
If you’ve ever watched my talks about Neo4j, I tend to say we’re not very well optimized for Single Model queries where relationships aren’t considered. In fact, we’re kinda bad at it. Things got better when Composite Indexes were introduced, but we still have some limitations to deal with. Today we’re going to explore the issues and build our own faux “bitmap indexes” to get around this problem.
Let’s start by first creating some data. In this case, 1 million orders with various properties. I’m going to have multiple entries for some of the items in the arrays below to bias the distribution of the properties. If you are following along at home using Neo4j Desktop, make sure you are on Neo4j 4.1.x and have changed the heap settings to be “4G” or more.
WITH
["Unfulfilled", "Scheduled", "Shipped", "Shipped", "Shipped", "Shipped", "Returned"] AS statuses,
["Warehouse 1","Warehouse 2","Warehouse 3","Warehouse 3","Warehouse 3"] AS warehouses,
[true, false] AS booleans,
["Blue", "Green", "Green", "Green", "Green", "Red", "Red", "Red", "Yellow"] AS colors,
["Small", "Medium", "Medium", "Medium", "Large", "Large", "Large", "Extra Large"] AS sizes,
["Summer 2019", "Fall 2019", "Winter 2019", "Spring 2020", "Summer 2020", "Fall 2020"] AS seasons,
["Chicago", "Aurora","Rockford","Joliet",
"Naperville","Springfield", "Peoria", "Elgin",
"Waukegan", "Champaign", "Bloomington", "Decatur",
"Evanston", "Wheaton", "Belleville", "Urbana",
"Quincy", "Rock Island"] AS cities
FOREACH (r IN range(1,1000000) |
CREATE (o:Order {id : r,
status : statuses[r % size(statuses)],
warehouse : warehouses[r % size(warehouses)],
online : booleans[r % size(booleans)],
color : colors[r % size(colors)],
size : sizes[r % size(sizes)],
season : seasons[r % size(seasons)],
city : cities[r % size(cities)],
postal : 60400 + (r % size(cities)) % 100,
ordered_date : (date() - duration('P' + ceil(365 * rand()) + 'D')) }));
After this query runs, we have 1 million nodes and not a single index. Let’s start by finding the count of all the orders that are still “Unfulfilled” and the first 10 of them.
MATCH (o:Order) WHERE o.status = "Unfulfilled" RETURN COLLECT(o)[0..9] AS nodes, COUNT(*) AS size
I run this query a few times to warm up Cypher and the heap and I the best I get is 230ms. We can add the word “PROFILE” to the query to see what it is doing:

It is looking at every single order and checking the status property to see if it equals “Unfulfilled”. That’s terrible, so what can we do? We can create an Index:
CREATE INDEX FOR (n:Order) ON (n.status);
We will give that a few seconds to finish populating and try our query again:

Now it is using the index and getting the result in 17ms which is much better than the 230ms we started with. Great, but let’s keep going. What about “Unfulfilled” orders coming from “Warehouse 3” ?
MATCH (o:Order) WHERE o.status = "Unfulfilled" AND o.warehouse = "Warehouse 3" RETURN COLLECT(o)[0..9] AS nodes, COUNT(*) AS size
This query takes about 95ms. It is using the index we created for status and then filtering:

Ok, we can do better. Let’s create a composite index using both status and warehouse:
CREATE INDEX FOR (n:Order) ON (n.status, n.warehouse);
…and try our query again:

Now it is using the composite index and returning in about 21ms which is much better than the 95ms we started with. Let’s keep going. What about “Unfulfilled” orders coming from “Warehouse 3” purchased online?
MATCH (o:Order) WHERE o.status = "Unfulfilled" AND o.warehouse = "Warehouse 3" AND o.online = true RETURN COLLECT(o)[0..9] AS nodes, COUNT(*) AS size

