
I think I am going to take the opportunity to explain why I love graphs in this blog post. I’m going to try to explain why looking at problems from the graph point of view opens you up to creative solutions and makes back-end development fun again. The context of our post is flight search, but our true mission is to figure out how to traverse a graph quickly and efficiently so we can apply our knowledge to other problems.
A long while back, I showed you different ways to model airline flight data. When it comes to modeling in graphs, the lesson to take away is that there is no right way. The optimal model is heavily dependent on the queries you want to ask. Just to prove the point, I’m going to show you yet another way to model the airline flight data that is truly optimized for flight search. If you recall, our last model looked like:

The last creative data modeling optimization we did was to create a “Destination” node to group flights going to the same destination on a particular day from the same airport. Later on I learned that there are only about 40k commercial airports in the world, well under the current 64k relationship type limit of Neo4j. This is useful because once a node has more than 40 relationships instead of storing the relationships in a list, they are broken up and stored in groups by type and direction. These are the so called “dense” nodes in the graph. What’s neat about this is that if we know the relationship type and direction, we can home in on just those and not even bother looking at other relationships. Remember, our traversal speed is dependent on how much of the graph we have to traverse to get the answer. Armed with this knowledge, we will remodel our graph so it looks like this:
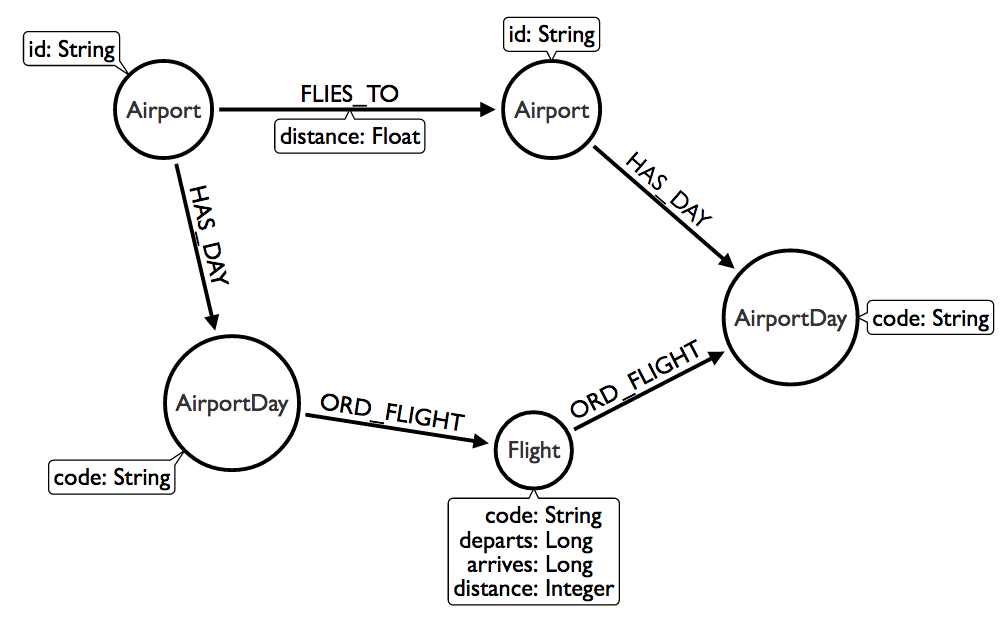
There are two things I want you to pay attention to here. One is that we brought back Airports. Two is the destination node has been replaced with a “typed” relationship. I use “dated” relationship types to make really crazy fast models in Neo4j, but this time the date lives as part of the “AirportDay” node, so we can use the airport code in the relationship type to speed things up.
The model lives in two planes (haha). On the higher plane we have the airports. On the lower plane we have the actual flights between them. It is important to remember that graphs should not be treated as flat two dimensional structures. They can have many dimensions and as you’ll soon see a single query may need to explore multiple levels of the graph to get the right answer. We will import some Airports with their codes and locations:

Now let’s import the individual flights between airports and we can see how SFO connects to ORD for example:
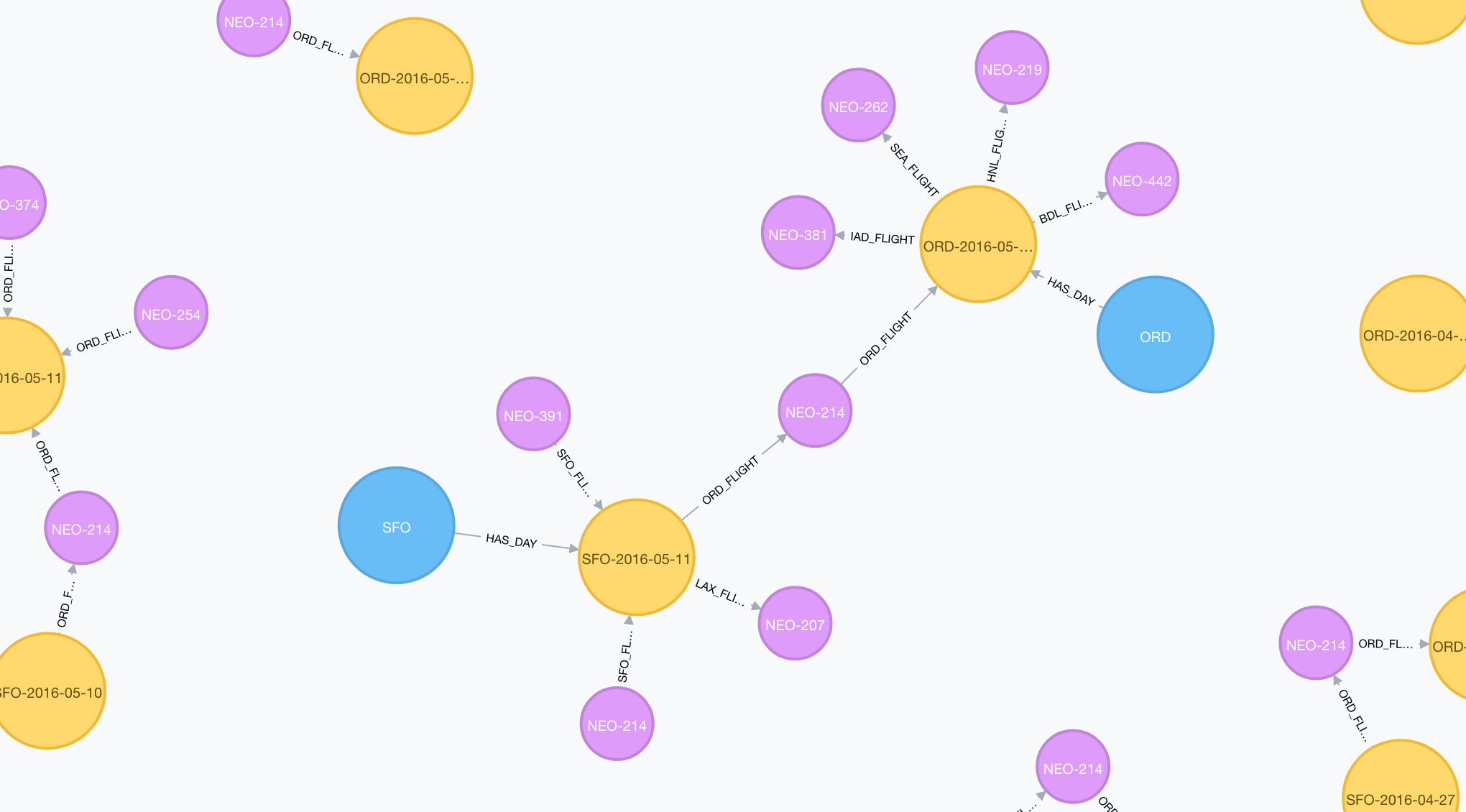
SFO and ORD Airport nodes were imported disconnected from each other, but we can take the data from the lower levels and use it to connect the Airports at the higher level via this query:
MATCH (a1:Airport)-[:HAS_DAY]->(ad1:AirportDay)-->
(l:Leg)-->(ad2:AirportDay)<-[:HAS_DAY]-(a2:Airport)
WHERE a1 <> a2
WITH a1, AVG(l.distance) AS avg_distance, a2, COUNT(*) AS flights
MERGE (a1)-[r:FLIES_TO]->(a2)
SET r.distance = avg_distance, r.flights = flights
Now take a look at the airports connected to each other:
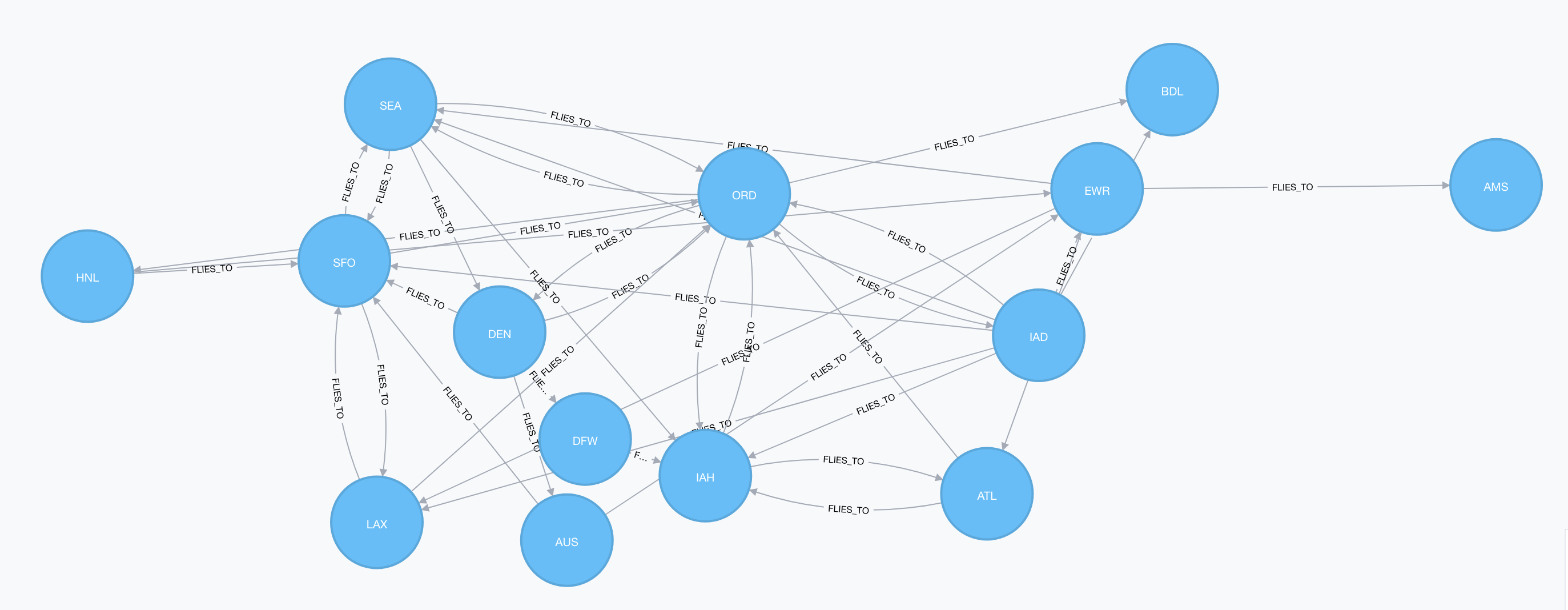
With our model in place, let’s start on the question we want to ask. Given two airports and a day, how do we find routes from one to the other performing the least amount of work possible. What I came up with is to first traverse just the Airport graph via the FLIES_TO relationships to find the best potential routes between the airports. Then once we have the potential routes, we traverse the lower level of the graph but only by following the routes we found at the higher level. This path restricted traversal at the lower levels will be fast because it won’t waste any time chasing routes that are not optimal.
This is where I need you to get to. Dream of your data as a graph and start exploring it one hop at a time. How do I get from here to there? Why would I choose to go one way and not another? How can I limit the amount of the graph I traverse to get to the right answer? Graphs are not just another dumb data store. They are a source of wonder and inspiration and possibility. A new type of freedom to find a better way to solve the problem. All you need to be able to do is embrace it…and well, you have to write the code. But don’t worry, if you can dream it, we can help you turn that dream in to Java code. Ok, that sounded awful, but the point still stands. Let’s see the stored procedure. If you have a wide monitor you may want to open up the source in a separate window and follow along with both side by side. We’ll declare our stored procedure and expect a few inputs. We want a list of potential departure airports, another list with potential arrival airports, a day and two limits. One for the number of flights to return, the second for a hard limit on how long the query is allowed to take.
@Description("com.maxdemarzi.flightSearch() | Find Routes between Airports")
@Procedure(name = "com.maxdemarzi.flightSearch", mode = Mode.SCHEMA)
public Stream<MapResult> flightSearch(@Name("from") List<String> from,
@Name("to") List<String> to,
@Name("day") String day,
@Name("recordLimit") Number recordLimit,
@Name("timeLimit") Number timeLimit) {
We’ll use these inputs to get the departure airport and arrival airport:
try (Transaction tx = db.beginTx()) {
for (String fromKey : getAirportDayKeys(from, day)) {
Node departureAirport = db.findNode(Labels.Airport, "code", fromKey.substring(0,3));
Node departureAirportDay = db.findNode(Labels.AirportDay, "key", fromKey);
if (!(departureAirportDay == null)) {
for (String toKey : getAirportDayKeys(to, day)) {
Node arrivalAirport = db.findNode(Labels.Airport, "code", toKey.substring(0,3));
Double maxDistance = getMaxDistance(departureAirport, arrivalAirport);
Our maxDistance is just 500 miles plus 2 times the distance between the airports. It is a good heuristic for how much pain our passengers are willing to endure in regards to long connecting flights. Speaking of long flights, we want to avoid them. So we perform our first of two traversals in this flight search query. What we want to do in the first traversal is use just the top level Airport to Airport plane of the graph to find potential routes and collect the airport code plus “_FLIGHT” as our allowed relationship types to traverse in the second traversal. This will prevent us from looking at flights from Los Angeles to Chicago that go through Hawaii or European countries. It will keep the traversal on direct and indirect flights that make sense.
// Get Valid Traversals from Each Departure Airport at each step along the valid paths ArrayList<HashMap<RelationshipType, Set<RelationshipType>>> validRels = allowedCache.get(fromKey.substring(0,3) + "-" + toKey.substring(0,3));
“allowedCache” is a Caffeine loading cache that figures out the best potential routes between two airports and caches their result. We want to cache the result because you may have thousands of queries for a specific route and since it won’t change very much there is no point in taking the db hit over and over.
private static final LoadingCache<String, ArrayList<HashMap<RelationshipType, Set<RelationshipType>>>> allowedCache = Caffeine.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(1, TimeUnit.HOURS)
.refreshAfterWrite(1, TimeUnit.HOURS)
.build(Flights::allowedRels);
private static ArrayList<HashMap<RelationshipType, Set<RelationshipType>>> allowedRels(String key) {
// calculate valid Relationships
Node departureAirport = graph.findNode(Labels.Airport, "code", key.substring(0,3));
Node arrivalAirport = graph.findNode(Labels.Airport, "code", key.substring(4,7));
Double maxDistance = getMaxDistance(departureAirport, arrivalAirport);
return getValidPaths(departureAirport, arrivalAirport, maxDistance);
}
So what does getValidPaths do? Well, it returns a list of valid relationship types to traverse from each airport at each step in the traversal. The naive approach would have just returned all the relationship types in the potential routes, but that would have let us chase invalid routes as long as they stuck to the allowed airpots. A smarter approach would have returned the relationship types allowed from an airport anywhere along the path, but once again that would have allowed invalid routes since order was not preserved. This version only allows relationship types from an airport at a particular step in the traversal, limiting us to only valid paths and saving us from chasing bad paths.
We do this by using a bi-directional traverser since we have both the starting and ending nodes.
private static ArrayList<HashMap<RelationshipType, Set<RelationshipType>>> getValidPaths(Node departureAirport, Node arrivalAirport, Double maxDistance) {
ArrayList<HashMap<RelationshipType, Set<RelationshipType>>> validRels = new ArrayList<>();
// Traverse just the Airport to Airport FLIES_TO relationships to get possible routes for second traversal
TraversalDescription td = graph.traversalDescription()
.breadthFirst()
.expand(bidirectionalFliesToExpander, ibs)
.uniqueness(Uniqueness.NODE_PATH)
.evaluator(Evaluators.toDepth(2));
// Since we know the start and end of the path, we can make use of a fast bidirectional traverser
BidirectionalTraversalDescription bidirtd = graph.bidirectionalTraversalDescription()
.mirroredSides(td)
.collisionEvaluator(new CollisionEvaluator());
for (org.neo4j.graphdb.Path route : bidirtd.traverse(departureAirport, arrivalAirport)) {
Double distance = 0D;
for (Relationship relationship : route.relationships()) {
distance += (Double) relationship.getProperty("distance", 25000D);
}
Now we need to collect those routes, make them quickly accessible and make sure we maintain order as well as potential destinations.
// Yes this is a bit crazy to follow but it does the job
if (distance < maxDistance){
String code;
RelationshipType relationshipType = null;
int count = 0;
for (Node node : route.nodes()) {
if (relationshipType == null) {
code = (String)node.getProperty("code");
relationshipType = RelationshipType.withName(code + "_FLIGHT");
} else {
HashMap<RelationshipType, Set<RelationshipType>> validAt;
if (validRels.size() <= count) {
validAt = new HashMap<>();
} else {
validAt = validRels.get(count);
}
Set<RelationshipType> valid = validAt.getOrDefault(relationshipType, new HashSet<>());
String newcode = (String)node.getProperty("code");
RelationshipType newRelationshipType = RelationshipType.withName(newcode + "_FLIGHT");
valid.add(newRelationshipType);
validAt.put(relationshipType, valid);
if (validRels.size() <= count) {
validRels.add(count, validAt);
} else {
validRels.set(count, validAt);
}
relationshipType = newRelationshipType;
count++;
}
}
}
} return validRels;
Now we can prepare the second traversal.
// Each path found is a valid set of flights,
private void secondTraversal(ArrayList<MapResult> results, Integer recordLimit, Node departureAirportDay, Node arrivalAirport, Double maxDistance, PathFinder<WeightedPath> dijkstra) {
for (org.neo4j.graphdb.Path position : dijkstra.findAllPaths(departureAirportDay, arrivalAirport)) {
if(results.size() < recordLimit) {
HashMap<String, Object> result = new HashMap<>();
ArrayList<Map> flights = new ArrayList<>();
Double distance = 0D;
ArrayList<Node> nodes = new ArrayList<>();
for (Node node : position.nodes()) {
nodes.add(node);
}
for (int i = 1; i < nodes.size() - 1; i+=2) {
Map<String, Object> flightInfo = nodes.get(i).getAllProperties();
flightInfo.put("origin", ((String)nodes.get(i-1).getProperty("key")).substring(0,3));
flightInfo.put("destination", ((String)nodes.get(i+1).getProperty("key")).substring(0,3));
// These are the epoch time date fields we are removing
// flight should have departs_at and arrives_at with human readable date times (ex: 2016-04-28T18:30)
flightInfo.remove("departs");
flightInfo.remove("arrives");
flights.add(flightInfo);
distance += ((Number) nodes.get(i).getProperty("distance", 0)).doubleValue();
}
result.put("flights", flights);
result.put("score", position.length() - 2);
result.put("distance", distance.intValue());
results.add(new MapResult(result));
}
}
}
Here we are creating a “PathRestrictedExpander” that takes a list of allowed relationship types in the constructor, the time we want this traversal to stop searching and the code of the airport of our final destination:
public PathRestrictedExpander(String endCode, long stopTime,
ArrayList<HashMap<RelationshipType, Set<RelationshipType>>> validRels) {
this.endCode = endCode;
this.stopTime = System.currentTimeMillis() + stopTime;
this.validRels = validRels;
}
When this expander expands, it will check the current time against our stop time, then see if we reached our destination airport. If not it will make sure the departure date is greater than our arrival time and minimum connect time (which is hard coded at 30 minutes for this example, but can be dynamic). This prevents people from missing their connections because they arrive at 5:00 pm and their connecting flight departs at 5:05 pm on the other side of the airport. Finally it will allow the traversal to continue over the allowed relationship types but only at the valid position in the path:
@Override
public Iterable<Relationship> expand(Path path, BranchState<Double> branchState) {
// Stop if we are over our time limit
if (System.currentTimeMillis() < stopTime) {
if (path.length() < 8) {
if (((path.length() % 2) == 0) && ((String)path.endNode().getProperty("key")).substring(0,3).equals(endCode)) {
return path.endNode().getRelationships(Direction.INCOMING, RelationshipTypes.HAS_DAY);
}
if (path.length() > 2 && ((path.length() % 2) == 1) ) {
Iterator<Node> nodes = path.reverseNodes().iterator();
Long departs = (Long)nodes.next().getProperty("departs");
nodes.next(); // skip AirportDay node
Node lastFlight = nodes.next();
if (((Long)lastFlight.getProperty("arrives") + minimumConnectTime) > departs) {
return Collections.emptyList();
}
}
if (path.length() < 2) {
RelationshipType firstRelationshipType = RelationshipType.withName(((String)path.startNode()
.getProperty("key")).substring(0,3) + "_FLIGHT");
RelationshipType[] valid = validRels.get(0).get(firstRelationshipType)
.toArray(new RelationshipType[validRels.get(0).get(firstRelationshipType).size()]);
return path.endNode().getRelationships(Direction.OUTGOING, valid);
} else {
int location = path.length() / 2;
if (((path.length() % 2) == 0) ) {
return path.endNode().getRelationships(Direction.OUTGOING, validRels.get(location)
.get(path.lastRelationship().getType())
.toArray(new RelationshipType[validRels.get(location)
.get(path.lastRelationship().getType()).size()]));
} else {
Iterator<Relationship> iter = path.reverseRelationships().iterator();
iter.next();
RelationshipType lastRelationshipType = iter.next().getType();
return path.endNode().getRelationships(Direction.OUTGOING, validRels.get(location).get(lastRelationshipType)
.toArray(new RelationshipType[validRels.get(location).get(lastRelationshipType).size()]));
}
}
}
}
return Collections.emptyList();
}
The last thing we have to do is to get the results of the traveral, verify one more time none of the paths found violate our maxDistance number and add their properties to the result. At this point our traversals are done and we just need to order and stream the results.
// Order the flights by # of hops, departure time, distance and the first flight code if all else is equal results.sort(FLIGHT_COMPARATOR); return results.stream();
As always the source code is on github… but hey I forgot to mention just how fast this is. Well on a performance test with a years worth of flight data, in the test of two stop queries, my 5 year old laptop was able to do 18 requests per second, with a mean of 72ms and a max of 280ms. Contrast this with the usual 10 second+ wait on most airline websites.

im getting this error com.maxdemarzi.import.airports is not available due to having restricted access rights, check configuration.
If you are using Neo4j 3.2 you need to add a setting to the configuration file to allow the stored procedure to run.
dbms.security.procedures.unrestricted=com.maxdemarzi.*
I’ve been reading the whole series of your articles around neo4j and flight data traversal the past couple days, to the point where I think I understand it all reasonably well – thanks very much for such a well done and well documented series of examples! I’ve been playing around with Spring Boot/Data/Neo4j with the @NodeEntity and repository convention – I was wondering if you’ve had a chance to think of how your examples would look like using that style or if your current approach is better?
I’m not much of a Spring developer, so I stick with just Neo4j.
What is your data source? Is the CSV used still publicly available anywhere?
[…] Follow-up blog post: Flight search […]
[…] simple search and find a provider based on location and/or specialty. As my colleague Max DeMarzi says, “The optimal model is heavily dependent on the queries you want to ask”. Queries that […]
[…] Do you happen to know what is meant by ORD_FLIGHT in the edges between AirportDay and Flight vertices in the second blog post? […]
How do you get the flights that they have at least 1 hop? As an example I want to go from SFO to ORD through ATL, that means that I have
SFO AirportDay –> ORD_FLIGHT –> Flight –> ORD_FLIGHT –> ORD AirportDay –> ATL_FLIGHT –> Flight –> ATL_FLIGHT –> ATL AirportDay