
Everybody loves benchmarks. Well let me rephrase that, everyone who publishes benchmarks loves the benchmark they publish. Nobody publishes benchmarks that make them look bad, it would be a terrible idea. But you my friend are in luck. I’m full of terrible ideas and today I’m going to publish some benchmarks that makes us look bad. Why? Because we are actively trying to improve this part of Neo4j and I want to experiment with some ideas and see what a ballpark theoretical limit should look like…and I’ll throw in some “inside baseball” about the graph database space from my point of view if you stick around until the end.
Alright, let’s start with the setup. I’m testing on my Mid 2015 Mac Book Pro while a bunch of stuff is running in the background, so this is not meant to be super scientific, just ballpark type measurements. I’m going to be comparing apples to oranges on purpose, so don’t get wound up about that. Exactly like how most vendor published benchmarks are done. We’re going to have a very simple graph with just two kinds of nodes: Person and Item. We’ll have 100k Person nodes and 2000 Item nodes. We’ll have just one type of relationship “LIKES”. Each Person will have 100 Outgoing LIKES to Item Nodes, which means each Item node will have approximately 5000 Incoming LIKES. Each LIKES relationship will have a single property “weight”. It will be a random Double between 0 and 10.0. For the more visual of you, it looks like this:
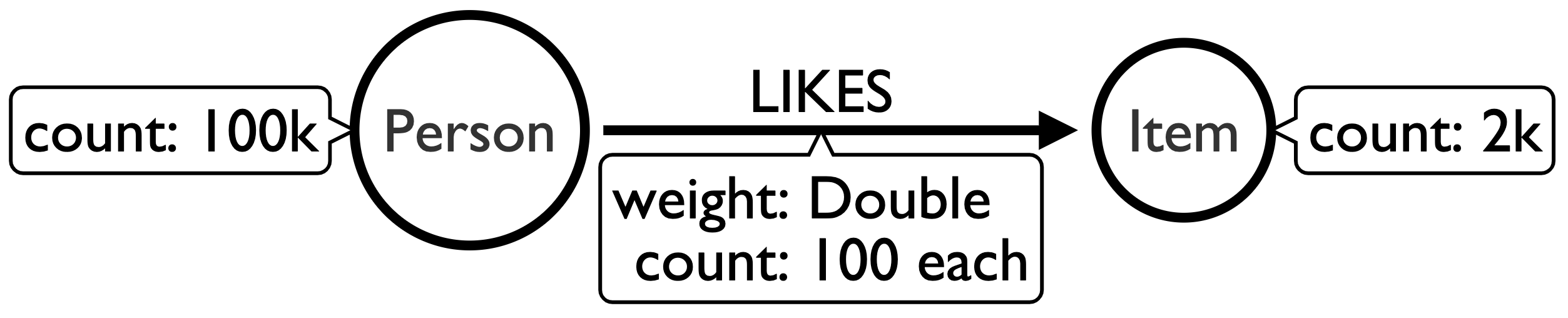
You can follow along with the source code, but I want to highlight a few things. First take a look at how I am creating the LIKES relationships. I am creating 100 likes at a time for each Person to a random Item. So while all the outgoing LIKES relationships from a Person will be right next to each other in order, the incoming LIKES relationships of the items will be all over the place, still in order, but not next to each other. You’ll see why this is important in a second.
for (long person = 0; person < personCount; person++) {
Node node = db.createNode(Label.label("Person"));
node.setProperty("person", person);
people.add(node.getId());
Random rand = new Random();
for (long like = 0; like < likesCount; like++) {
Long randomItem = items.get(rand.nextInt(items.size()));
Relationship r = node.createRelationshipTo(db.getNodeById(randomItem), RelationshipType.withName("LIKES"));
r.setProperty(WEIGHT, rand.nextDouble() * 10.0);
}
}
All of our tests will go through about 50 million relationships. In a proper benchmark you want this running isolated on some server for an hour or more, I don’t have that kind of patience, so we’ll warm it up 10 times and measure it 10 times.