It’s using the composite index of status and warehouse, and filtering on the online field. This comes in at about 74ms… ok so let’s create yet another composite index with all 3 properties this time:
CREATE INDEX FOR (n:Order) ON (n.status, n.warehouse, n.online);
…and once it’s populated, we try the query one more time:

Now it is using this composite index of 3 properties and returning in about 17ms, much better than the 74ms we started with that used the composite index of 2 properties.
Before you fall asleep, let’s spice things up a bit. What if that 3rd condition was an “OR” instead?
MATCH (o:Order) WHERE (o.status = "Unfulfilled" AND o.warehouse = "Warehouse 3") OR o.online = true RETURN COLLECT(o)[0..9] AS nodes, COUNT(*) AS size

We’ve slowed way down to about 765ms and are no longer using the indexes at all. Crap, what do we do now? Well… how about we create another index on Order for the online property by itself?
CREATE INDEX FOR (n:Order) ON (n.online);
…and try our query one more time:

It’s creating a Union between the nodes where the online property is true…and the status is “Unfulfilled” and later on filtering for “Warehouse 3” or online = true… that’s a bit weird and less than optimal at 241ms. Maybe it is getting confused, what we want it to do is to use the two indexes we created earlier and then AND them together. Maybe an Index Hint would help?
MATCH (o:Order) USING INDEX o:Order(status, warehouse) WHERE (o.status = "Unfulfilled" AND o.warehouse = "Warehouse 3") OR o.online = true RETURN COLLECT(o)[0..9] AS nodes, COUNT(*) AS size
Unfortunately it doesn’t know what to do with this hint and gives us this error.
Failed to fulfil the hints of the query. Could not solve these hints: `USING INDEX o:Order(status, warehouse)`
Yes, the engineers who work on Cypher are the type of people who write “Colour” instead of “Color” and “Fulfil” instead of “Fulfill”, but let’s forgive that for now. What about NOTs? Can we handle nots?
MATCH (o:Order) WHERE o.status = "Unfulfilled" AND o.warehouse = "Warehouse 3" AND NOT (o.online = true) RETURN COLLECT(o)[0..9] AS nodes, COUNT(*) AS size

Doesn’t look like it. It’s using the two property composite index and filtering again taking about 69ms.
Maybe composite indexes is the wrong approach. What if we tried creating additional labels?
MATCH (o:Order) WHERE o.status = "Unfulfilled" SET o:Unfulfilled; MATCH (o:Order) WHERE o.warehouse = "Warehouse 3" SET o:Warehouse_3; MATCH (o:Order) WHERE o.online = true SET o:Online;
Let’s restart by finding the count of all the orders that are still “Unfulfilled” and the first 10 of them.
MATCH (o:Unfulfilled) RETURN COLLECT(o)[0..9] AS nodes, COUNT(*) AS size
This query comes in at 6ms. Much better than the 17ms for the indexed version and 230ms for the unindexed version. Let’s keep going. What about “Unfulfilled” orders coming from “Warehouse 3” ?
MATCH (o:Unfulfilled:Warehouse_3) RETURN COLLECT(o)[0..9] AS nodes, COUNT(*) AS size
We’re at about 15ms, better than the 21ms and 95ms we saw earlier. Keep them coming. What about “Unfulfilled” orders coming from “Warehouse 3” purchased online?
MATCH (o:Unfulfilled:Warehouse_3:Online) RETURN COLLECT(o)[0..9] AS nodes, COUNT(*) AS size
This one clocks in at 20ms, a tiny bit slower than the 17ms for the 3 property composite index, but better than the 74ms of the 2 property composite index. What about ORs?
CALL {
MATCH (o:Unfulfilled:Warehouse_3)
RETURN o
UNION MATCH (o:Online)
RETURN o
} RETURN COLLECT(o)[0..9] AS nodes, COUNT(*) AS size
It’s coming in at 99ms which beats the 241ms we had earlier. Ok what about NOTs?
MATCH (o:Unfulfilled:Warehouse_3) WHERE NOT o:Online RETURN COLLECT(o)[0..9] AS nodes, COUNT(*) AS size
This query comes in at 19ms which beats the 69ms we had earlier.
Maybe this labels idea has some legs. Let’s increase the requirements. How would we deal with dates on the “ordered_date” property? We could create a label for each date and in the case of range queries just use UNION like before.
MATCH (o:Order) WHERE o.ordered_date = date("2020-08-13") SET o:Date2020_08_13;
MATCH (o:Order) WHERE o.ordered_date = date("2020-08-12") SET o:Date2020_08_12;
MATCH (o:Order) WHERE o.ordered_date = date("2020-08-11") SET o:Date2020_08_11;
MATCH (o:Order) WHERE o.ordered_date = date("2020-08-10") SET o:Date2020_08_10;
