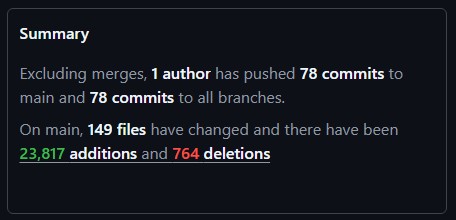
If we are able to build mountains of code in days instead of months. Then we don’t need 100 developers per app, but just a handful…. say 7. If we only need those 7, then we only need to buy 7 AI subscriptions. If we only buy 7 subscriptions instead of 100, then we pay the AI companies a tiny amount of money, so they don’t need all those chips, which means they don’t buy from Nvidia and Micron and friends. Right?
So 93 people are out of a job and valuations collapse? Please tell me I’m wrong.
By the end of this blog post, you are going to experience two epiphanies about databases. However, you are going to have to do a little more work than just read. You are going to have to stop and actually think about what you’re reading. I promise it will be worth it. Let’s go!
A relational database has tables with columns of numbers we refer to as keys. User_ID 1, 2, 3, Place_ID 1, 2, 3, Book_ID 1, 2, 3… and so on. These are numbers that are hopefully the same on some other column on some other table. The database itself has absolutely no idea how things are connected until you query it and you tell it exactly how to use these columns to join the tables together. Think about that.
Now, a graph database has explicit relationships. You never have to ask it to search for some id in some column. It knows how things are connected. Tell me about yourself Node A. I am 5’11” and 200 lbs, I have brown eyes… Now tell me how you are related to the world. These are my Friends, these are the Companies I have worked at, these are the Skills I have learned, these are the Things I like. How are you and this other noted related? We are 4 hops away through x, y an z nodes.
A couple of weeks ago, Helene looked at me hunched over on my computer and said “You’re working like a caveman”. She is a bigwig in her company and her team does things I can’t share that we will call “AI stuff”. What she meant was that I was still lovingly hand crafting every single line of code I was writing. I was using zero AI. I was living under a rock. In my defense, I’m 47 years old, which might as well be considered “dead” in developer age. My age group is supposed to be in the “Late Majority” or “Laggards” category of the innovation adoption curve. Her team is building entire applications in weeks using AI and I am lucky to get a small feature a day. She told me to take my old RageDB project and use it to learn.
If you’re a long time reader, you know I have a thing against declarative languages. I find them all liars, so RageDB never got Cypher or some made up graph query language. Instead I was using Lua to create what boils down to “query plans” by hand as my way of talking to it. It’s cool, but realistically nobody is going to do that. So I decided to let the AI do something I would have hated doing (and probably never done) which is write a GQL interface for RageDB.
I fired up Google Antigravity, and pointed it to my ragedb repository. I told it to look at other GQL implementations by Kuzu, Ladybug, FroGQL, Nebula Graph, Ultipa. I told it to look at their documentation, their test suites and then add GQL to RageDB. Twenty Three Thousand Lines of code in a flash. That flash was a few evening hours over a few days, but what it was able to do in a short time would have taken me ages. Maybe 9 months if I’m being generous, but really an infinite amount of time since I don’t have much expertise in grammars, lexers and implementing query optimizers. I know how to use mechanical sympathy to build query plans by hand, been doing that for ever, but not automating that process.
While I was there I told it to implement the type checker from FrogQL, implement the factorizer from Kuzu, implement the query cache from Neo4j, implement the documentation from Nebula, implement query plan optimizations from everybody. I told it to build an optimized K-Hop counts function. I told it to build a shortest path and a weighted shortest path function. I told it to build an exact index, and a full text search index. These features would normally take a team months and months to do, and it did them all like if it was nothing. I can imagine the blood, sweat and tears any software team would have suffered doing this work, and to AI, it was child’s play. If you can think it, it can build it…fast.
Dump your two week sprints, dump your prioritization meetings, dump your agile coaches and scrum teams. Zed Shaw was right all along. The software development world has changed. I get it now.
Everyone expects AI prices to go down in the long term. But in the short term, we have three things going on. Token prices keep dropping, hurray for that. Subscription fees are going up and dumping their all you can eat plans for volume based pricing. There more you use, the more you pay. I guess that’s fair. Third, hardware component pricing is going up and big companies are borrowing billions to build the greatest and latest AI data centers. What’s going on? Are we in the pets.com era of selling $40 dollars worth of dog food for $20 bucks and making it up in volume? The real question is, how do we close this giant chasm of a value gap?
Molham Aref argues that enterprises must make agents smarter and cheaper. We have to solve two problems at the same time: making agents smart enough to handle real business decisions, and ensuring they are cost-effective enough to scale enterprise-wide. It sounds simple enough on the surface, but… it’s not. I’m going to talk about one of the ways we are doing that. But before I start, about six months ago, Greg Diamos and Naila Farooqui at RelationalAI wrote a blog post “Introducing Superalignment for Relational Databases“. If you haven’t read it yet, please take the time to do it now or you may be a little lost on what follows. There is a line in there people sometimes overlook, even thought it’s literally highlighted in bold:
One of the things that made me fall head over heals for Neo4j so many years ago was just how extensible it was. If the database engineering team was busy rebuilding the clustering feature for the third time and didn’t have time to take care of my feature requests… I could just add them myself. Not to Neo4j directly, no that would have been a horrible mess. Instead I could add any feature I wanted as an “Unmanaged Extension”. Later on they became Cypher Stored Procedures, but it was basically the same thing. You had access to the top level Java API that dealt with Nodes and Edges. You could use the Traversal API that dealt with Paths….and if you were feeling extra spicy that day you could go down to the Storage API that dealt with Cursors over raw bytes.
