If we are able to build mountains of code in days instead of months. Then we don’t need 100 developers per app, but just a handful…. say 7. If we only need those 7, then we only need to buy 7 AI subscriptions. If we only buy 7 subscriptions instead of 100, then we pay the AI companies a tiny amount of money, so they don’t need all those chips, which means they don’t buy from Nvidia and Micron and friends. Right?
So 93 people are out of a job and valuations collapse? Please tell me I’m wrong.
A couple of weeks ago, Helene looked at me hunched over on my computer and said “You’re working like a caveman”. She is a bigwig in her company and her team does things I can’t share that we will call “AI stuff”. What she meant was that I was still lovingly hand crafting every single line of code I was writing. I was using zero AI. I was living under a rock. In my defense, I’m 47 years old, which might as well be considered “dead” in developer age. My age group is supposed to be in the “Late Majority” or “Laggards” category of the innovation adoption curve. Her team is building entire applications in weeks using AI and I am lucky to get a small feature a day. She told me to take my old RageDB project and use it to learn.
If you’re a long time reader, you know I have a thing against declarative languages. I find them all liars, so RageDB never got Cypher or some made up graph query language. Instead I was using Lua to create what boils down to “query plans” by hand as my way of talking to it. It’s cool, but realistically nobody is going to do that. So I decided to let the AI do something I would have hated doing (and probably never done) which is write a GQL interface for RageDB.
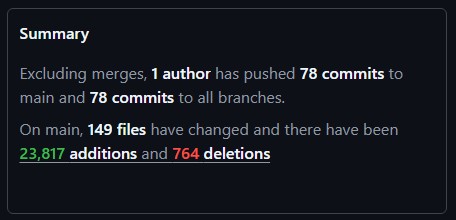
I fired up Google Antigravity, and pointed it to my ragedb repository. I told it to look at other GQL implementations by Kuzu, Ladybug, FroGQL, Nebula Graph, Ultipa. I told it to look at their documentation, their test suites and then add GQL to RageDB. Twenty Three Thousand Lines of code in a flash. That flash was a few evening hours over a few days, but what it was able to do in a short time would have taken me ages. Maybe 9 months if I’m being generous, but really an infinite amount of time since I don’t have much expertise in grammars, lexers and implementing query optimizers. I know how to use mechanical sympathy to build query plans by hand, been doing that for ever, but not automating that process.
While I was there I told it to implement the type checker from FrogQL, implement the factorizer from Kuzu, implement the query cache from Neo4j, implement the documentation from Nebula, implement query plan optimizations from everybody. I told it to build an optimized K-Hop counts function. I told it to build a shortest path and a weighted shortest path function. I told it to build an exact index, and a full text search index. These features would normally take a team months and months to do, and it did them all like if it was nothing. I can imagine the blood, sweat and tears any software team would have suffered doing this work, and to AI, it was child’s play. If you can think it, it can build it…fast.
Dump your two week sprints, dump your prioritization meetings, dump your agile coaches and scrum teams. Zed Shaw was right all along. The software development world has changed. I get it now.
Everyone expects AI prices to go down in the long term. But in the short term, we have three things going on. Token prices keep dropping, hurray for that. Subscription fees are going up and dumping their all you can eat plans for volume based pricing. There more you use, the more you pay. I guess that’s fair. Third, hardware component pricing is going up and big companies are borrowing billions to build the greatest and latest AI data centers. What’s going on? Are we in the pets.com era of selling $40 dollars worth of dog food for $20 bucks and making it up in volume? The real question is, how do we close this giant chasm of a value gap?
Molham Aref argues that enterprises must make agents smarter and cheaper. We have to solve two problems at the same time: making agents smart enough to handle real business decisions, and ensuring they are cost-effective enough to scale enterprise-wide. It sounds simple enough on the surface, but… it’s not. I’m going to talk about one of the ways we are doing that. But before I start, about six months ago, Greg Diamos and Naila Farooqui at RelationalAI wrote a blog post “Introducing Superalignment for Relational Databases“. If you haven’t read it yet, please take the time to do it now or you may be a little lost on what follows. There is a line in there people sometimes overlook, even thought it’s literally highlighted in bold:
Yes, I’m slowly but surely getting on the generative AI bandwagon. The eye catching image above was generated in Lexica, it’s not perfect but our mind tricks us into accepting it. I am not a fan of asking these new AI systems questions and getting answers that only look like correct answers… but we’re not talking about that today. Instead we’ll be looking at improving the performance of RageDB using “perf” and “FlameGraphs“. Which really should have been called “FlameCharts” since it’s a chart not a graph but let’s not go there either.
Our last post was about a Triangle Count query. It referenced another blog post from Kuzu where they explained their use of a Multi Way Join Algorithm to count 41 million triangles in 1.62 seconds. Using only binary joins it would take them 51.17 seconds to achieve the same result. My attempts to run the query using Lua on Rage landed at 9.5 seconds one node at a time and 5.6 seconds using the batch queries. So that got me thinking, how about Neo4j?
In this blog post, KuzuDB creator Semih Salihoğlu makes the case that graph databases need new join algorithms. If you’ve read the blog post and came away still a bit confused then look at the image above. This image shows what happens when you try to join 3 tables. The problem is that traditionally databases have used binary joins (two tables at a time) to execute queries. The intermediate result build up of these joins can get massive and eat a ton of memory and processing power. The more binary joins you have, the worse it gets.
How is the Graph Database category supposed to grow when vendors keep spouting off complete bullshit? I wrote a bit about the ridiculous benchmark Memgraph published last month hoping they would do the right thing and make an attempt at a real analysis. Instead these clowns put it on a banner on top of their home page. So let’s tear into it.
At first I considered replicating it using their own repository, but it’s about 2000 lines of Python and I don’t know Python. Worse still, the work is under a “Business Source License” which states:
In Cypher, we call any unbounded star query a “Death Star” query. You’ll recognize it if you see a star between two brackets in any part of the query:
-[*]-
the deadly pattern of a death star query
The “star” in Cypher means “keep going”, and when it is not bound by a path length -[*..3]- or relationship type(s) -[:KNOWS|FRIENDS*]- it tends to blow up Alderaaning servers. It’s hard to find a valid reason for this query, but its less deadly cousins are very important in graph workloads.
For example when looking at fraud, we may start with a Customer node and ask, which known Fraudulent nodes are within 4 hops away? A Customer HAS an Account that was ACCESSED by a Device that ACCESSED another Account that BELONGS_TO a known Fraudster. A Customer HAS a mailing Address that is very SIMILAR to an Address that BELONGS_TO a Business that is partially OWNED by a known Fraudster. These are just two out of many valid patterns in our graph. Graph databases were designed to handle these kind of queries. The trick is thatevery node KNOWS its relationships, every node KNOWS how it is connected.
I tend to only find time to work on RageDB at night. Staring at code in CLion using the “Darcula” theme works great. But like a vampire exposed to direct sunlight, things go horribly wrong when I try to test what I am working on using the RageDB front-end. You see, besides the code-editor, the rest of the interface is very bright. Blindingly so:
I’m still trying to figure out the right look for the language folks will use to talk to RageDB. Instead of waiting until I have it figured out, I decided I should write all the queries for the LDBC SNB Benchmark to prepare for a full run in the next few months. Now that we added “stored procedures” to RageDB, the benchmark code is trivial. I send a post request to the Lua url with the name of the query plus any parameters it may need which are in a CSV file. Here is Short Query 4 for example and they all look like this besides the different parameters: