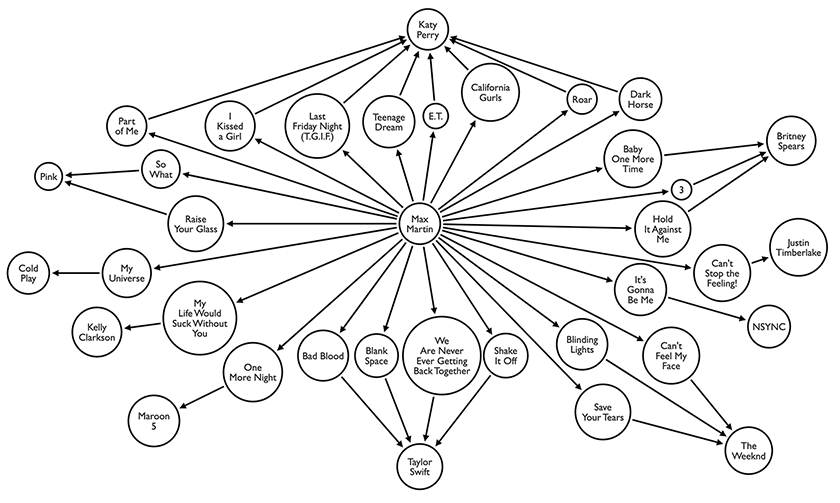
About eight years ago, I wrote a little blog post on dynamic decision trees. If you have the time, go back and read that and the follow up posts on the subject. If not, I’ll summarize. Instead of building a Rules Engine to make decisions, I built a dynamic traverser that evaluates logic on the fly. This enables us to change how the decisions are made any time. We can also version the trees as we change it and create completely new trees for any complex decision making. If we don’t have enough information to get to a conclusion, it doesn’t give up or make something up, instead it asks us a question we must answer to continue down the path.
I bring up this relic from the past because I’m still trying to wrap my head around the value of “Context Graphs”. Which are supposed to be graphs that capture the how, when and why decisions were made instead of what decision was made. The idea being to capture “decision traces” which then allow an AI agent to see precedents (how similar problems were solved) and apply those same rules to new situations. The first decision traces would be made by people, and then the agents could learn and take it from there. So every time you want a decision answered, your agents would read all the previous decisions, analyze them, and make a new decision. But why? If we made a policy change, would the AI agents now ignore all the previous decisions and utilize the new policy? Would we have to repopulate the graph with human made decisions following the new policy so the agent understood there was a change?
Continue reading