
So far I’ve only showed you how to traverse a decision tree in Neo4j. The assumption being that you would either create the rules yourself from expert knowledge or via an external algorithm. Today we’re going to add an algorithm to build a decision tree (well a decision stream) right into Neo4j. We will simply pass in the training data and let it build the tree for us. If you are reading this part without reading parts one, two, and three, you should because this builds on what we learned along the way.
A decision tree is built with nodes that look at a value and go left if that value is less than or equal to some threshold, or go right if the value is greater. The nodes can only go left or right and can only go down one level at a time. Decision trees are a great starting point for machine learning models, but they suffer from a few problems: overfitting, instability and inaccuracy. These problems are overcome by combining a few hundred to several thousand decision trees together into a Random Forest. A random forest decreases the variance of the results without increasing the bias, which makes for a better model, but we have a very hard time looking at a random forest and understanding what it is really doing.
A decision stream allows nodes to follow a path based on multiple options and may go down more than 1 level. You can read the paper explaining what it is all about, but for our purposes, we are interested in knowing that a single decision stream can be as effective as a random forest, but a whole lot easier to understand. The authors of the paper were also gracious enough to code their algorithm for us to try out and that’s what we’ll do.
We are going to build a stored procedure that takes training data, answer data, and a significance threshold (which determines when to merge or split our nodes) and uses the resulting model to build a tree in Neo4j. Our training data is just a CSV file where the first row has a header and the following rows have numbers. If we had string data like “colors” where the options were “red, blue, yellow, etc” we would have to convert these to a number mapping 1 for red, 2 for blue, etc. For this project we are going to be reusing data from an old Kaggle competition that looked at the likeliness of someone defaulting on their loans.
RevolvingUtilizationOfUnsecuredLines,Age,Late30to59Days,DebtRatio,MonthlyIncome,OpenCreditLinesAndLoans,Late90Days,RealEstateLoans,Late60to89Days,Dependents 0.7661,45,2,0.803,9120,13,0,6,0,2 0.9572,40,0,0.1219,2600,4,0,0,0,1 0.6582,38,1,0.08511,3042,2,1,0,0,0
Our answer data is extremely simple, it’s just a single column of 1s and 0s for defaulted, and did not default:
1 0 0 0
