
As a foreigner I was a little perplexed the first time I went to IHOP. You are served a stack of pancakes 3-5 high. How do you eat them? Do you pour syrup over the top and cut down through all the layers and eat them that way… or do you unstack them, pour syrup over each one and eat one at a time? If you are American, you eat them stacked. If you see someone eat them one at a time, you know they are shape-shifting lizard people. But doesn’t that mean the bottom layers are dry and don’t get any butter or syrup on them? Well you would think, but Americans are an ingenious people and they found a way to fix that problem. More syrup, more and more, and then a bit more to be sure… and a side of bacon. Now that you know all about IHOP, let’s switch gears to KHOP. Let’s say you wanted to find out how many nodes there were k-hops away from a starting node. What would be the best way to do that?
Let’s start with Cypher. If we have one product and we want to know the count of other products that were also purchased with this one and we have an ALSO_PURCHASED relationship in our graph then we can run this cypher query:
MATCH (p1:Product {id:953})-[:ALSO_PURCHASED]-(p2)
RETURN COUNT(p2)
It comes back with 549 in about a millisecond. Great, but what if we wanted to what that number was 2 hops away? Then we’d use the magical “star” in cypher and continue the path with the same relationship up to 2 hops away:
MATCH (p1:Product {id:953})-[:ALSO_PURCHASED*..2]-(p2)
RETURN COUNT(DISTINCT p2)
Now we’re up to 1314 in about 3 milliseconds. Ok that’s easy, how about if we keep going and jump to say… 8 hops away?
MATCH (p1:Product {id:953})-[:ALSO_PURCHASED*..8]-(p2)
RETURN COUNT(DISTINCT p2)
The count jumps to 147924, but it takes us 12 seconds to get the answer. What is it doing? Let’s put the word PROFILE in front of it and check it out:
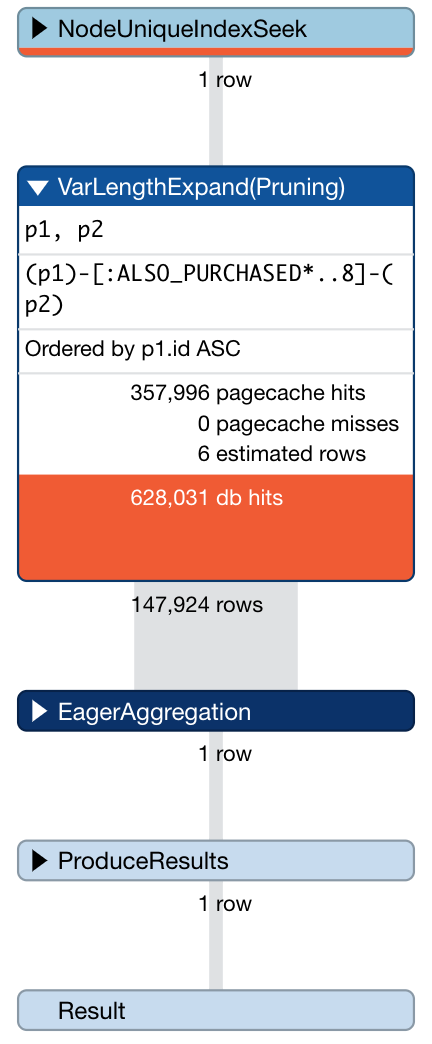
VarLengthExpand(Pruning)… Seems like it’s doing a lot of work, but I have no idea what it’s doing. Thanks to the power of open source, we can take a look the source…and I still have no idea what it’s doing. Ok. Let’s build a stored procedure instead.
If this sounds like deja vu to you, it’s because it is. I wrote about this exact issue back in October last year. Go ahead and read that post and come back here before you continue. We’re going to do the same thing again, but with two twists. First, we’re going to use the Neo4j Internal API. Then we’re going to make it parallel.
We’re going to call it khops2. It takes a starting node, the distance k we want to go, and a list of relationship types. If the user puts in a distance lower than 1 we return nothing because they are crazy. If the starting node is null, same thing, otherwise…
@Procedure(name = "com.maxdemarzi.khops2", mode = Mode.READ)
@Description("com.maxdemarzi.khops2(Node node, Long distance, List<String> relationshipTypes)")
public Stream<LongResult> khops2(@Name("startingNode") Node startingNode,
@Name(value = "distance", defaultValue = "1") Long distance,
@Name(value = "relationshipTypes", defaultValue = "[]") List<String> relationshipTypes) {
if (distance < 1) return Stream.empty();
if (startingNode == null) {
return Stream.empty();
} else {
Before we can use the Internal API we need to get access to it. The following Java incantation does the trick for us:
DependencyResolver dependencyResolver = ((GraphDatabaseAPI)db).getDependencyResolver();
final ThreadToStatementContextBridge ctx = dependencyResolver.resolveDependency(ThreadToStatementContextBridge.class, DependencyResolver.SelectionStrategy.FIRST);
KernelTransaction ktx = ctx.getKernelTransactionBoundToThisThread(true);
CursorFactory cursors = ktx.cursors();
Read read = ktx.dataRead();
TokenRead tokenRead = ktx.tokenRead();
What’s happening here exactly? We’re casting to GraphDatabaseAPI from the GraphDatabaseService so we can get a DependencyResolver. Then we’re getting access to the to the KernelTransaction via a bridge. Once we have ktx we’re in business. First thing we need is the cursor factory since the internal api works using Cursors that get reused instead of creating new nodes and relationships over and over as we traverse. Read will give us read methods, and TokenRead will let us figure out the internal ids of things. We start off by converting that list of relationship type names into actual relationship types ids using tokenRead:
int[] types = new int[relationshipTypes.size()];
for (int i = 0; i < types.length; i++) {
types[i] = tokenRead.relationshipType(relationshipTypes.get(i));
}
Next we’ll setup some RoaringBitmaps to store our node ids as we traverse. If you don’t know about Roaring Bitmaps then stop what you are doing and go look at this website. We need 3 because we need to keep track of what we’e seen. We need to keep track of what we need to traverse and we need to keep track of what we should traverse next.
// Initialize bitmaps for iteration
Roaring64NavigableMap seen = new Roaring64NavigableMap();
Roaring64NavigableMap nextOdd = new Roaring64NavigableMap();
Roaring64NavigableMap nextEven = new Roaring64NavigableMap();
We’ll add the starting node to Seen since we don’t want to traverse it more than once. Then we allocate two cursors. One for traversing relationships, another for nodes. We’ll initialize our nodeCursor with the id of the starting node and prime it with next();
seen.add(startingNode.getId());
RelationshipTraversalCursor rels = cursors.allocateRelationshipTraversalCursor();
NodeCursor nodeCursor = cursors.allocateNodeCursor();
read.singleNode(startingNode.getId(), nodeCursor);
nodeCursor.next();
To figure out the answer, we start by first finding the nodes directly connected to our starting node, and storing these in the NextEven bitmap. The way it’s done using the internal API is by calling allRelationships and passing in our relationship traversal cursor, or if we need to select specific relationships based on type, then we use a helper RelationshipSelections. Either way nextEven is getting all the node ids we need to traverse next.
// First Hop
if (types.length == 0) {
nodeCursor.allRelationships(rels);
while (rels.next()) {
nextEven.add(rels.neighbourNodeReference());
}
} else {
RelationshipSelectionCursor typedRels = RelationshipSelections.allCursor(cursors, nodeCursor, types);
while (typedRels.next()) {
nextEven.add(typedRels.otherNodeReference());
}
}
Nothing too crazy there. Since we don’t know what distance we need to go, we’ll stick our work in a loop. We’re basically doing the same whether doing an even or an odd hop, but the current and next bitmaps are reversed, so we’ll extract that into the method nextHop and look at it in a bit.
for (int i = 1; i < distance; i++) {
// Next even Hop
nextHop(read, seen, nextOdd, nextEven, types, cursors);
i++;
if (i < distance) {
// Next odd Hop
nextHop(read, seen, nextEven, nextOdd, types, cursors);
}
}
Our method nextHop needs to read, needs the bitmaps, the types of relationships we care about and a way to make new cursors. We will pass those in and then do the work. First we remove the seen from the current, then we add the current to the seen. We clear the next bitmap so we can put our new node ids here. Next we allocate a new set of cursors and prepare to iterate:
private void nextHop(Read read, Roaring64NavigableMap seen, Roaring64NavigableMap next,
Roaring64NavigableMap current, int[] types, CursorFactory cursors) {
current.andNot(seen);
seen.or(current);
next.clear();
RelationshipTraversalCursor rels = cursors.allocateRelationshipTraversalCursor();
NodeCursor nodeCursor = cursors.allocateNodeCursor();
For each nodeId in the current bitmap, we initialize and prime our nodeCursor. Then we traverse all relationships or just the ones we care about and add the node id to the next bitmap. Why is one called “neighbourNodeReference” and the other “otherNodeReference” I don’t know. They seem to do the same.
current.forEach(nodeId -> {
read.singleNode(nodeId, nodeCursor);
nodeCursor.next();
if (types.length == 0) {
nodeCursor.allRelationships(rels);
while (rels.next()) {
next.add(rels.neighbourNodeReference());
}
} else {
RelationshipSelectionCursor typedRels = RelationshipSelections.allCursor(cursors, nodeCursor, types);
while (typedRels.next()) {
next.add(typedRels.otherNodeReference());
}
}
});
That’s the end of our nextHop method. Once we finish all the traversing, we need to make sure we add the remainder node ids. For even traversals we add nextOdd, or odd ones we add nextEven. Once we remove our starting node id (since we wanted the neighbors after all) we can return the Cardinality of the bitmap which is our count.
if ((distance % 2) == 0) {
seen.or(nextOdd);
} else {
seen.or(nextEven);
}
// remove starting node
seen.removeLong(startingNode.getId());
return Stream.of(new LongResult(seen.getLongCardinality()));
Let’s compile our plugin, add it to the plugins folder of Neo4j, restart and try our query again:
MATCH (p1:Product {id:953}) WITH p1
CALL com.maxdemarzi.khops2(p1, 8) YIELD value RETURN value
We get 147923 (one less because we forgot to remove the starting node in our Cypher query) and it computes this in 87 ms. Much faster than the 12 seconds we started with using Cypher! Why is that? Cypher cares about paths, and is keeping track of them as it traverses, we only care about the nodes we’ve seen, so we can discard paths and go much faster.
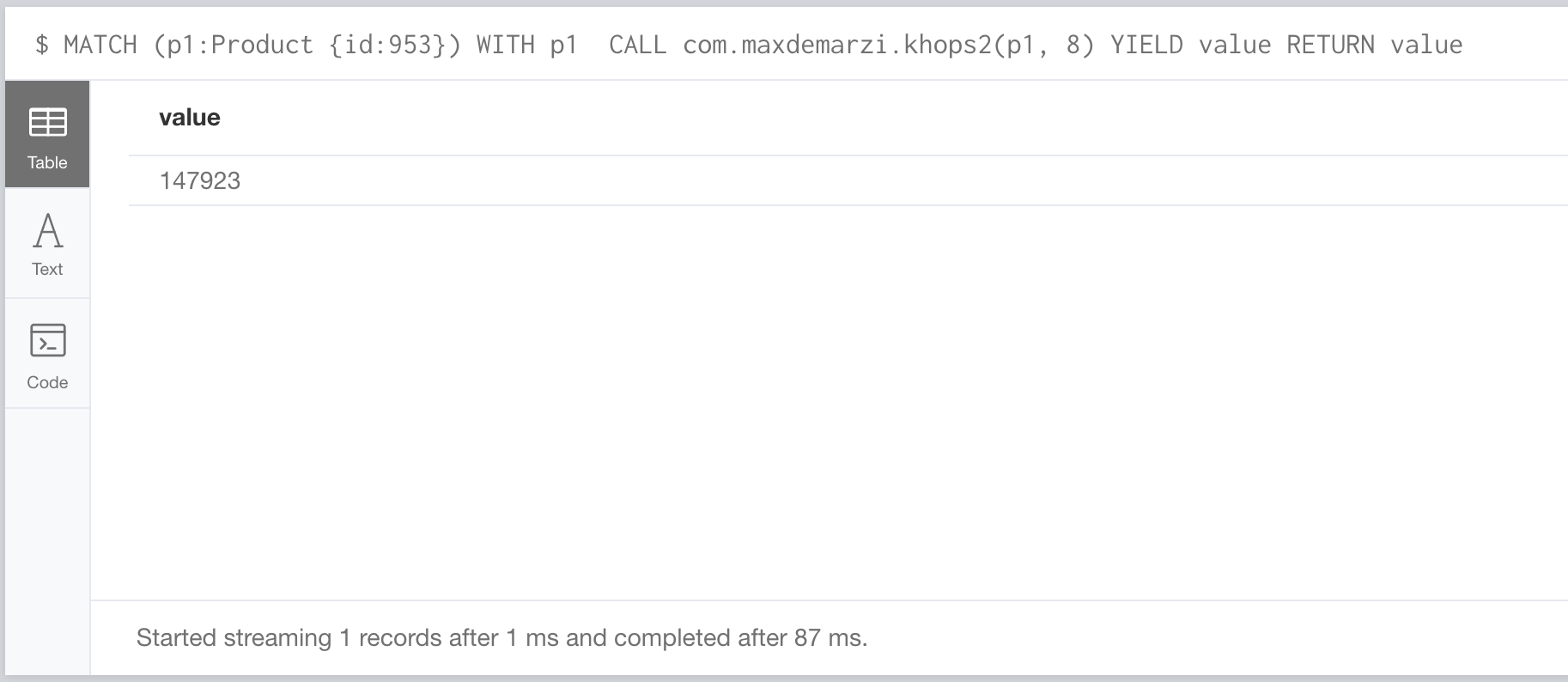
That’s great and all, but the title of the blog post said Parallel and I’m not seeing any parallelizing yet.

How can we go about making this stored procedure parallel? Well, after we traverse the first node, we have a bunch of neighbors to traverse at distance 2 and we can traverse them in parallel. So we’ll create a parallelkhops2, that starts off the same and then things get interesting. First off we still need a single “seen” bitmap to keep track of what we’ve seen, we’ll use a Phaser to keep track of threads, and instead of having a single nextOdd and nextEven, we’ll have an array of them. But the array size will be the number of cores plus one. Why plus one? Because we need to combine the results at each level before continuing and we’ll use this last spot for that purpose.
ExecutorService service = Executors.newFixedThreadPool(THREADS);
Roaring64NavigableMap seen = new Roaring64NavigableMap();
Phaser ph = new Phaser(1);
Roaring64NavigableMap[] nextOdd = new Roaring64NavigableMap[THREADS + 1];
Roaring64NavigableMap[] nextEven = new Roaring64NavigableMap[THREADS + 1];
for (int i = 0; i < (THREADS + 1); ++i) {
nextOdd[i] = new Roaring64NavigableMap();
nextEven[i] = new Roaring64NavigableMap();
}
We’ll setup our cursor just like before, and perform our first hop. The difference here is that instead of populating a single nextEven bitmap, we’ll “round robin” the next node ids we need to traverse to each of the bitmaps in our array (except the last one).
// First Hop
final AtomicLong index = new AtomicLong(0);
if (types.length == 0) {
nodeCursor.allRelationships(rels);
while (rels.next()) {
nextEven[(int)(index.getAndIncrement() % THREADS)].add(rels.neighbourNodeReference());
}
} else {
RelationshipSelectionCursor typedRels = RelationshipSelections.allCursor(cursors, nodeCursor, types);
while (typedRels.next()) {
nextEven[(int)(index.getAndIncrement() % THREADS)].add(typedRels.otherNodeReference());
}
}
After each traversal, we’ll combine the results into the last bitmap of nextOdd or next Even. Then we’ll remove the seen nodes from this combined bitmap, add the combination to seen for the next iteration, and with whatever node ids are left in our last bitmap we’ll round robin them to the rest of the array.
// Combine next
for (int j = 0; j < THREADS; j++) {
nextOdd[THREADS].or(nextOdd[j]);
nextOdd[j].clear();
}
// Redistribute next
index.set(0);
nextOdd[THREADS].andNot(seen);
seen.or(nextOdd[THREADS]);
nextOdd[THREADS].forEach(l -> nextOdd[(int)(index.getAndIncrement() % THREADS)].add(l));
Now we’re ready to traverse, we clear the other nextEven/Odd bitmaps, and submit a runnable to perform the actual traversal for each thread. These will run at the same time, and we’ll use our Phaser to wait for all of them to finish before moving on to the next distance.
