
In this blog post, KuzuDB creator Semih Salihoğlu makes the case that graph databases need new join algorithms. If you’ve read the blog post and came away still a bit confused then look at the image above. This image shows what happens when you try to join 3 tables. The problem is that traditionally databases have used binary joins (two tables at a time) to execute queries. The intermediate result build up of these joins can get massive and eat a ton of memory and processing power. The more binary joins you have, the worse it gets.
In a worst case optimal join, we join more than 2 tables at a time. Follow along the image below for an example of joining 3 tables. We start at Table 1 and seek the highest starting value of the 3 tables which in this case is “2” from Table 3. We don’t find “2”, but reach “3” instead which is now our new minimum. We seek “3” in Table 2 and don’t find it, we reach “6” instead. Which is now our new minimum, we seek “6” on Table 3 and find “8” instead… we seek “8” in Table 1 and find it, and seek “8” again in Table 2 and find it again! This means all 3 tables have an “8” which we emit to our output. We continue to the next value in Table 3 which is “10” and seek it on Table 1, but find “11” instead. We seek “11” on Table 2 but reach the end of the table so we end our query since there can be no more matches regardless of what is on Tables 1 and 3. Just look at the picture for a minute or 3 and it will click. I promise.

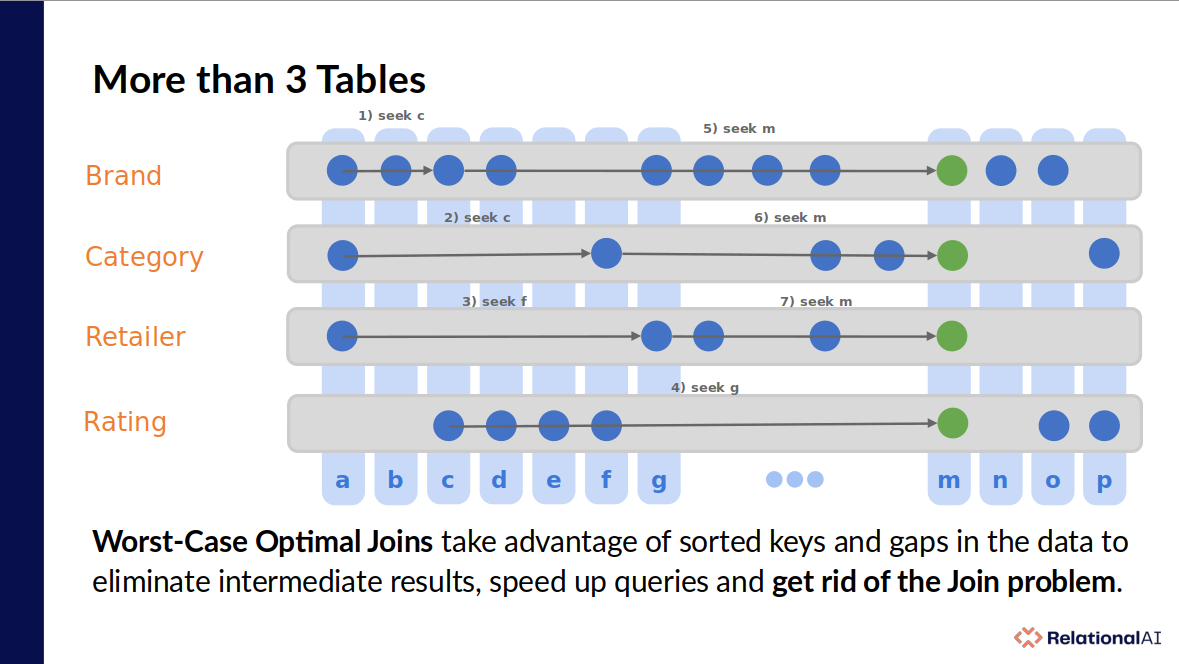
What about more than 3 tables? I said earlier that the more binary joins, the worse the “join problem” can get. In a worst case optimal join, the opposite is true. The more joins you have the better things can get because you’ll often skip over large parts of multiple tables which speeds up your queries instead of slowing them down. At RelationalAI we take full advantage of this feature by using many “thin” tables in our system. Take a look at this presentation for more details.
In their post, Semih presents an example “triangle” query where Nodes A links to many Nodes B, each of which link to many Nodes C which must link back to Nodes A. In traditional OLTP workloads you would tend to start and end with a single Node A, but in this OLAP style workload we want to get the count of all the triangles in our database. To those of you familiar with Cypher, the query looks like this:
// Uses WCOJ
MATCH (a:Page)-[e1:Links]->(b:Page)-[e2:Links]->(c:Page)-[e3:Links]->(a)
RETURN count(*)
The data loaded has 685K nodes connected together with 7.6M relationships and the result of that query is 41,421,291…that’s 41 million and almost a half triangles which it finds in 1.62 seconds on a 2020 Apple M1 (8 cores). On this query KuzuDB is able to take advantage of its Worst-Case Optimal Join : the “Multiway ASP Join” where the ASP stands for “Accumulate Semijoin Probe”. Check out their paper to learn more.
He also presents a “cut-up” version of the query that is forced to use regular binary (two table) joins. This query takes 51.17 seconds, that’s over 30x slower!