Instead of diving into the stored procedure, I’m going to show you how to use it first. Follow the README, build the procedure and add it to Neo4j. We call it by giving it a few parameters. The name of the tree, the file where the training data lives, the file where the answers live and a threshold for merging and splitting rule nodes. In our case giving it a 0.02 which seemed like a good general value according to the paper:
CALL com.maxdemarzi.decision_tree.create('credit',
'/Users/maxdemarzi/Documents/Projects/branches/training.csv',
'/Users/maxdemarzi/Documents/Projects/branches/answers.csv', 0.02)
It takes 2-3 minutes to train this dataset of about 100k records and once it’s done we can see the results:

The tree node is in blue, the rules are green, our parameters are purple and our answers are in red. Notice that two of the parameter nodes “Monthly Income” and “Debt Ratio” are not connected to any rules. This tells us that these two values are not helpful in predicting the outcome, which kinda makes sense since these two parameters are used to qualify someone for a loan before they even get one. The first Rule node along the tree is the number of times someone is “Late 60 to 89 Days” paying their bills. Four different relationships emanate from there. Notice at the end when the Rule nodes connect to the Answer nodes they do so for both “IS_TRUE” and “IS_FALSE” relationships. I’ll explain this in a moment. First let’s try traversing the decision tree by passing in some values. This is the same procedure from Part 3:
CALL com.maxdemarzi.decision_tree.traverse('credit',
{RevolvingUtilizationOfUnsecuredLines:'0.9572', Age:'40', Late30to59Days:'20',
DebtRatio:'0.1219', MonthlyIncome:'2600',OpenCreditLinesAndLoans:'4', Late90Days:'0',
RealEstateLoans:'0', Late60to89Days:'0', Dependents:'1'});
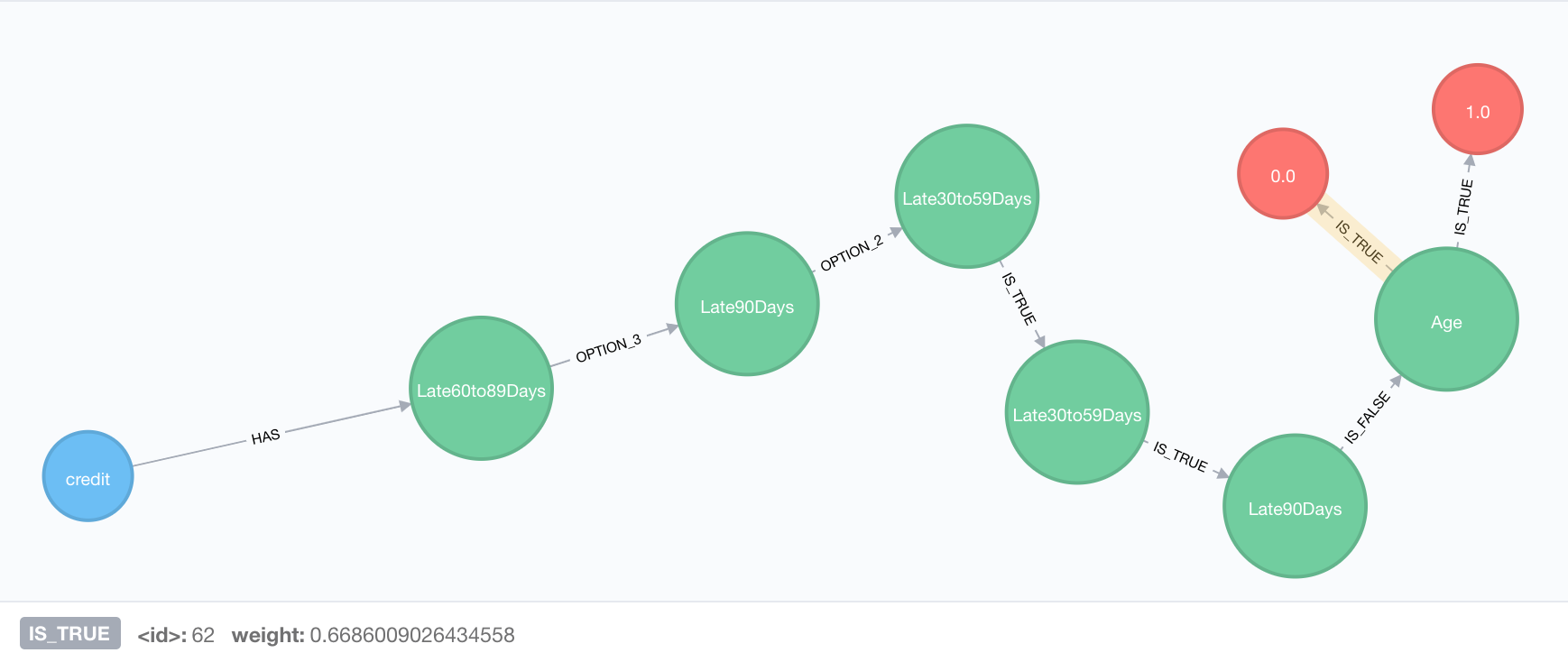
We get a path that ends in a Rule node checking “Age” connecting by the IS_TRUE relationship to both Answer nodes. The weights of those relationships however are different. We can see that if the user 66% likely to NOT default, vs 33% likely to default. So not only do we get a classifier, but we also get a confidence score.
If we omit the “Age” parameter in our query:
CALL com.maxdemarzi.decision_tree.traverse('credit',
{RevolvingUtilizationOfUnsecuredLines:'0.9572', Late30to59Days:'20',
DebtRatio:'0.1219', MonthlyIncome:'2600',OpenCreditLinesAndLoans:'4', Late90Days:'0',
RealEstateLoans:'0', Late60to89Days:'0', Dependents:'1'});

We get a partial path ending in the “Age” parameter as a way of asking for it, so we can ask the user for their age, re run the procedure and get a final answer.
The nice thing about this is that we can see and understand how the answer was derived. We can decide to alter the tree in any way, create many of them each from different training data, introduce parameters not in the original training set, whatever we want dynamically and still get results in real time.