MATCH (o:Order) WHERE o.ordered_date = date("2020-08-09") SET o:Date2020_08_09;
Let’s find all the unfulfilled orders from warehouse 3 on August 8th – August 11th:
MATCH (o:Unfulfilled:Warehouse_3) WHERE o:Date2020_08_09 OR o:Date2020_08_10 OR o:Date2020_08_11 RETURN COLLECT(o)[0..9] AS nodes, COUNT(*) AS size
The query clocks in at just 8ms. What does it do? It figures out that the date labels have a lower cardinality than Unfulfilled and Warehouse_3, so it uses those first, combines them and then filters. That’s pretty smart:
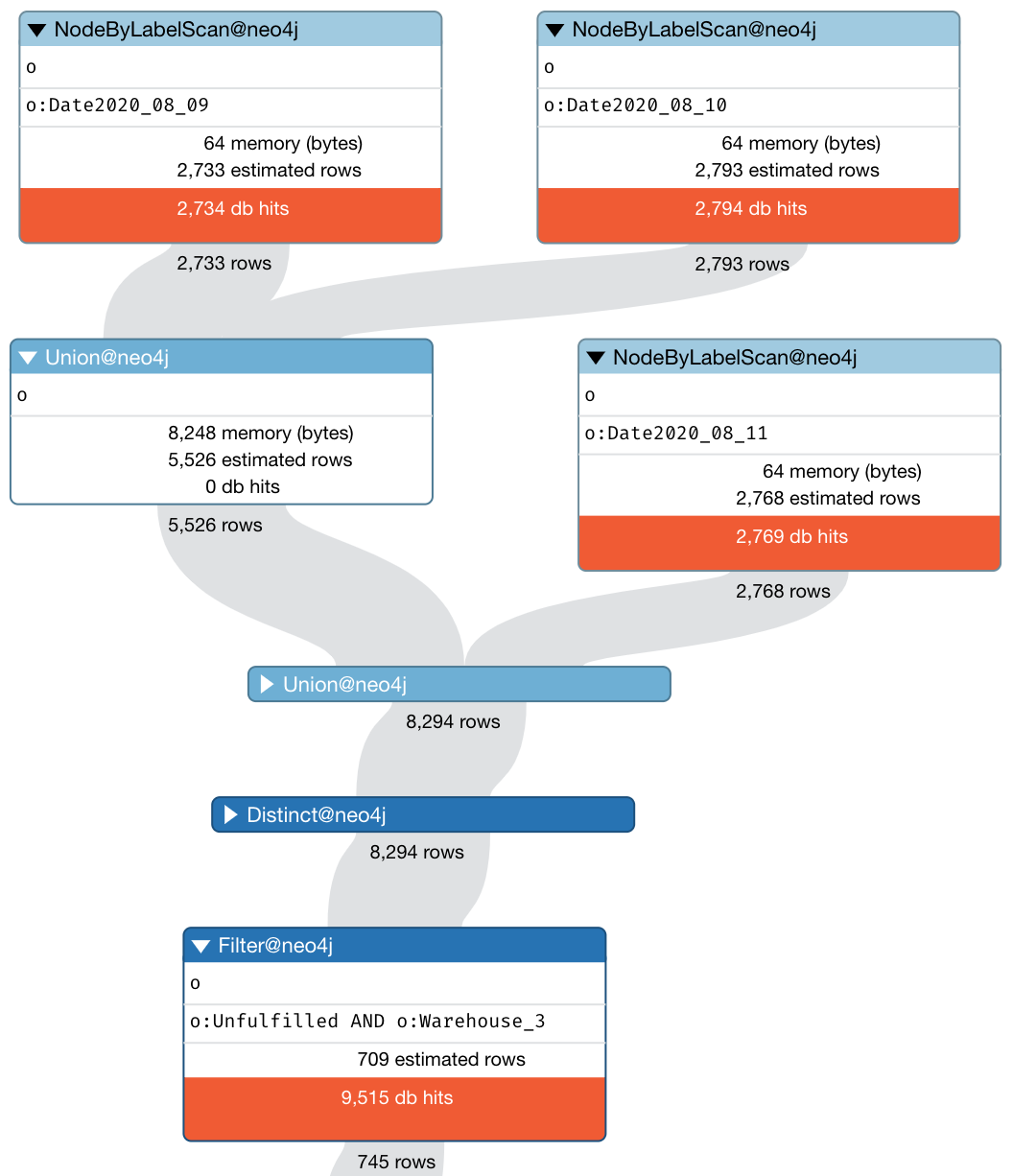
Ok so far so good, but what about finding all the unfulfilled orders from warehouse 3 before August 9th. We could cheat and use this query which clocks in at 52ms.
MATCH (o:Unfulfilled:Warehouse_3) WHERE NOT(o:Date2020_08_09 OR o:Date2020_08_10 OR o:Date2020_08_11 OR o:Date2020_08_12 OR o:Date2020_08_13) RETURN COLLECT(o)[0..9] AS nodes, COUNT(*) AS size
But that doesn’t seem very fair since date labels will keep growing every day and probably make the query perform worse over time. So what are our options? We can create an index on ordered_date:
CREATE INDEX FOR (n:Order) ON (n.ordered_date);
Then try this query:
MATCH (o:Order)
WHERE o.ordered_date < date('2020-08-09')
AND o:Unfulfilled:Warehouse_3
RETURN COLLECT(o)[0..9] AS nodes, COUNT(*) AS size
But it’s terrible, coming in at 298ms. It performs a NodeIndexSeekByRange and then the label filters:
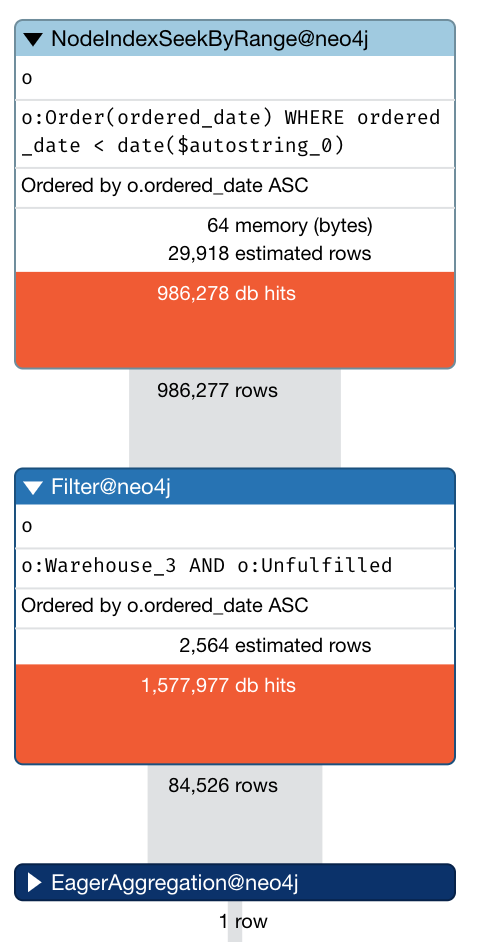
Ok so that index didn’t really help, what if we just ignore it and filter after the labels?
MATCH (o:Unfulfilled:Warehouse_3)
WHERE o.ordered_date < date('2020-08-09')
RETURN COLLECT(o)[0..9] AS nodes, COUNT(*) AS size
That query finishes in 133ms, so that’s much better but still not great.
What if we want to further filter on orders over 50.00?
MATCH (o:Unfulfilled:Warehouse_3)
WHERE o.ordered_date < date('2020-08-09') AND o.amount > 50.0
RETURN COLLECT(o)[0..9] AS nodes, COUNT(*) AS size
We’ve jumped to 150ms. We can’t really try the label each value trick on amount since it could be any value. We could partition it by ranges, but that’s starting to get complicated. Maybe we’ve reached our limits with what we can do with out of the box Neo4j capabilities?

Just kidding. We never give up. When the going gets tough, the tough get coding. So let’s go.
In Neo4j, Labels are kinda like bitmap indexes, but not quite. In Neo4j labels are implemented using a b-tree of values, where each value is a long (64-bits) where each set bit represents a node id using entityIdRange + bitOffset. But we don’t have to just use what Neo4j gives us. We can build our own “bitmap indexes” with a stored procedure.
Let’s imagine we’ve already written it and it takes 4 parameters. The Label we are going to filter, a map representing the boolean logic for our filter, a limit and an offset so we can paginate. So the interface is like this:
CALL com.maxdemarzi.boolean.filter(label, query, limit, offset);
…and it yields a “size” value which is the total size of the results of the filter and a “nodes” value which is the list of nodes based on the limit and offset.
CALL com.maxdemarzi.boolean.filter("Order", {not:false, and:[
{property: "status", values: ["Unfulfilled"], not: false}
]}, 10)
After the first time you run this query, it runs in about 4ms vs 17ms in Cypher using the property index we created on status.
CALL com.maxdemarzi.boolean.filter("Order", {not:false, and:[
{property: "status", values: ["Unfulfilled"], not: false},
{property: "warehouse", values: ["Warehouse 3"], not: false}
]}, 10)
After the first time you run this query, it runs in about 4ms vs 21ms in Cypher using a 2 property composite index.
CALL com.maxdemarzi.boolean.filter("Order", {not:false, and:[
{property: "status", values: ["Unfulfilled"], not: false},
{property: "warehouse", values: ["Warehouse 3"], not: false},
{property: "online", values: [true], not: false}
]}, 10);
After the first time you run this query, it runs in about 4ms vs 17ms in Cypher using a 3 property composite index.
CALL com.maxdemarzi.boolean.filter("Order", {not:false, and:[
{or:[{and:[
{property: "status", values: ["Unfulfilled"], not: false},
{property: "warehouse", values: ["Warehouse 3"], not: false}
]},{and:[
{property: "online", values: [true], not: false}
]}
]}
]}, 10);
After the first time you run this query, it runs in about 4ms vs 241ms in Cypher which could not use the two indexes and OR them together. Let’s change the online to be a “AND NOT” instead:
CALL com.maxdemarzi.boolean.filter("Order", {not:false, and:[
{property: "status", values: ["Unfulfilled"], not: false},
{property: "warehouse", values: ["Warehouse 3"], not: false},
{property: "online", values: [true], not: true}
]}, 10)
After the first time you run this query, it runs in about 4ms vs 65ms in Cypher.
See where we’re going with this? Pretty much all the queries finish in about 4ms once the faux bitmap indexes are built.
What about Range queries? I’m working on it still, I’ll finish up and do a part 2 of this blog post where I’ll go over the code. If you want to take a peek at the work in progress you can checkout the github repository.
