
A boolean logic rules engine was the first project I did for Neo4j before I joined the company some 5 years ago. I was working for some start-up at the time but took a week off to play consultant. I had never built a rules engine before, but as far as I know ignorance has never stopped anyone from trying. Neo4j shipped me to the client site, and put me in a room with a projector and a white board where I live coded with an audience of developers staring at me, analyzing every keystroke and cringing at every typo and failed unit test. I forgot what sleep was, but managed to figure it out and I lost all sense of fear after that experience.
The data model chained together fact nodes with criss crossing relationships each chain containing the same path id property we followed until reaching an end node which triggered a rule. There were a few complications along the way and more complexity near the end for ordering and partial matches. The traversal ended up being some 40 lines of the craziest Gremlin code I ever wrote, but it worked. After the proof of concept, the project was rewritten using the Neo4j Java API because at the time only a handful of people could look at a 40 line Gremlin script and not shudder in horror. I think we’re up to two handfuls now.
Over the years a few projects have come up which needed rules that had to be evaluated. One example is a shopping cart that could trigger a discount if a set of items was purchased. Another is a job seeker with a set of skills that could match a job posting. One more could be a user with a set of tags that prompted an advertisement to be displayed.
Let’s imagine we have two users. User “max” has attributes “a1” and “a2”. User “alex” just has one attribute “a3”. A rule exists that is triggered by any user that has both “a1” and “a2” in its set or alternatively has “a3” but not “a4”. I’m going to use the shorthand “&” for ANDs, “|” for ORs and “!” for NOTs. So our rule would be “(a1 & a2) | (a3 & !a4)“. We could model the data this way:
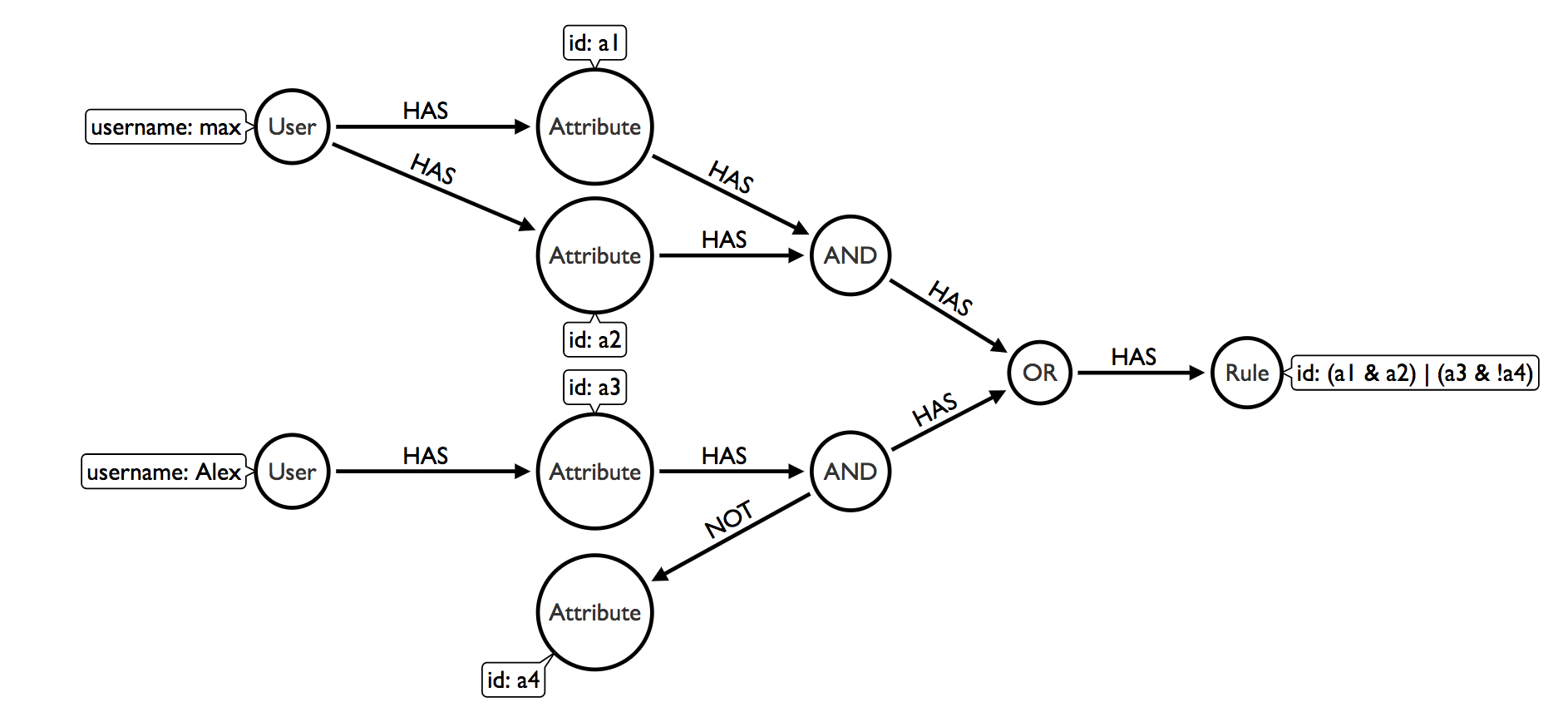
To see if a user triggers a rule, we would start by collecting their attributes and then from each attribute traversing in and out the AND and OR nodes looking backwards and checking if we had (or didn’t have for NOTs) the attributes required. All relationships leading to the AND nodes would have be valid, but just one of the relationships leading to the OR nodes. This is a valid way of doing it, but today I’m going to show you an alternative.
Instead of adding the AND/OR/NOT logic nodes to the graph, we are going to compress into “Path” nodes. We split our rule into two paths “(a1 & a2)” and “(a3 & !a4)” and our Graph looks like this:

In order to find if a user triggers a rule, we’ll create a stored procedure that finds the user, gets their attributes and for each attribute tries to find a set of rules:
@Procedure(name = "com.maxdemarzi.match.user", mode = Mode.READ)
@Description("CALL com.maxdemarzi.match.user(username) - find matching rules")
public Stream<NodeResult> matchUser(@Name("username") String username) throws IOException {
// We start by finding the user
Node user = db.findNode(Labels.User, "username", username);
if (user != null) {
// Gather all of their attributes in to two Sets (nodes, attribute ids)
Set<Node> userAttributes = new HashSet<>();
Collection<String> attributes = new HashSet<>();
for (Relationship r : user.getRelationships(Direction.OUTGOING, RelationshipTypes.HAS)) {
userAttributes.add(r.getEndNode());
attributes.add((String)r.getEndNode().getProperty("id"));
}
// Find the rules
Set<Node> rules = findRules(attributes, userAttributes);
return rules.stream().map(NodeResult::new);
}
return null;
}
The magic happens in the findRules method. For each attribute node we traverse out the IN_PATH relationship and get the “path” property of the relationship. We split it into an array of strings each holding an attribute id. We also split the “path” property into a character array using just the ANDs (“&”) and NOTs (“!”). For each path we check to see if we are missing a needed attribute or if we have an attribute we should not have. If either one of those is true we fail the path we are on and try the next.
Set<Node> findRules(@Name("attributes") Collection<String> attributes, Set<Node> userAttributes) {
Set<Node> rules = new HashSet<>();
Set<Node> paths = new HashSet<>();
for (Node attribute : userAttributes) {
for (Relationship r : attribute.getRelationships(Direction.OUTGOING, RelationshipTypes.IN_PATH)) {
// Get the "path" property
String path = (String)r.getProperty("path");
// Split it up by attribute and by & and !
String[] ids = path.split("[!&]");
char[] rels = path.replaceAll("[^&^!]", "").toCharArray();
// Assume path is valid unless we find a reason to fail it
boolean valid = true;
// Since our starting attribute is how we got here we skip checking it.
if (ids.length > 1) {
for (int i = 0; i < rels.length; i++) {
if (rels[i] == '&') {
// Fail if attribute is not there
if (!attributes.contains(ids[1+i])) {
valid = false;
break;
}
} else {
// Fail if attribute is there but should NOT be
if (attributes.contains(ids[1+i])) {
valid = false;
break;
}
}
}
}
// If we made it add it to the set of valid paths
if (valid) {
paths.add(r.getEndNode());
}
}
}
// For each valid path get the rules
for (Node path : paths) {
for (Relationship r : path.getRelationships(Direction.OUTGOING, RelationshipTypes.HAS_RULE)) {
rules.add(r.getEndNode());
}
}
return rules;
}
This makes our logic pretty easy to follow and we don’t have to worry about chasing ANDs, ORs or NOTs depending on which nodes we land on along the way. But how do we build this graph in the first place you may ask?
We’ll create another stored procedure for this called rules.create that takes a rule id and formula as input:
// This procedure creates a rule, ex. ("Rule 1", "(0 & 1) | (2 & 3)")
@Procedure(name = "com.maxdemarzi.rules.create", mode = Mode.WRITE)
@Description("CALL com.maxdemarzi.rules.create(id, formula) - create a rule")
public Stream<StringResult> create(@Name("id") String id, @Name("formula") String formula) throws IOException {
// See if the rule already exists
Node rule = db.findNode(Labels.Rule, "id", id);
if (rule == null) {
// Create the rule
rule = db.createNode(Labels.Rule);
rule.setProperty("id", id);
rule.setProperty("formula", formula);
This next part is where the magic happens. We take our formula and create a Boolean Expression. In this boolean expression we are going to create a Truth Table and use the Quine McCluskey algorithm to find the prime implicants and Petrick’s Method to find all minimum sum-of-products solutions which become our “Path” nodes.
// Use the expression to find the required paths BooleanExpression boEx = new BooleanExpression(formula); boEx.doTabulationMethod(); boEx.doQuineMcCluskey(); boEx.doPetricksMethod();
Do you remember taking “Digital Logic” in college and thinking… I’m never going to use this stuff… yeah. Ok, now for each path we’ll check to see if another rule already created this path and if not we’ll make one. This will let us trigger many rules if they share a common path.
for (String path : boEx.getPathExpressions()) {
Node pathNode = db.findNode(Labels.Path, "id", path);
if (pathNode == null) {
// Create the path node if it doesn't already exist
pathNode = db.createNode(Labels.Path);
pathNode.setProperty("id", path);
We’ll be generous here and for each attribute in the path we will either find it or create it. We will connect our path node to the first attribute in the path. All of our paths will be sorted the same way, so we will never have two equivalent Path nodes. If we have an “a1 & a2”, we will never have an “a2 & a1” path.
// Create the attribute nodes if they don't already exist
String[] attributes = path.split("[!&]");
for (int i = 0; i < attributes.length; i++) {
String attributeId = attributes[i];
Node attribute = db.findNode(Labels.Attribute, "id", attributeId);
if (attribute == null) {
attribute = db.createNode(Labels.Attribute);
attribute.setProperty("id", attributeId);
}
// Create the relationship between the lead attribute node to the path node
if (i == 0) {
Relationship inPath = attribute.createRelationshipTo(pathNode, RelationshipTypes.IN_PATH);
inPath.setProperty("path", path);
}
}
Lastly we’ll connect our path node to the rule node we created earlier:
// Create a relationship between the path and the rule pathNode.createRelationshipTo(rule, RelationshipTypes.HAS_RULE);
Alright. Let’s create some sample data and try it. We will create two rules:
CALL com.maxdemarzi.rules.create('Rule 1', '(a1 & a2) | (a3 & a4)')
CALL com.maxdemarzi.rules.create('Rule 2', '(a1 & a2) | (a3 & !a4)')
…and create a few sample users and connect them to some attributes like so:

For example user “max” has attributes “a1” and “a2”. So when we run our match procedure:
CALL com.maxdemarzi.match.user('max') yield node return node
We will return both rules.
In a large production deployment you may not want to store the user to attribute relationships or they may be transient like items in a temporary shopping cart for example. In this case you’ll want to pass in the attributes directly and call it this way:
CALL com.maxdemarzi.match.attributes(['a1','a2']) yield node return node
I’ll spare you the details but the complete source code is on github as always…and now you know one way to build a rules engine in Neo4j.
Update: If you have a path that is a single NOT or only NOTs it won’t work as shown. The way to deal with it is to have a global “always true” node in these cases and hang any single NOT or only NOT paths off this node that all users would have. This can be handled when the rule is being created or it handle during the path creation.

Max, I don’t even know how to thank you. I’ve been recently assigned to a business rules engine project, and i was trying to make these work with Cypher [image: Imagini inline 1] I’ve been reading your articles for years, so, thank you! And keep posting!
Regards, Gabriel
2017-08-25 8:35 GMT+02:00 Max De Marzi :
> maxdemarzi posted: ” A boolean logic rules engine was the first project I > did for Neo4j before I joined the company some 5 years ago. I was working > for some start-up at the time but took a week off to play consultant. I had > never built a rules engine before, but as far as” >
[…] this sounds familiar to you it’s because I just blogged about a boolean logic rules engine in a recent blog post. We can take the same ideas, turn them side ways and find out for any given […]
[…] few posts ago I showed you how to build a Boolean Logic Rules Engine in Neo4j. What I like about it is that we’ve pre-calculated all our potential paths, so […]