![]()
On Neo4j’s User Slack someone was having a bit of a hard time getting a query to return quickly. Their model had User Nodes and Transaction Nodes, and they wanted to get the last 25 transactions for a user. This particular user had millions of transactions and the query was taking forever. I’m going to show you how we can speed up the query and hopefully teach you a new modeling trick you can use in your graphs.
If we wanted to ask Neo4j to fetch us the first 25 transactions it can find for a user, we can write this query:
MATCH (u:User {username:"max"})-[:HAS_TX]->(tx:Transaction)
RETURN tx
LIMIT 25
Assuming you have an index on :User(username) it will come back pretty fast… like 1 or 2 ms fast. However if we want the first transactions sorted in descending order we need to tweak our query a bit by adding the ORDER BY clause:
MATCH (u:User {username:"max"})-[:HAS_TX]->(tx:Transaction)
RETURN tx
ORDER BY tx.date DESC
LIMIT 25
How long this query takes depends on how many transactions a user has. If they just have a few thousand, it won’t be a big deal, but at a million transactions, it’s a lot of work. Let’s go ahead and test this out. Spin up an empty Neo4j instance and follow along with me.
The first thing I want to do is to create 5 million transactions with dates ranging from today to 4 years in the past. We can make use of the datetime() function to get today’s date, and we can subtract a duration in days “PxD” where x is the number of days. Since there are about 365.25 days in a year we can multiply that by 4 and get 1461. We want a random number between 0 and 1461 so we multiply 1461 by the rand() function and cut off the decimal part using ceil(). We don’t want to do this one at a time, so we can use FOREACH to create 1M of them at once. Try this query, and run it 5 times.
FOREACH (r IN range(1,1000000) |
CREATE (:Transaction {date: (datetime() - duration('P' + ceil(1461 * rand()) + 'D'))} )
)

Why don’t we just create 5M nodes all at once? Well we could on a proper Server, but I’m still on a 2015 MBP (with a problem free keyboard) and transactions of about 1M nodes is all I can handle. Alright, now let’s create 5 users:
CREATE (u1:User {username:"max"})
CREATE (u2:User {username:"michael"})
CREATE (u3:User {username:"beth"})
CREATE (u4:User {username:"anton"})
CREATE (u5:User {username:"julia"})

Now we need to give each User 1 Million transactions. Since we started with an empty database, we know the first 5 million node ids (starting with 0) are going to be these transaction nodes, so we can use the ID function to split them one million at a time and connect them to our users. Lets start with the first user:
MATCH (u:User {username:"max"}), (tx:Transaction)
WHERE 0 <= ID(tx) < 1000000
CREATE (u)-[:HAS_TX]->(tx);

Now do the same thing for the other 4, but change the node id number range:
MATCH (u:User {username:"michael"}), (tx:Transaction)
WHERE 1000000 <= ID(tx) < 2000000
CREATE (u)-[:HAS_TX]->(tx);
MATCH (u:User {username:"beth"}), (tx:Transaction)
WHERE 2000000 <= ID(tx) < 3000000
CREATE (u)-[:HAS_TX]->(tx);
MATCH (u:User {username:"anton"}), (tx:Transaction)
WHERE 3000000 <= ID(tx) < 4000000
CREATE (u)-[:HAS_TX]->(tx);
MATCH (u:User {username:"julia"}), (tx:Transaction)
WHERE 4000000 <= ID(tx) < 5000000
CREATE (u)-[:HAS_TX]->(tx);
Now that we have our users and transactions loaded, let’s get 25 transactions for our first user:
PROFILE MATCH (u:User {username:"max"})-[:HAS_TX]->(tx:Transaction)
RETURN tx
LIMIT 25
The profiler tells us: “Cypher version: CYPHER 3.5, planner: COST, runtime: COMPILED. 54 total db hits in 2 ms.” Nice. What is it doing?

Finding the User by a label scan since we didn’t create indexes (don’t need to really with 5 users), and once it finds the user it expands to find the transaction nodes. Now let’s order by descending date and get the 25 latest transactions.
PROFILE MATCH (u:User {username:"max"})-[:HAS_TX]->(tx:Transaction)
RETURN tx ORDER BY tx.date DESC
LIMIT 25
The profiler tells us: “Cypher version: CYPHER 3.5, planner: COST, runtime: COMPILED. 3000012 total db hits in 1219 ms.” Ouch. That’s way slower. What is it doing?

It spends most of the time sorting the 1M transactions by date. Maybe we should add an index on Transaction date?
CREATE INDEX ON :Transaction(date);
Give that index a few seconds to finish populating and get online, then run the query again. What happened? Absolutely nothing. It doesn’t use the index because it traverses instead. How do we fix that? Well we need to add a WHERE clause to have the index kick in:
PROFILE MATCH (u:User {username:"max"})-[:HAS_TX]->(tx:Transaction)
USING JOIN ON u
WHERE tx.date < datetime()
RETURN tx ORDER BY tx.date DESC
LIMIT 25
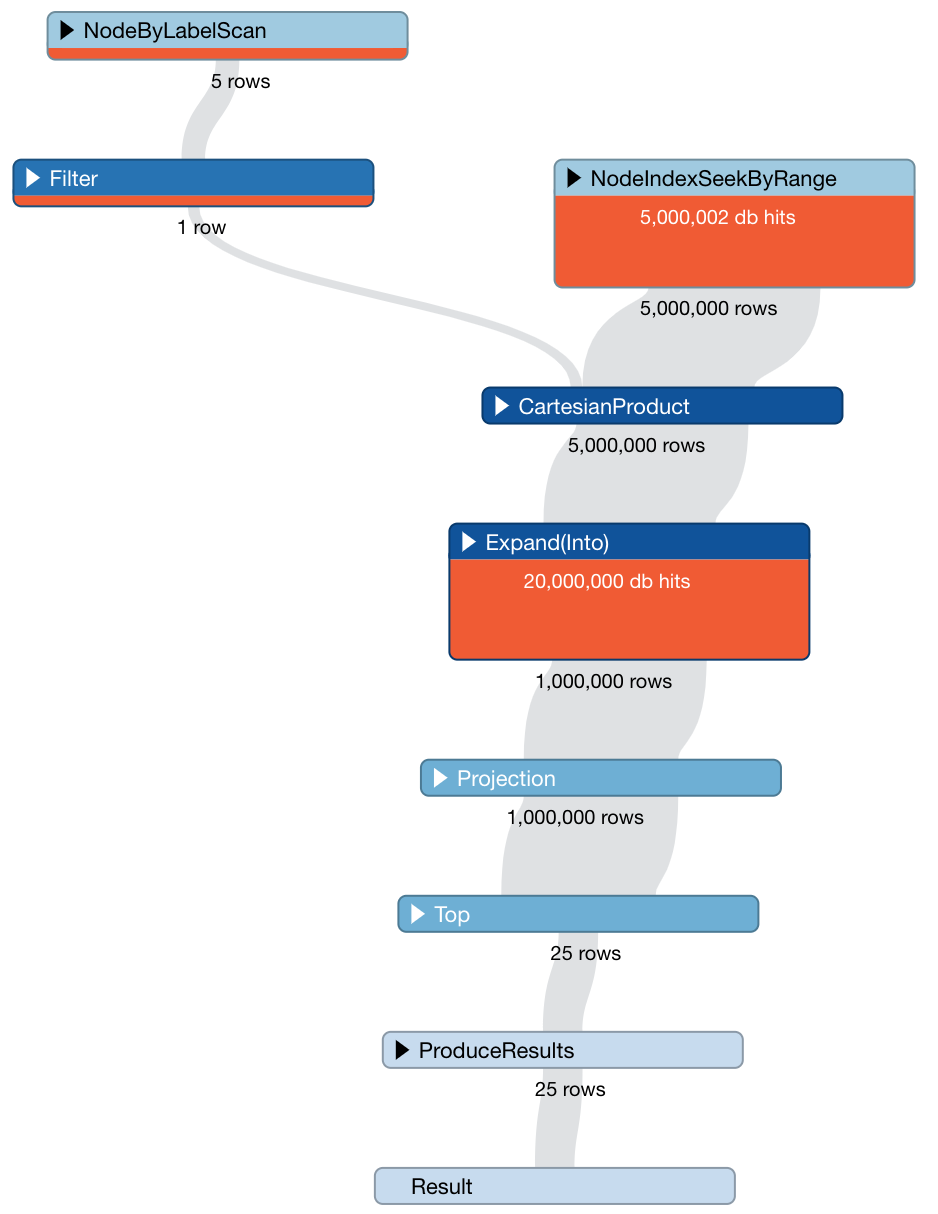
The profiler tells us: “Cypher version: CYPHER 3.5, planner: COST, runtime: SLOTTED. 25000013 total db hits in 9569 ms.” What! Over 9 seconds? We added an index and made it 9x slower than it was before. What is it doing? It is finding all the transactions sorted by date in the index, then seeing which if any connect to the user.
That was a terrible idea. But Michael Hunger has a trick up his sleeve to help us out. What we can do is tell Cypher to use a JOIN hint from the Transaction to the User.
PROFILE MATCH (u:User {username:"max"})-[:HAS_TX]->(tx:Transaction)
USING JOIN ON u
WHERE tx.date < datetime()
RETURN tx ORDER BY tx.date DESC
LIMIT 25
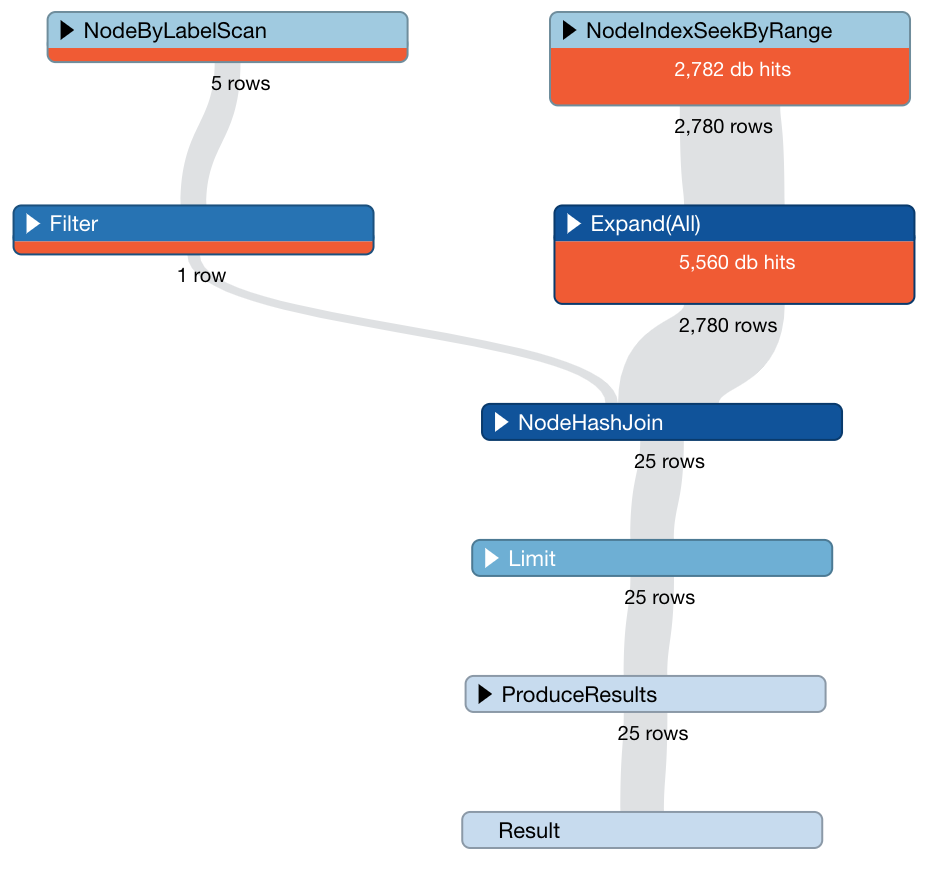
The profiler tells us: “Cypher version: CYPHER 3.5, planner: COST, runtime: SLOTTED. 8353 total db hits in 12 ms.” That’s way better. What is it doing? It’s going down the Transactions sorted by date in the index, and checking if they are connected to the user we want. Once it goes through a few thousand transactions it finds the top 25 in descending order for our user and stops. That’s amazing. But it has a problem. If we had many more users and transactions, and the user we cared about had lots of transactions but not 25 in the last few weeks we could be walking down a lot of transactions before we actually find the ones we want.
Can we go faster? Can we leverage the ordered indexes to find just the transactions that belong to one user? Of course, with composite indexes… oh no wait. In Neo4j 3.5 composite indexes aren’t sorted. Crap. If we somehow had one property that captured both the time and the user together. Every Node has an ID, so we could add the User node id as a property of the Transaction node, but that just avoids the traversal, we still need to sort them. Alright enough teasing, what’s the idea? Well… take a good look at this query:
MATCH (tx:Transaction) RETURN tx.date, tx.date.epochSeconds, (tx.date.epochSeconds / 10000000000.0) LIMIT 1

Do you see it? Do you see where this is headed? That’s right. I’m going to add the User Node ID which is an integer as the integer-part (or “characteristic” for the math folks) to the date of the transaction, expressed in epoch seconds divided by 10,000,000,000.0 so that it becomes the fractional-part (or the “mantissa” for the math folks).
MATCH (u:User {username:"max"})-[:HAS_TX]->(tx:Transaction)
SET tx.combined = ID(u) + (tx.date.epochSeconds/ 10000000000.0);
You’ll want to do this 4 more times, for the other users. Now let’s see what we have created:
MATCH (u:User {username:"max"})-[:HAS_TX]->(tx:Transaction)
RETURN tx.combined
LIMIT 1

Alright, now all we need in an index on the combined property of Transaction.
CREATE INDEX ON :Transaction(combined);
Give that a bit of time to finish populating and let’s get the node id of one of the users:
MATCH (u:User {username:"max"})
RETURN ID(u)
It returns “5000000”. We need the combined value that is greater than this number but less than this number plus one, so our query becomes:
PROFILE MATCH (tx:Transaction) WHERE 5000000 < tx.combined < (5000000 + 1) RETURN tx ORDER BY tx.combined DESC LIMIT 25

The profiler tells us: “Cypher version: CYPHER 3.5, planner: COST, runtime: SLOTTED. 26 total db hits in 1 ms.”

This is even faster than before, and we don’t have to worry about other users or transactions. It only took 26 db hits, that is the 25 records we wanted plus 1 for the road.
The one thing that kind sucks is that I have to know the user node id ahead of time. What if we just match it first and use it later. Yeah, let’s try that, but first let’s be smart about this and add an index on the username of the User.
CREATE INDEX ON :User(username);
That’ll make it easy to find the user, instead of having to do a Label scan we can find them in the index. So now our query looks like this:
PROFILE MATCH (u:User {username:"max"})
WITH ID(u) AS user_id, ID(u) + 1 AS user_id_plus_one
MATCH (tx:Transaction)
WHERE user_id < tx.combined < user_id_plus_one
RETURN tx
ORDER BY tx.combined DESC
LIMIT 25

The profiler tells us: “Cypher version: CYPHER 3.5, planner: COST, runtime: SLOTTED. 1000005 total db hits in 470 ms.” What? Oh no! What happened, what is this Apply thing, why does it ruin everything?

Well… we can build a stored procedure to do what we want, that would work. But if you come up with a way to trick cypher into doing the right index seek by range, please comment below!