Our first test will be an Ordered Traversal of relationships. Each Person has 100, so we’ll randomly pick one person 500,000 times and count up their relationships. Code looks like this:
public long measureOrderedTraversal() {
long[] count = new long[]{0};
GraphDatabaseService db = neo4j.graph();
Transaction tx = db.beginTx();
for (int i = 0; i < 500000; i++) {
Long randomPerson = people.get(rand.nextInt(people.size()));
Node person = db.getNodeById(randomPerson);
person.getRelationships(Direction.OUTGOING, LIKES).forEach(rel -> count[0]++);
}
return count[0];
}
It takes about 6 seconds to traverse those 50M relationships. If you divide them up, you get about 8.3 Million relationships traversed per second per core (the tests are all single threaded). Not too shabby. Alright now, how about the Unordered one? Well, each Item should have about 5000 relationships, so we’ll need to traverse through 10k items to get all the relationships we need:
public long measureUnOrderedTraversal() {
long[] count = new long[]{0};
GraphDatabaseService db = neo4j.graph();
Transaction tx = db.beginTx();
for (int i = 0; i < 10000; i++) {
Long randomItem = items.get(rand.nextInt(items.size()));
Node item = db.getNodeById(randomItem);
item.getRelationships(Direction.INCOMING, LIKES).forEach(rel -> count[0]++);
}
return count[0];
}
It takes about 2 minutes to traverse those 50M. That’s 120 seconds, so if you divide them up, you get about 400k relationships traversed per second per core. That’s pretty terrible. What happened? What’s going on? We’ll get to that in a bit, but first lets run two more traversals.
This next traversal will start at a random Person node, traverse out the LIKES relationships to the items they like. Then from those 100 items, we will traverse in the LIKES relationship to all the other people who also like these items, finally we will traverse out from these people to the items they like. The idea would be to group count the items that appear at the end, sort them, and display the top 10 in a recommendation type query. For our purposes we won’t do the grouping, just the counting. The code looks like this:
public long measureRecommendationTraversal() {
long[] count = new long[]{0};
GraphDatabaseService db = neo4j.graph();
Transaction tx = db.beginTx();
Long randomPerson = people.get(rand.nextInt(people.size()));
Node person = db.getNodeById(randomPerson);
person.getRelationships(Direction.OUTGOING, LIKES).forEach(rel -> {
long itemId = rel.getEndNodeId();
Node item = db.getNodeById(itemId);
item.getRelationships(Direction.INCOMING, LIKES).forEach(rel2 -> {
long otherPersonId = rel2.getStartNodeId();
Node otherPerson = db.getNodeById(otherPersonId);
otherPerson.getRelationships(Direction.OUTGOING, LIKES).forEach(rel3 ->
count[0]++);
});
});
return count[0];
}
It takes about 6 seconds to traverse all those relationships. So on this laptop we’re traversing at about 8.3 million relationships per second per core. That’s not bad. Not bad at all. Now let’s run one more traversal where we check the weight property before we traverse through it. We still want to go through all 50M relationships so we’ll check if it’s greater than negative one, which of course it should be.
public long measureRecommendationTraversalWithRelationshipProperties() {
long[] count = new long[]{0};
GraphDatabaseService db = neo4j.graph();
Transaction tx = db.beginTx();
Long randomPerson = people.get(rand.nextInt(people.size()));
Node person = db.getNodeById(randomPerson);
person.getRelationships(Direction.OUTGOING, LIKES).forEach(rel -> {
if ((double)rel.getProperty(WEIGHT) > -1.0) {
long itemId = rel.getEndNodeId();
Node item = db.getNodeById(itemId);
item.getRelationships(Direction.INCOMING, LIKES).forEach(rel2 -> {
if ((double)rel2.getProperty(WEIGHT) > -1.0) {
long otherPersonId = rel2.getStartNodeId();
Node otherPerson = db.getNodeById(otherPersonId);
otherPerson.getRelationships(Direction.OUTGOING, LIKES).forEach(rel3 -> {
if ((double)rel3.getProperty(WEIGHT) > -1.0) {
count[0]++;
}
});
}});
}
});
return count[0];
}
Our time just tripled to 17 seconds to go through those 50 million relationships checking the weight property every time. So we’re traversing at about 3 million relationships per second per core. If you’ve ever been in a call with me and asked for performance numbers, that’s where the 2-4 million traversals per second per core comes from. Because this last one is more typical of the kind of query we tend to see in production versus the other three.
Hopefully now you understand why we don’t publish performance numbers. Because the answer is always “it depends”. It depends on the query, it depends on the model, it depends on the physical layout of the graph which is dependent on how the data was loaded. If we rebuild our graph, but this time for each Item created 5000 LIKES relationships to random People, the first two traversal performance numbers would be reversed!
Never believe Vendor Benchmarks. Never. Just don’t.
Alright let’s talk a little about what is going on under the covers theoretically. Every node has a double linked list of its relationships. This double linked list intertwines with every node it shares in a relationship. The node points to the first relationship on this list, and then each relationship points to the next and previous. Why a double linked list instead of a single linked list? To make deleting relationships faster, which in hindsight may or may not be the wisest design choice since deleting relationships is a “rare” operation. Take a good look at the picture below, it is how Neo4j represents nodes and relationships. Don’t ask me why we have 5 bytes for node labels. The whole multiple labels on a node thing makes me unreasonably angry.
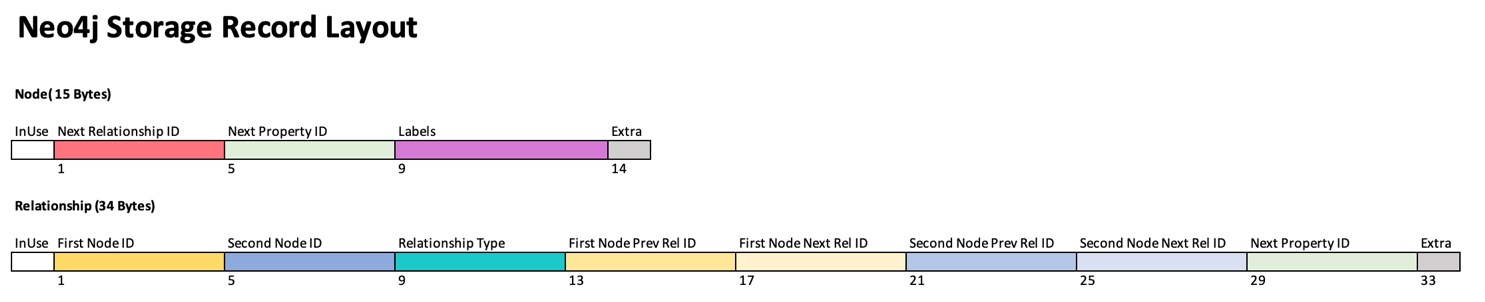
From this hopefully you have gathered how Neo4j traverses. It finds the node, goes to the first relationship, and from there keeps going until it reaches the end. It’s a bit more complicated than that. Once a node goes over 40 relationships, we break the relationship list into multiple relationship lists grouped by the relationship type, and the node points to this grouping and goes from there. What I want you to take away is that each relationship points to another relationship which could be anywhere. Relationship 1 could point to relationship 8344232 as the next one in the list. Where does this relationship live? Somewhere far away from relationship 1 in memory. Neo4j is jumping all over the place in memory one relationship at a time as it traverses. By the way, this is why we recommend you run Neo4j on SSDs. Because if you don’t have enough memory to hold it all, it will have to jump all over the place on disk. Which is fine for SSDs, but will murder your old school spinning disks.
To make things easier to visualize the internals of Neo4j, I often refer people to this image:
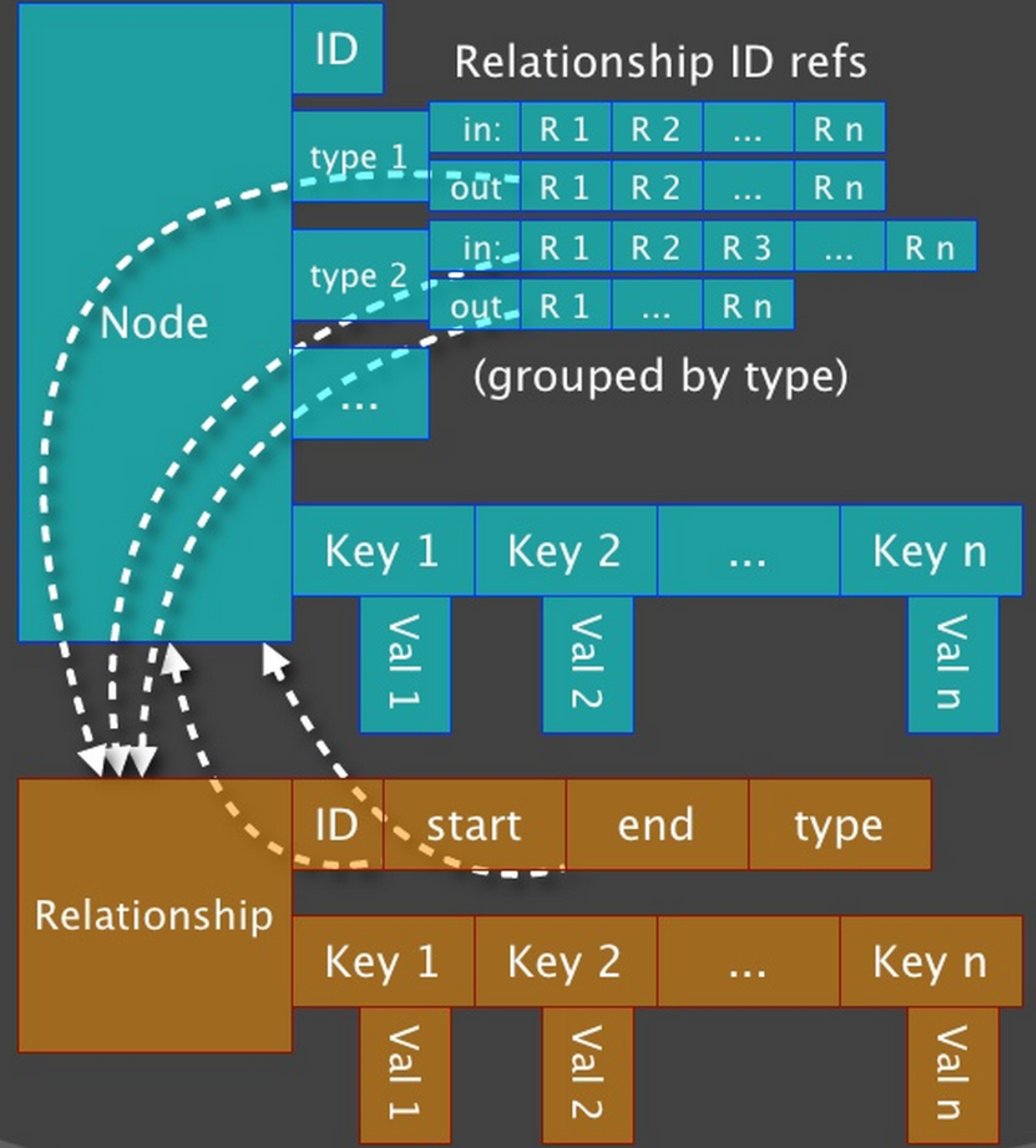
The only problem of course is that it makes you think the lists of relationships of a node are in an array instead of this double link list happy tree type of thing. But what if they were? Could we expect our traversal speed to improve significantly? Let’s find out.
But how? I’m not going to go anywhere trying to mess with Neo4j’s codebase. It’s HUGE and complicated and to be quite frank, more than I can handle. So let’s just write a mini version of Neo4j. Not the whole database of course, just the part that would do the traversals if we didn’t have a query language, or transactions, or multi-threading, or physical storage, or really anything but traversing to worry about… and let’s do it all in C.
![]()
Now… I haven’t coded anything in C since college 20 years ago, so lower your expectations, lower… a bit more ok. Now you can go take a look at the code if you want.
I am making heavy use of M*LIB from Patrick Pelissier, a sprinkle of Roaring Bitmaps from Daniel Lemire and cJSON from Dave Gamble.
There is a bunch to consider, but I wanted to code up the concept of splitting up the relationships of each node into two arrays. Each of theses arrays will have be an array of structs that contain just the “other” node_id and the id of the relationship. Each item in the array looks like this:
typedef struct Ids {
uint32_t node_id;
uint32_t rel_id;
} ids;
They are not in any order right now (that’s a good idea for another blog post). So how fast can we traverse if all the relationships of a node were right next to each other? Using the same size graph as before, this is what our performance test looks like:
int random_person = rand()%((person_count));
snprintf(buf, 12, "person%d", random_person);
for M_EACH(item,
*neo4c_node_get_weighted_outgoing(graph, "LIKES", "Person", buf),
array_combination_t) {
for M_EACH(person,
*neo4c_node_get_weighted_incoming_by_id(graph, "LIKES", item->node_id),
array_combination_t) {
for M_EACH(other_item,
*neo4c_node_get_weighted_outgoing_by_id(graph, "LIKES", person->node_id),
array_combination_t) {
count++;
}
}
}
Time to Create Graph of 2000 items, 100000 people, 10000000 total likes: 16.3556 seconds ============================ Simple Traversal ============================ Traversals of about 49966517.800000 relationships took: 150.096100 ms to execute each Iterations per second: 6.662398 Iterations: 10 Count: 499665178 Traversals per millisecond: 332896.842756
Remember we started with about 6 seconds per traversal looking at 8.3 million relationships per second. This result tells us it ran the traversal in 150 ms, and averaged about 330 million relationships per second. About 40 times faster. We’re of course comparing apples to bananas, but finding a way to keep all the relationships of a node close together and splitting up the lists into two seem like good avenues of investigation for making Neo4j faster in 2020.
But I also wanted to test having the weights of the relationships stored together with the ids. So I have added the concept of a weighted relationship that looks like this:
typedef struct Combination {
uint32_t node_id;
uint32_t rel_id;
double weight1;
double weight2;
} combination;
Our test code then checks the weight as it traverses:
for M_EACH(item,
*neo4c_node_get_weighted_outgoing(graph, "LIKES", "Person", buf),
array_combination_t) {
if (item->weight1>weight_check) {
for M_EACH(person,
*neo4c_node_get_weighted_incoming_by_id(graph, "LIKES", item->node_id),
array_combination_t) {
if (person->weight1>weight_check) {
for M_EACH(other_item,
*neo4c_node_get_weighted_outgoing_by_id(graph, "LIKES", person->node_id),
array_combination_t) {
if (other_item->weight1 > weight_check) {
count++;
}
}
}
}
}
}
Here are the results:
============================ Property Traversal With Weight ============================ Traversals of about 49971291.700000 relationships took: 282.543200 ms to execute each Iterations per second: 3.539282 Iterations: 10 Count: 499712917 Count2: 504713502 Traversals per millisecond: 176862.482268
We’re going at about 175 million relationships per second or half the speed as our first traversal. Remember Neo4j slowed down to a third of the initial traversal speed. So this is another avenue worth pursuing in our search for better performance in 2020. The Neo4j devs are already experimenting with these ideas, we’ll see what kind of speed ups we get.
If you have any ideas, or want to throw some shade on me for this horrific code, please leave a comment below.
Oh wait, I almost forgot about the “inside baseball” part. Listen. The great majority of Neo4j deployments run on 3 servers. Not dozens of servers like a typical Cassandra or Mongo deployment, just 3 servers. Mostly for High Availability reasons (in case one goes down). Many of these deployments would run perfectly fine on a single server. Of course, some of these servers are pretty beefy with many deployments using 128 GB, 256 GB and more RAM depending on the size of their graph.
Making Neo4j faster hasn’t been the highest priority since… well since you really can’t use less than 3 servers anyway. So if some mangy cat comes knocking on your door touting some nonsense benchmarks that have already been refuted twice, just shoo them away and tell them to come back when their queries aren’t 200 lines long.
Every month we get a new competitor and I was really hopeful for this other one after all the hype they built up and somehow managing to mix Isaac Asimov and Terminator in their messaging, but when I saw their query language I vomited a little.
Here is a hint to our frenemies in the industry. We have years worth of training materials, presentations, videos, blog posts, stack overflow answers, forum answers, thousands of certified developers, and tons of example code for Cypher. And we opened it up so you can add Cypher to your graph database product. Why in the world are you trying to create your own custom language that nobody knows? Just use Cypher as your product surface and leverage all that work. If you don’t like Cypher, then work with the GQL community and bring your language ideas so that we can all benefit. Neo4j has been creating and growing this space for 20 years. Work with us and help grow the graph database space together, work against us and you’ll just end up another entry on the list of long forgotten competitors.

Hi Max … wondering what you think about redis-graph , and it’s approach of using an adjacency matrix and sparse-matrices linear algebra for traversals ( and also adopting cypher) …
Thanks Max for the great post. Aside from the development work you mentioned Neo4j engineers will be looking into, is there anything here that everyday users can take away, in terms of data engineering and how to optimally create relationships when building a graph?
Hi Max how are you? I hope everything is fine. I’d like to know, in order to build a recommendation engine does Neo4j uses any of the PREA algorithms? If so, which one? How? Please inform
No. You build your own recommendation engine by combining a number of different queries that each recommend products in various ways and sending an aggregate of those recommendations to the user. For example 1 query to get recs based on previous order history on all orders, another for just the last few orders, another based on similar user behavior, another based on search queries, another focused on new products, another focused on products “on sale”, etc… build anywhere from 5-50 of these, aggregate items that appear multiple times using different weights, and give the user a final top x.