
Please read parts 1, 2 and 3 before continuing or you’ll be lost.
We started adding an HTTP server to our database last time and created just a couple of end points. Today we’ll finish out the rest of the end points. We’ll also be good open source developers by hooking in Continuous Integration , Test Coverage and Continuous Deployment.
It became too complex to keep all the http api routes in the Server class, luckily Jooby lets us break out functionality into multiple classes and include them like so:
use(new Node());
use(new NodeDegree());
use(new NodeProperties());
use(new Relationship());
use(new RelationshipProperties());
We could have gone MVC style, but I decided to keep it simple. Here is what the “get node property” end point looks like:
/*
* Get node property by key.
* @param id Node ID.
* @param key Node property
* @return Returns <code>200</code> with a single value or <code>404</code>
*/
.get("/node/:id/property/:key", req -> {
HashMap<String, Object> node = Server.db.getNode(req.param("id").value());
if (node == null) {
throw new Err(Status.NOT_FOUND);
} else {
if (node.containsKey(req.param("key").value())) {
return node.get(req.param("key").value());
}
throw new Err(Status.NOT_FOUND);
}
})
Those comments enable the Swagger integration to produce these beautiful docs:
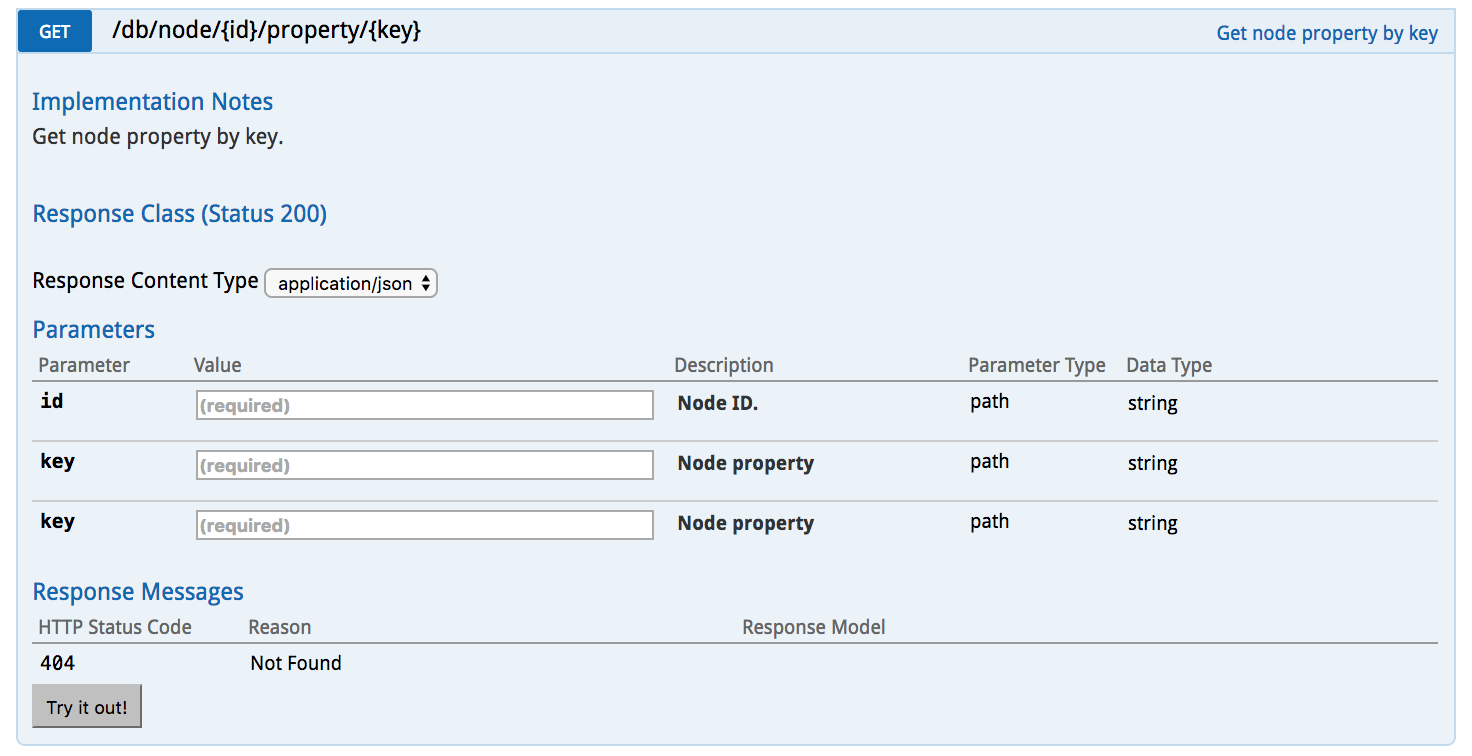
Now to test this one end point I have to create at least 3 tests. One for a node not being there, one for a node being there, but the property not being there and once for actually getting a node’s property without problem. This type of scenario plays out again and again. One mistake I made early was I was creating a new server for every test. I then realized I could make the tests faster by creating a single one per class and adding a clear method to our database so we could always start fresh. Now our tests begin with a “@ClassRule”:
private GuancialeDB db;
@ClassRule
public static JoobyRule app = new JoobyRule(new Server());
… and before each test we clean up the database and add some data if we wish:
@Before
public void setup() throws IOException {
db = GuancialeDB.getInstance();
db.clear();
HashMap<String, Object> properties = new HashMap<>();
properties.put("name", "Max");
properties.put("age", 37);
db.addNode("node1", properties);