I had spent prior jobs working with Oracle and Microsoft SQL Server so I never had that kind of power and freedom before. Well, it took a long time, but that power has come to MySQL in the form of a change tracking fork called VillageSQL. There are already a bunch of extensions that add UUID, Network Address custom types, Cryptographic Functions, Multi-Dimensional Geometry as well as AI helpers. So of course I had to try it out. I decided to add an extension for one of my other great loves, the Roaring Bitmap data structure.
About eight years ago, I wrote a little blog post on dynamic decision trees. If you have the time, go back and read that and the follow up posts on the subject. If not, I’ll summarize. Instead of building a Rules Engine to make decisions, I built a dynamic traverser that evaluates logic on the fly. This enables us to change how the decisions are made any time. We can also version the trees as we change it and create completely new trees for any complex decision making. If we don’t have enough information to get to a conclusion, it doesn’t give up or make something up, instead it asks us a question we must answer to continue down the path.
I bring up this relic from the past because I’m still trying to wrap my head around the value of “Context Graphs”. Which are supposed to be graphs that capture the how, when and why decisions were made instead of what decision was made. The idea being to capture “decision traces” which then allow an AI agent to see precedents (how similar problems were solved) and apply those same rules to new situations. The first decision traces would be made by people, and then the agents could learn and take it from there. So every time you want a decision answered, your agents would read all the previous decisions, analyze them, and make a new decision. But why? If we made a policy change, would the AI agents now ignore all the previous decisions and utilize the new policy? Would we have to repopulate the graph with human made decisions following the new policy so the agent understood there was a change?
Yes, I’m slowly but surely getting on the generative AI bandwagon. The eye catching image above was generated in Lexica, it’s not perfect but our mind tricks us into accepting it. I am not a fan of asking these new AI systems questions and getting answers that only look like correct answers… but we’re not talking about that today. Instead we’ll be looking at improving the performance of RageDB using “perf” and “FlameGraphs“. Which really should have been called “FlameCharts” since it’s a chart not a graph but let’s not go there either.
Our last post was about a Triangle Count query. It referenced another blog post from Kuzu where they explained their use of a Multi Way Join Algorithm to count 41 million triangles in 1.62 seconds. Using only binary joins it would take them 51.17 seconds to achieve the same result. My attempts to run the query using Lua on Rage landed at 9.5 seconds one node at a time and 5.6 seconds using the batch queries. So that got me thinking, how about Neo4j?
In this blog post, KuzuDB creator Semih Salihoğlu makes the case that graph databases need new join algorithms. If you’ve read the blog post and came away still a bit confused then look at the image above. This image shows what happens when you try to join 3 tables. The problem is that traditionally databases have used binary joins (two tables at a time) to execute queries. The intermediate result build up of these joins can get massive and eat a ton of memory and processing power. The more binary joins you have, the worse it gets.
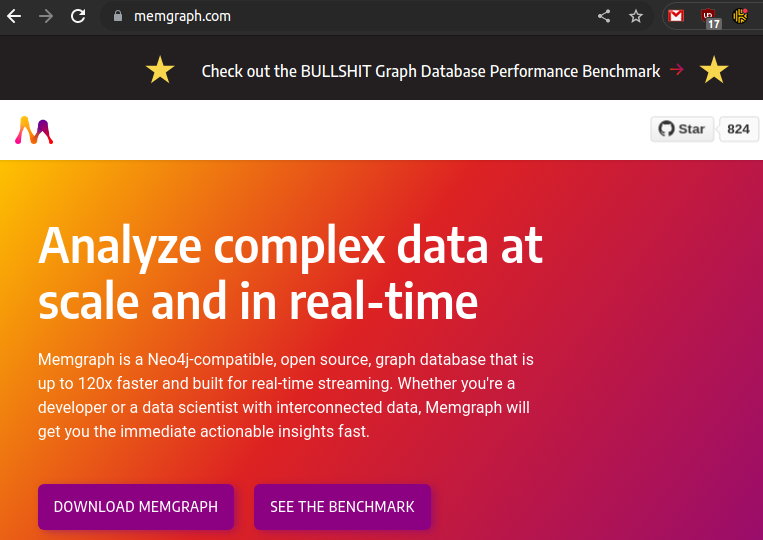
How is the Graph Database category supposed to grow when vendors keep spouting off complete bullshit? I wrote a bit about the ridiculous benchmark Memgraph published last month hoping they would do the right thing and make an attempt at a real analysis. Instead these clowns put it on a banner on top of their home page. So let’s tear into it.
At first I considered replicating it using their own repository, but it’s about 2000 lines of Python and I don’t know Python. Worse still, the work is under a “Business Source License” which states: