
Would you believe there is no shortage of Twitter Clone example applications…maybe because they are easy to replicate (ba dum tss, I’ll be here all week.) The earliest one I remember was written by Salvatore Sanfilippo creator of Redis.
It’s a pretty good read, where he explains the basics of Redis (a Key Value store on steroids) and how to model a social network in it. One of the interesting bits to me is how the status updates (tweets) are handled.
“After we create a post and we obtain the post ID, we need to LPUSH the ID in the timeline of every user that is following the author of the post” from Tutorial: Design and implementation of a simple Twitter clone using PHP and the Redis key-value store
foreach($followers as $fid) {
$r->lpush("posts:$fid",$postid);
}
So on every new post, the ID of the post gets pushed to all the timelines of the people following the poster. This works great when you only have a few users following you, but as the number of followers goes up, this gets worse and worse and you have to handle a ton of writes.
Another example using the document store Firebase instead uses the same approach: “When a new spark is posted, we’ll [put] it in the global list, and then put its ID in the feed of every user that is following the author.” from An open source Twitter clone built with Firebase
// Add spark ID to the feed of everyone following this user.
currentUser.child("followers").once("value", function(list) {
list.forEach(function(follower) {
var childRef = firebase.child("users").child(follower.name());
childRef.child("feed").child(sparkRefId).set(true);
});
});
Since Neo4j is a Graph Database, we can avoid this tremendous write overhead by simply following the relationships from our user to the people they follow to their posts. A model we could use looks like:

Then we use the following Cypher query to get our timeline:
MATCH (u:User {username:'maxdemarzi'})-[:FOLLOWS]->(f:User)-[p:POSTED|:REPOSTED]->(m:Message)
WHERE p.date > {last_seen_message_date}
RETURN f, p, m
ORDER BY p.date DESC
I wrote about timelines or “news feeds” previously. If you read that blog post, you know the problem with this query. As the number of POSTED and REPOSTED relationships grow, it will become slower and slower since it has to sift through a lot of relationships looking for the dates we want to return. A better model using the “dated relationship types” trick looks like this:
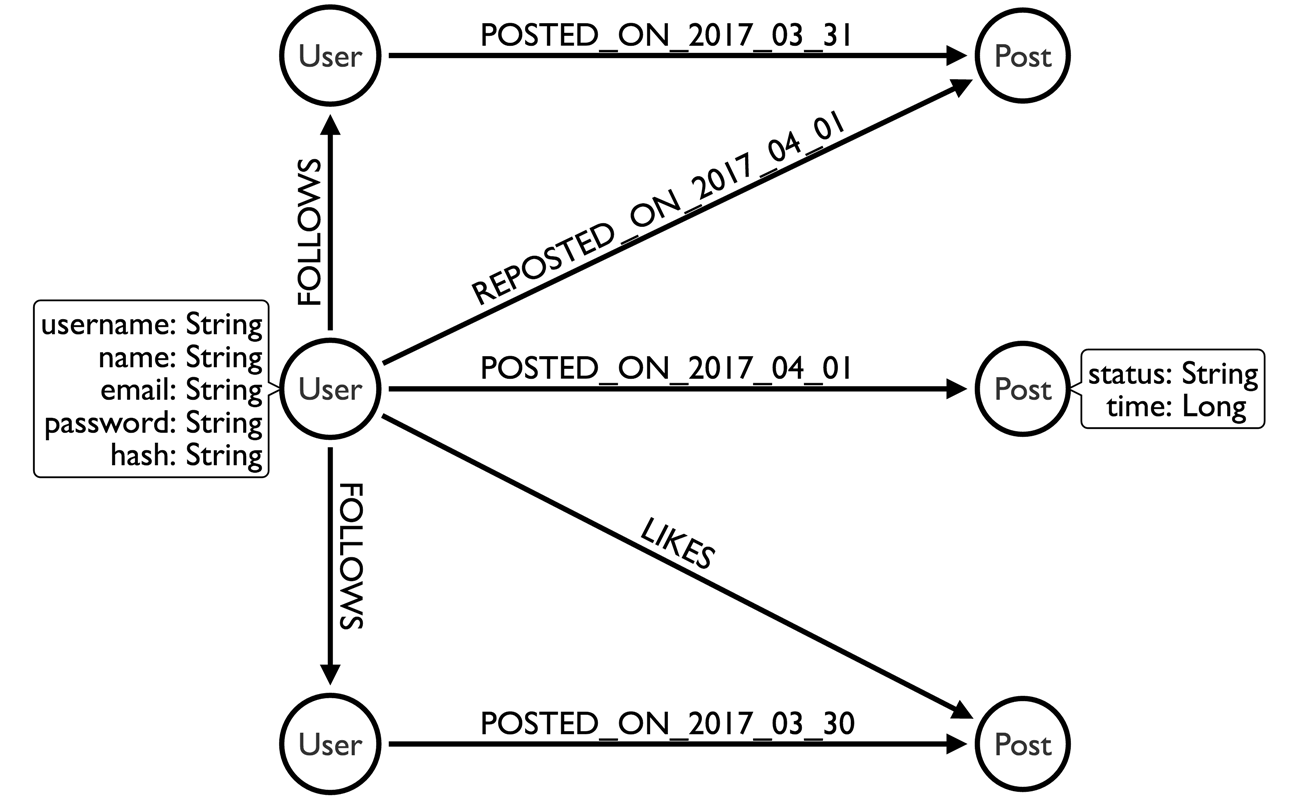
With this model we can choose which days to traverse which limits our search space tremendously and keeps our queries performing at similar levels instead of blowing up as time passes by. Our Cypher query would look like:
MATCH (u:User {username:'maxdemarzi'})-[:FOLLOWS]->(f:User)-[:POSTED_ON_2017_04_01|:REPOSTED_ON_2017_04_01]->(m:Message)
WHERE m.date > {last_seen_message_date}
RETURN f, m
ORDER BY m.date DESC
Over the next series of posts, I’m going to show you how to build the full Twitter Clone starting with the back-end and then adding a front-end to it. We are going to take advantage of the extensibility of Neo4j and create our back-end API directly on Neo4j as an Extension, combining the logic and data layer in the usual three tier architecture:
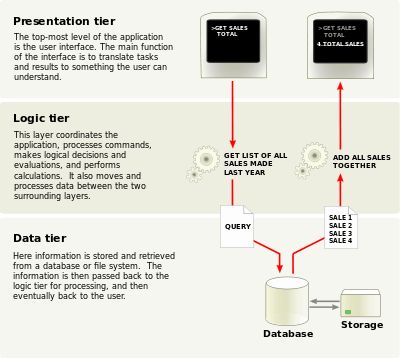
I am a huge fan of this approach because Neo4j is not a dumb relational database and shouldn’t be treated like one. Neo4j started life as a Java library and retains the power to add any functionality you want with a little elbow grease and some curly braces. Please subscribe to the blog or follow me on the real Twitter to get updates.
If you want to read ahead, take a look at the work in progress back-end extension repository and front-end application repository
On to part 2.

[…] has API to show for it which they can try to implement in some other technology. I mentioned in part one, that all the source code is already available. So while I may cut and paste chunks to explain what […]
[…] you’ve been paying attention since part one, you know the reason. Every time a user tweets, their tweet has to be added to the timelines of […]
[…] API for our Twitter clone, so thank you for sticking with this awfully long series since the beginning. One of the big community features of Twitter is the Trending Hashtags. It lets users know what is […]
[…] “typed” relationship. I use “dated” relationship types to make really crazy fast models in Neo4j, but this time the date lives as part of the “AirportDay” node, so we can use the […]
[…] Blog series: Building a Twitter Clone […]
Since you have named the relationship after Date stamp User -[:POSTED_ON_12_03_2019]-> POST what query will return all the posts that a particular user has posted?