// Next odd Hop
for (int j = 0; j < THREADS; j++) {
nextEven[j].clear();
service.submit(new NextHop(db, log, nextEven[j], nextOdd[j], types, ph));
}
// Wait until all have finished
ph.arriveAndAwaitAdvance();
So what does NextHop do? It sets our parameters and registers our Runnable on creation:
public NextHop(GraphDatabaseService db, Log log, Roaring64NavigableMap next,
Roaring64NavigableMap current, int[] types, Phaser ph) {
this.db = db;
this.log = log;
this.next = next;
this.current = current;
this.types = types;
this.ph = ph;
ph.register();
}
Then it traverses from each of the nodes just like before. Once it’s done, it deregisters from the Phaser so it is no longer waiting for it. Once all the NextHops are deregistered, we can keep going.
current.forEach(l -> {
read.singleNode(l,nodeCursor);
nodeCursor.next();
if (types.length == 0) {
nodeCursor.allRelationships(rels);
while (rels.next()) {
next.add(rels.neighbourNodeReference());
}
} else {
RelationshipSelectionCursor typedRels = RelationshipSelections.allCursor(cursors, nodeCursor, types);
while (typedRels.next()) {
next.add(typedRels.otherNodeReference());
}
}
});
}
ph.arriveAndDeregister();
That’s the end of the Runnable, once we go back to the procedure, we need to make sure we include the last nextOdd/Even to our seen bitmap, so we go through all the bitmaps in the array and perform the final arrive and deregister, so the Phaser knows we’re done.
if ((distance % 2) == 0) {
for (int j = 0; j < THREADS; j++) {
seen.or(nextOdd[j]);
}
} else {
for (int j = 0; j < THREADS; j++) {
seen.or(nextEven[j]);
}
}
ph.arriveAndDeregister();
Just like before we remove the starting node, and then return the result.
// remove starting node
seen.removeLong(startingNode.getId());
return Stream.of(new LongResult(seen.getLongCardinality()));
So how does it perform?
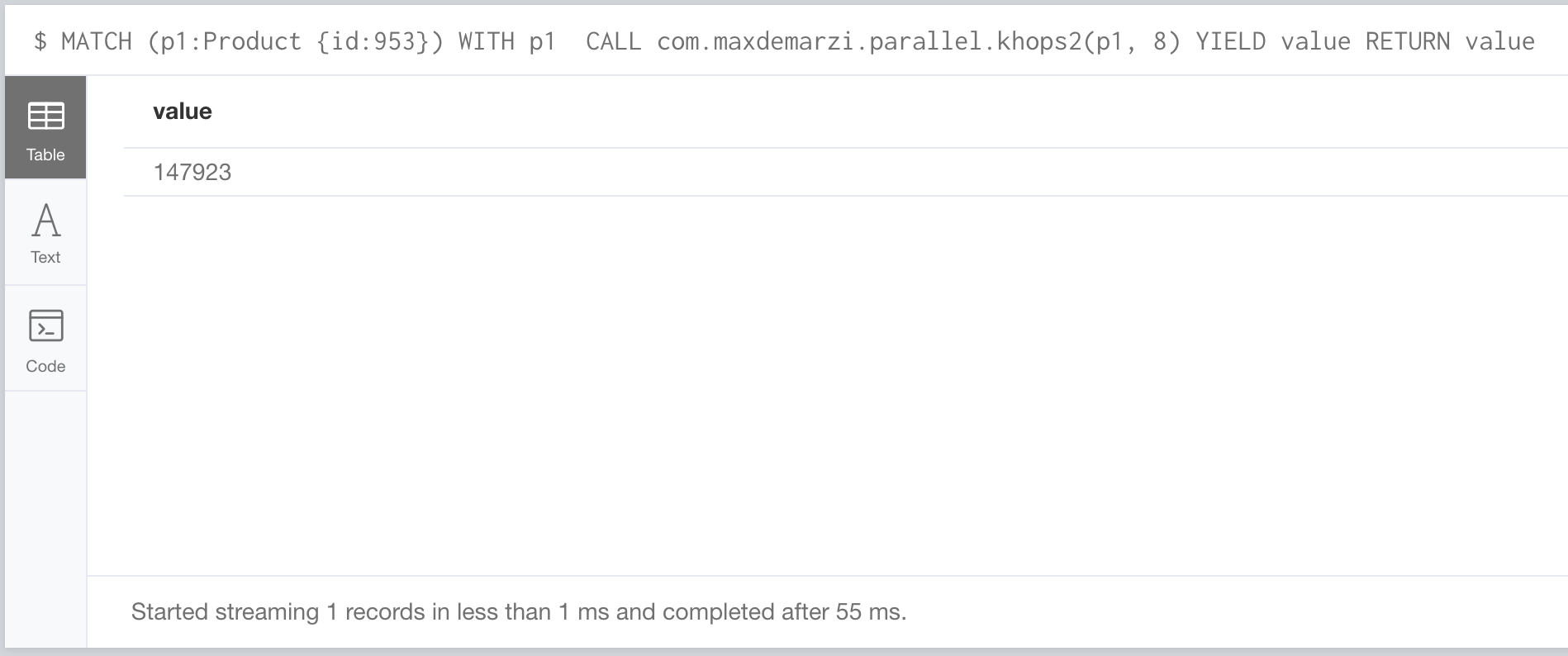
And now we’re at 55ms…Ok that’s better than 87ms, but not by much. Maybe my laptop and this small dataset is not a good way to show off the difference. Let’s try a bigger dataset on a bigger machine.
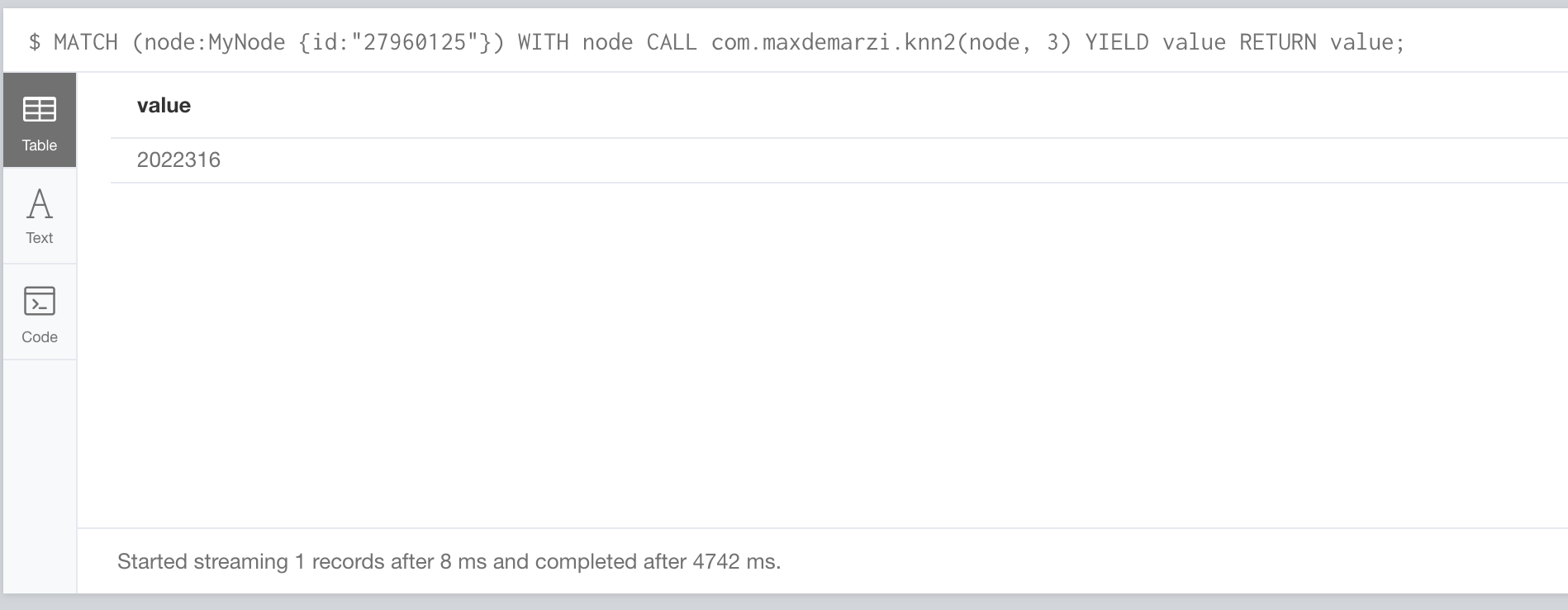
When we run our khops2 stored procedure, we get our answer back in 4742 ms.
With parallel.khops2 we’re at 685 ms.

… and look at those cores go. So pretty:

As always, the source code is available on github. Feel free to try it out, and if you find a way to improve it, please send me a pull request.
