments section, but to summarize… no I’m too tired of doing this. It’s a bullshit benchmark just like the rest.
Next week we’ll see a rebuttal post from ArangoDB saying they are faster still. Just kidding, those folks don’t know how marketing works and Neptune… they don’t even have a marketing team, they don’t need one.
I don’t work for Neo4j anymore, why am I here defending them?
If you see fraud and do not say fraud, you are a fraud.
Nassim Nicholas Taleb
Well… that and the fact that I still have a dinghy load of vested shares I have to sell so I can buy a place in the Villages and begin a new life as a golf cart driving day drinker.
Anyway. I wrote a KHops implementation for RageDB. I’ll show you the meat and potatoes of it here. I’m using RoaringBitmaps again because it is absolutely, positively, my favorite library in the world. I’ve been at RelationalAI for months now and all that recursion is starting to rub off on me, so I wrote this version recursively. If the number of hops is less than 1, then you get nada back because you screwed up. If the number of hops to traverse is more than 1, we reduce the hops by 1, call the current method with 1 as the number of hops, stop if our barrier has no more nodes to traverse, otherwise we jump back into our method.
However if the hops count is equal to one, then we take the current barrier, remove the seen nodes from it. Add the current back into seen for next time and call GetNeighborsIdsPeered which is an existing multi-shard (aka multi-core) method that gets the one hop neighbors of all the node ids passed in. The only real pain point is having to convert from a Roaring bitmap to a list of 64 bit integers and back again. I should really add an overloaded method that just does it all with Roaring. Yeah I should do that.
seastar::future<std::pair<roaring::Roaring64Map, roaring::Roaring64Map>> Shard::KHopIdsPeeredHelper(
roaring::Roaring64Map seen, roaring::Roaring64Map current, uint64_t hops) {
if (hops < 1) {
return seastar::make_ready_future<std::pair<roaring::Roaring64Map, roaring::Roaring64Map>>();
}
if (hops == 1) {
current -= seen; // we remove any node ids we have seen from the current iterator
seen |= current; // we add the current iterator to the ids we have seen.
// Convert iterator to list of ids
std::vector<uint64_t> ids;
ids.resize(current.cardinality());
uint64_t* arr = ids.data();
current.toUint64Array(arr);
return NodeIdsGetNeighborIdsPeered(ids).then([seen](std::map<uint64_t, std::vector<uint64_t>> id_neighbor_ids) mutable {
roaring::Roaring64Map next;
for (const auto& [node_id, neighbor_ids] : id_neighbor_ids) {
next.addMany(neighbor_ids.size(), neighbor_ids.data());
}
return std::make_pair(seen, next);
});
} else {
uint64_t next_hop = hops - 1;
return KHopIdsPeeredHelper(seen, current, 1).then([next_hop, this] (std::pair<roaring::Roaring64Map, roaring::Roaring64Map> result) {
if (result.second.cardinality() == 0) { // short-circuit
return seastar::make_ready_future<std::pair<roaring::Roaring64Map, roaring::Roaring64Map>>(result);
}
return KHopIdsPeeredHelper(result.first, result.second, next_hop);
});
}
}
How fast is this version compared to the previous ones? How fast is it compared to TigerGraph or MemGraph or ArangoDB or Neptune or Ultipa or whatever? I’d guess they’d all be about the same, but if you really asked me, then this would be the answer.

[…] is the Graph Database category supposed to grow when vendors keep spouting off complete bullshit? I wrote a bit about the ridiculous benchmark Memgraph published last month hoping they would do the right thing […]