// Uses Binary Joins
MATCH (a:Page)-[e1:Links]->(b:Page)
WITH *
MATCH (b:Page)-[e2:Links]->(c:Page)
WIH *
MATCH (c)-[e3:Links]->(a)
RETURN count(*)
Let’s try this out in RageDB. First thing we need to do is prepare the data. We add a header line to the nodes csv file with just the word “key”, and the header line “start_key:Page,end_key:Page” to the relationships csv file. Now we can create the schema, load them and get the counts:
NodeTypeInsert("Page")
RelationshipTypeInsert("Links")
LoadCSV("Page", "/home/max/Downloads/kuzu/web-node.txt", ",")
LoadCSV("Links", "/home/max/Downloads/kuzu/web-edge.txt", ",")
local nodes_count = AllNodesCounts()
local rels_count= AllRelationshipsCounts()
nodes_count, rels_count
This results in [{“Page”:685231}, {“Links”:7600595}] which is the right count for our dataset. Now how would we write this query using RageDB’s Lua API? One way to write this query is to:
- start our count at 0
- get all the node ids (“a”)
- iterate over “a” and for each
- get the “b” nodes in the Out direction
- get the “c” nodes in the In direction
- for all “b” nodes get the neighbors that are “c” nodes
- add the number of matches to our count
The actual code looks like:
local count = 0
local a = AllNodeIds(0, 1000000)
for i = 1, #a do
local b = NodeGetNeighborIds(a[i], Direction.OUT, "Links")
local c = NodeGetNeighborIds(a[i], Direction.IN, "Links")
table.sort(c)
local bcs = NodeIdsGetNeighborIds(b, Direction.OUT, "Links", c)
for b_id, c_ids in pairs(bcs) do
count = count + #c_ids
end
end
count
This query executes in 9.5 seconds which beats the binary join query, but is slower than the wcoj query. Can we do a little better?
Of course. One thing that sticks out in the query is that the links from A to B are the same as from B to C, so there is no need to get these twice. We can also avoid any call overhead by using the bulk methods to get all the traversed relationships in two calls instead of two calls per node A. We cannot use the “c” as a predicate trick of the last query since so we’ll have to create our own “hash join” for “c” and check if any of our “b” nodes reach “c” in order to increment the count. Lua is a bit of a funky language that has a single built in data structure that is both an array and a map in one. It doesn’t have a “Set” data structure, but we can create a map and set the keys to true to simulate one. Take a good look at the code below:
local count = 0
local a = AllNodeIds(0, 1000000)
local outs = NodeIdsGetNeighborIds(a, Direction.OUT, "Links") --ab and bc
local ins = NodeIdsGetNeighborIds(a, Direction.IN, "Links") --ac
for _, node_a in pairs(a) do
local bs = outs[node_a]
local cs = ins[node_a]
local set = {}
for _, node_c in pairs(cs) do
set[node_c] = true
end
for _, node_b in pairs(bs) do
for _, node_c in pairs(outs[node_b]) do
if set[node_c] then
count = count + 1
end
end
end
end
count
How fast is this new query? It comes in at 5.6 seconds, shaving 4 seconds off our previous time, almost 10x faster than the KuzuDB binary joins plan, but we’re still 4 seconds slower than their wcoj query.

So what does this tell us? It tells us that RageDB needs to implement some kind of WCOJ algorithm. That may be a little hard to do with our “shared nothing/shard per core” architecture but I’ll try to come up with something. Want to help? Get in touch, I could really use it.
If you want to learn more about all this, here is some reading material:
Free Join: Unifying Worst-Case Optimal and Traditional Joins. Wang, Willsey, Suciu
Adopting Worst-Case Optimal Joins in Relational Database Systems. Freitag, Bandle, Schmidt, Kemper, Neumann (PVLDB 2020)
Worst-Case Optimal Join Algorithms: Techniques, Results, and Open Problems. Ngo. (Gems of PODS 2018)
Worst-Case Optimal Join Algorithms: Techniques, Results, and Open Problems. Ngo, Porat, Re, Rudra. (Journal of the ACM 2018)
What do Shannon-type inequalities, submodular width, and disjunctive datalog have to do with one another? Abo Khamis, Ngo, Suciu, (PODS 2017 – Invited to Journal of ACM)
Computing Join Queries with Functional Dependencies. Abo Khamis, Ngo, Suciu. (PODS 2017)
Joins via Geometric Resolutions: Worst-case and Beyond. Abo Khamis, Ngo, Re, Rudra. (PODS 2015, Invited to TODS 2015)
Beyond Worst-Case Analysis for Joins with Minesweeper. Abo Khamis, Ngo, Re, Rudra. (PODS 2014)
Leapfrog Triejoin: A Simple Worst-Case Optimal Join Algorithm. Veldhuizen (ICDT 2014 – Best Newcomer)
Skew Strikes Back: New Developments in the Theory of Join Algorithms. Ngo, Re, Rudra. (Invited to SIGMOD Record 2013)
Worst Case Optimal Join Algorithms. Ngo, Porat, Re, Rudra. (PODS 2012 – Best Paper)
…and a short video summary:
