
If you haven’t read part 1 and part 2 then do that first or you’ll have no clue what I’m doing, and I’d like to be the only one not knowing what I’m doing.
We’ve built the beginnings of this database but so far it’s just a library and for it to be a proper database we need to be able to talk to it. Following the Neo4j footsteps, we will wrap a web server around our database and see how it performs.
There are a ton of Java based frameworks and micro-frameworks out there. Not as bad as the Javascript folks, but that still leaves us with a lot of choices. So as any developer would do I turn to benchmarks done by other people of stuff that doesn’t apply to me, and you won’t believe what I found –scratch that, yes you will, I got benchmarks.
TechEmpower publishes web framework benchmarks every once in a while and these things are great. They have tons of languages, tons of frameworks, its all open source, so you can see exactly how it was put together. I used the filter to just a Java Framework, looked at the first test and started poking around.
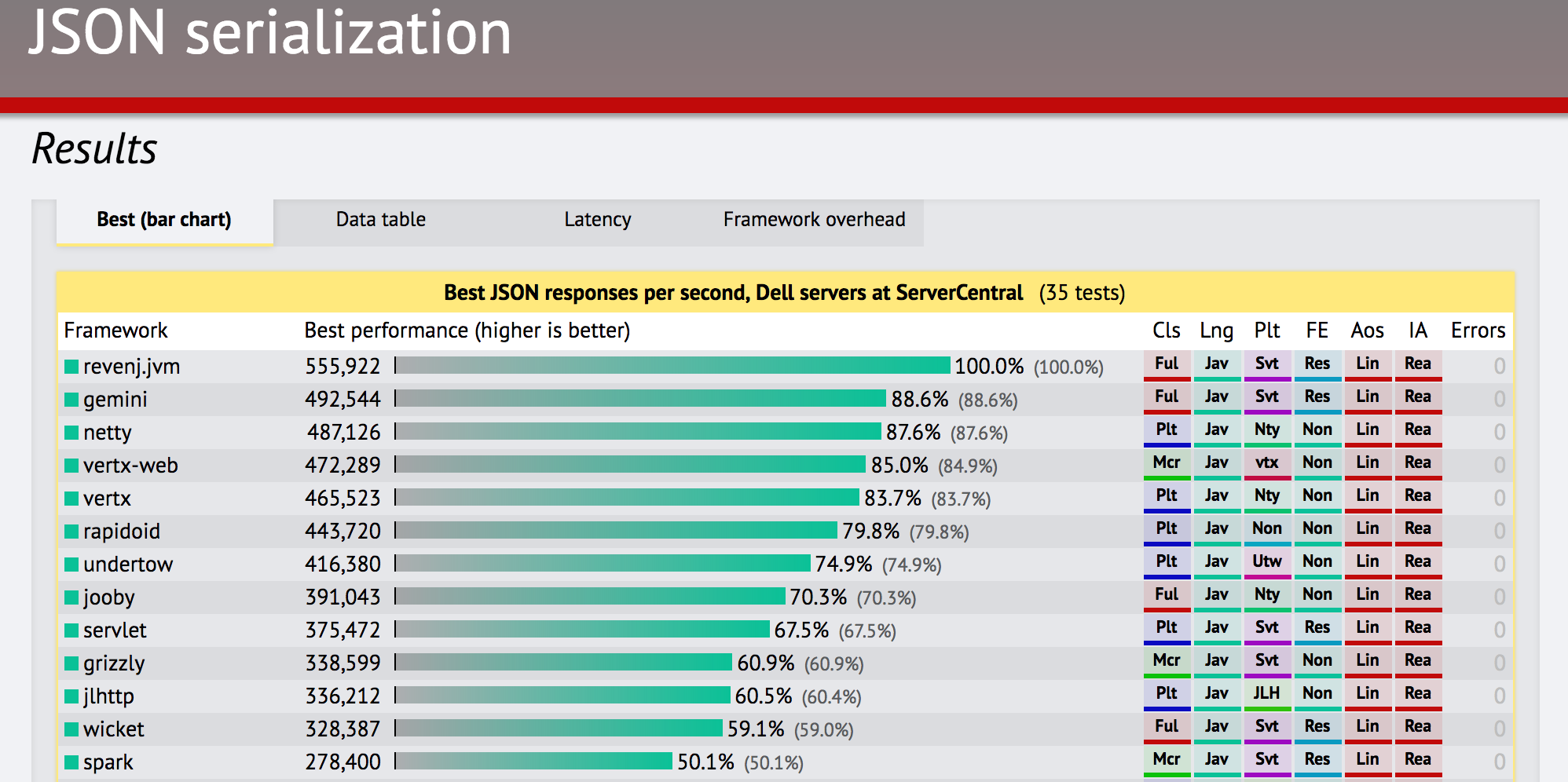
I never heard of revenj.jvm until then and it looked really interesting if you already had a database you wanted to connect to, not for building a database, so that one is out. A bunch of on the top looked overly complicated, so I skipped those. Rapidoid looked neat, but something about it turned me off. I think it was the boring documentation. I already used Undertow a bunch of times on this blog, so that’s out too. What’s this Jooby thing?

Do more, more easily? If I don’t know what I’m doing, but I can do more of it and more easily is that good or bad? It’s perfect. That’s what it is. Ok we’re using that. So what do we have to do? Looks like I need a Server class that extends Jooby, then a route and response and run it in main. Let’s go:
public class Server extends Jooby {
{
get("/", () -> "Hello World!");
}
public static void main(final String[] args) {
run(Server::new, args);
}
}
Great! It runs… now let’s see, those TechEmpower benchmarks clocked it doing a few hundred thousand requests per second on dedicated servers. Let’s see what my 4 year old laptop can do… because I’m not buying a new MacBook Pro, not without an escape key I’m not. Anyway, I wrote a little Gatling simulation that hits our server for 1 minute with 8 users continuously.
class GetRoot extends Simulation {
val conf = http.baseURL("http://localhost:8080")
val scn = scenario("Get Root")
.during(1 minutes) {
exec(http("index").get("/"))
}
setUp(scn.inject(atOnceUsers(8)))
.protocols(conf)
}
And here are the results:

264 requests per second? What is this garbage? Aren’t we missing a few zeros… something is wrong. Look at that mean latency… 0 ms that’s weird. Ok hold on let me RTFM on Jooby for a minute.
Jooby isn’t a traditional thread server where a HTTP request is bound to a thread.
In Jooby all the HTTP IO operations are performed in async & non blocking fashion. HTTP IO operations run in an IO thread (a.k.a event loop) while the application logic (your code) always run in a worker thread.
Ohhhhhh. OK. Let’s up the user count from 8 to something bigger like say 80 users, and try again.

Now that’s much better. 22k requests per second, with a mean latency of 2 ms. It’s not the almost 400k TechEmpower was getting, but my laptop doesn’t have 40 cores like their test system does. I tried this on a 4 core machine and got around 40k requests per second. That gives us about 10k r/s per core… we can work with this. So let’s start by giving our Server the ability to read and write nodes. In order to do that I have to hook in a GuancialeDB instance. I’ll make this class a singleton and add an “init” method to set the maximum nodes and relationships.
public static GuancialeDB init(Integer maxNodes, Integer maxRelationships) {
if (instance == null) {
synchronized (GuancialeDB.class) {
if (instance == null){
instance = new GuancialeDB(maxNodes, maxRelationships);
}
}
}
return instance;
}
Now in our Server, we can initialize it when we start up. It gets the parameters from a “conf/application.conf” file. See the Jooby manual for more details:
private static GuancialeDB db;
{
onStart(() -> {
Config conf = require(Config.class);
GuancialeDB.init(conf.getInt("guanciale.max_nodes"),conf.getInt("guanciale.max_rels"));
db = GuancialeDB.getInstance();
});
Ok, now our Server has access to a GuancialeDB instance. Let’s write getNode and postNode and make them return JSON. For this we will add the Jackson Mapper after adding a dependency for “jooby-jackson” in our pom.xml. We will make the API start with “db” and for getNode, it simply calls our instance with the passed in parameter value and returns that. For postNode we get our id, add a node to our instance with properties if they gave us any, set the status to 201 “created” and then reply with a call to getNode with the same id just to make sure we got what they asked for. I modified “addNode” so when it is given a String, it tries to turn it into a HashMap. Instead of storing direct Objects anymore we’ll use a default of {“value”: {object}} to avoid issues with converting to JSON and back.
// JSON via Jackson
use(new Jackson());
use("/db")
.produces(MediaType.json)
.get ("/node/:id", req -> db.getNode(req.param("id").value()))
.post("/node/:id", (req, rsp) -> {
String id = req.param("id").value();
db.addNode(id, req.body().toOptional().orElse("{}"));
rsp.status(201);
rsp.send(db.getNode(id));
});
Let’s write some tests to make sure this works. We will use REST Assured for our tests. I just started using it and so far I really like it, give it a shot if you’ve never heard of it. We will setup a JUnit test with Rule to start our Server, then use the “given/when/then” style tests:
@Rule
public JoobyRule app = new JoobyRule(new Server());
@Test
public void integrationTestCreateComplexPropertyNode() {
HashMap<String, Object> prop = new HashMap<>();
prop.put("property", "Value");
HashMap<String, Object> props = new HashMap<>();
props.put("city", "Chicago");
props.put("prop", prop);
given().
contentType("application/json").
body(props).
when().
post("/db/node/complexPropertiesNode").
then().
assertThat().
body("$", equalTo(props)).
statusCode(201);
}
Why is it that it takes so much more code to test functionality than to write it? But hey, you know what’s even worse? Documenting functionality. Luckily the trends in Java web frameworks is to have Swagger plug right in and take care of that for us. I added some comments to our endpoints, and configured it with:
new SwaggerUI()
.filter(route -> route.pattern().startsWith("/db"))
.install(this);
Now when I start the server and go to http://localhost:8080/swagger I get:
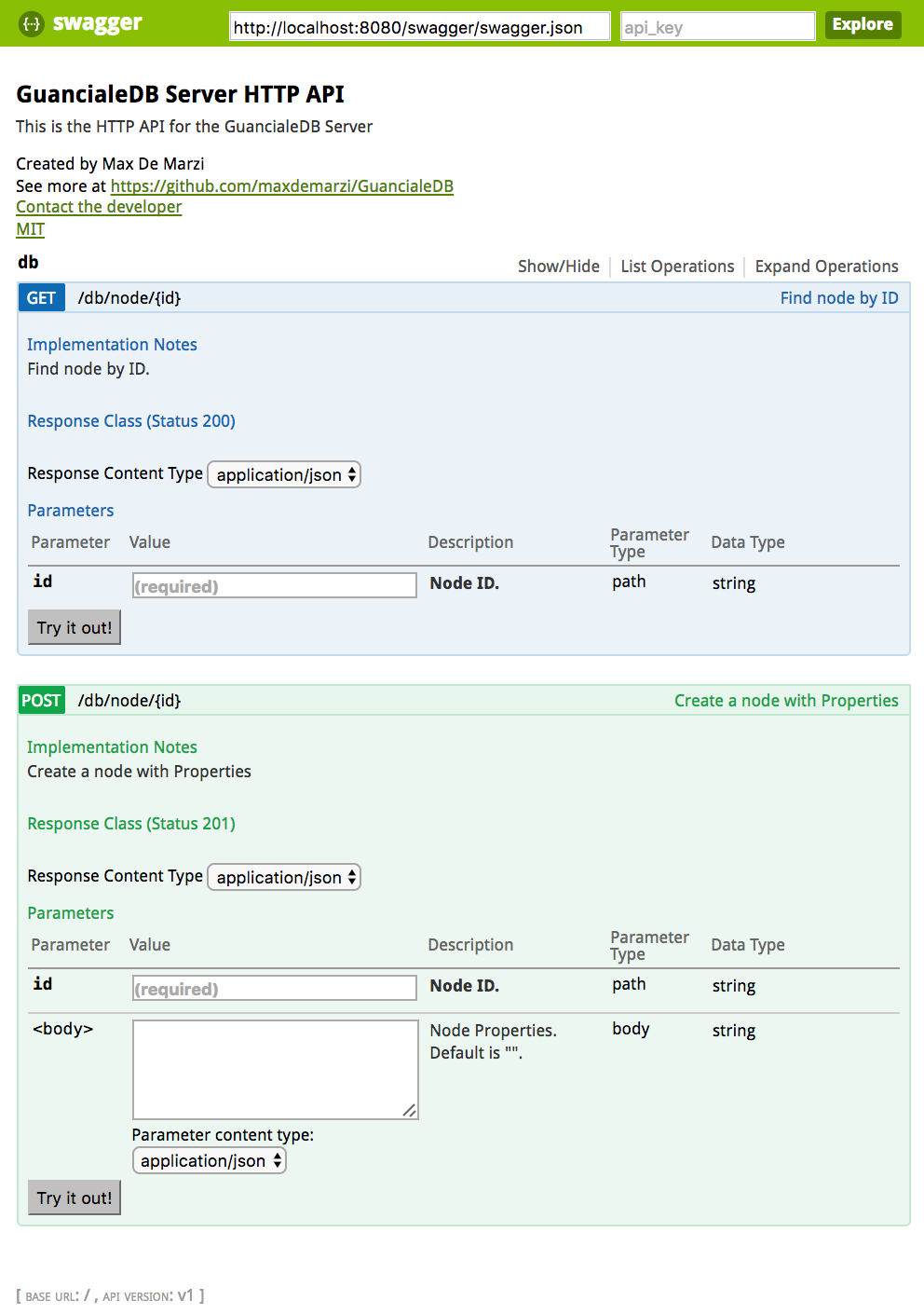
Pretty neat right? Alright so how fast is it now? I’m going to go ahead and use the Swagger UI page to create a node “max” with just one property {“name”:”Max”}. I can test and make sure it got there by using swagger again and yup all there. Now our Gatling test:
val scn = scenario("Get Node")
.during(1 minutes) {
exec(http("get node")
.get("/db/node/max")
.check(
jsonPath("$.name").is("Max"),
status.is(200))
)
}
We are hitting the “/db/node/:id” url with “max” as our parameter for 1 minute and checking that the name property I created returns in JSON and is equal to “Max”. How did we do?

Almost as fast as not doing anything at all. That’s all for now, source code is on github as always. Next time we’ll finish out the REST of the API, add some metrics, maybe add a Shell. We’ll see, then on to persistence and replication.

[…] On to Part 3 […]
[…] read parts 1, 2 and 3 before continuing or you’ll be […]
[…] again. I gave you an introduction to this framework on a previous blog post when we started out building our own multi model Database. If you want to follow along, open up the source code on github on another tab and flip back and […]