I’m not going to explain the stored procedure line by line, but I do want to highlight a few things. You can see the whole thing at this repository. First thing is our stored procedure signature. Notice we are writing data to Neo4j so we need to use the Mode.Write option:
@Procedure(name = "com.maxdemarzi.decision_tree.create", mode = Mode.WRITE)
@Description("CALL com.maxdemarzi.decision_tree.create(tree, data, answers, threshold) - create tree")
public Stream<StringResult> create(@Name("tree") String tree, @Name("data") String data,
@Name("answers") String answers, @Name("threshold") Double threshold ) {
For all the different answers we are going to first create “Answer” nodes. In our case we only have 2 possibilities so, we will create two nodes.
for (Double value : answerSet) {
Node answerNode = db.createNode(Labels.Answer);
answerNode.setProperty("id", value);
answerMap.put(value, answerNode);
}
We want to create “Parameter” nodes for all the columns headers in our training data. We will save these in a “nodes” map and connect them to our Rules later.
HashMap<String, Node> nodes = new HashMap<>();
String[] headers = trainingData.next();
for(int i = 0; i < headers.length; i++) {
Node parameter = db.findNode(Labels.Parameter, "name", headers[i]);
if (parameter == null) {
parameter = db.createNode(Labels.Parameter);
parameter.setProperty("name", headers[i]);
parameter.setProperty("type", "double");
parameter.setProperty("prompt", "What is " + headers[i] + "?");
}
nodes.put(headers[i], parameter);
}
We will combine our answer and training data into a double array, which we then use to create a DoubleMatrix.
double[][] array = new double[answerList.size()][1 + headers.length];
for (int r = 0; r < answerList.size(); r++) {
array[r][0] = answerList.get(r);
String[] columns = trainingData.next();
for (int c = 0; c < columns.length; c++) {
array[r][1 + c] = Double.parseDouble(columns[c]);
}
}
DoubleMatrix fullData = new DoubleMatrix(array);
fullData = fullData.transpose();
The Decision Stream code was implemented in Clojure, but I don’t know Clojure so instead of trying to translate it into Java, I decided to just call it from our stored procedure. So we import Clojure core, get an interface to the training method for the model and then invoke it:
/* Import clojure core. */
final IFn require = Clojure.var("clojure.core", "require");
require.invoke(Clojure.read("DecisionStream"));
/* Invoke Clojure trainDStream function. */
final IFn trainFunc = Clojure.var("DecisionStream", "trainDStream");
HashMap dStreamM = new HashMap<>((PersistentArrayMap) trainFunc.invoke(X, rowIndices, threshold));
The training model returns as a nested hashmap with 4 values, the parameter, a threshold and two nested hashmaps on the left and right. From this we build our tree, combining leaf nodes whenever possible.
Node treeNode = db.createNode(Labels.Tree);
treeNode.setProperty("id", tree);
deepLinkMap(db, answerMap, nodes, headers, treeNode, RelationshipTypes.HAS, dStreamM, true);
The deepLinkMap method is used recursively for each side of the rule node, until we reach a Leaf node. One thing that was a bit of a pain was merging multi-option rule nodes into a single rule node, since the training map result doesn’t do this for us. The “merged” Rule nodes have a “script” property that ends up looking kinda like this:
if (Late60to89Days > 11.0) { return "IS_TRUE";}
if (Late60to89Days <= 11.0 && Late60to89Days > 3.0) { return "OPTION_1";}
if (Late60to89Days <= 3.0 && Late60to89Days > 0.0) { return "OPTION_2";}
if (Late60to89Days <= 3.0 && Late60to89Days <= 0.0) { return "OPTION_3";}
return "NONE";
Theoretically the “NONE” relationship type should never be returned, but the script needed a way to guarantee it ended and I didn’t want to mess with nested if statements.
Unmerged nodes have just two options “IS_TRUE” and “IS_FALSE” as well as a simple “expression” property that looks like the one below. The relationship type returned depends on the answer to the evaluation of that expression.
Late90Days > 0.0
As always the code is hosted on github, feel free to try it out, send me a pull request if you find any bugs or come up with enhancements. The one big caveat here is that I’m not a data scientists nor did I stay at a Holiday Inn Express last night, so please consult a professional before using.