The GuancialeDB “clear” method just wipes the nodes and relationships maps, as well as sets related to a new HashMap like so:
public void clear() {
nodes.clear();
relationships.clear();
related = new HashMap<>();
}
This keeps the tests nice and speedy without too much fuss. Here are 3 tests I talked about. First for the node not existing at all:
@Test
public void integrationTestGetNodePropertyNotThere() {
when().
get("/db/node/node0/property/not_there").
then().
assertThat().
statusCode(404);
}
Another for the node existing but the property missing:
@Test
public void integrationTestGetNodePropertyNotThereInvalidProperty() {
when().
get("/db/node/node1/property/not_there").
then().
assertThat().
statusCode(404);
}
Finally one for actually getting a valid property from an existing node.
@Test
public void integrationTestGetNodeProperty() {
when().
get("/db/node/node1/property/name").
then().
assertThat().
body(equalTo("\"Max\"")).
statusCode(200).
contentType("application/json;charset=UTF-8");
}
There are a metric ton more of these tests in the source code and I don’t always remember to run them locally when committing, so we’re gonna hook our project up with Continuous Integration, Continuous Deployment and Test Coverage. There are a few vendors in this space, but I am most familiar with Travis CI and Coveralls so we’ll use those. After registering with our github account and allowing them access to our github repo, we just need to add a “.travis.yml” file that looks like this:
sudo: required
language: java
jdk:
- oraclejdk8
services:
- docker
env:
global:
- COMMIT=${TRAVIS_COMMIT::8}
#DOCKER_USERNAME
#DOCKER_PASSWORD
after_success:
- mvn test jacoco:report coveralls:report
- docker login -u="$DOCKER_USERNAME" -p="$DOCKER_PASSWORD"
- export REPO=maxdemarzi/guancialedb
- export TAG=`if [ "$TRAVIS_BRANCH" == "master" ]; then echo "latest"; else echo $TRAVIS_BRANCH
; fi`
- docker build -f Dockerfile -t $REPO:$COMMIT .
- docker tag $REPO:$COMMIT $REPO:$TAG
- docker tag $REPO:$COMMIT $REPO:travis-$TRAVIS_BUILD_NUMBER
- docker push $REPO
We’ll also need to configure a couple of plugins in our pom.xml file to deal with test coverage.
<plugin>
<groupId>org.eluder.coveralls</groupId>
<artifactId>coveralls-maven-plugin</artifactId>
<version>${coveralls.version}</version>
</plugin>
<plugin>
<groupId>org.jacoco</groupId>
<artifactId>jacoco-maven-plugin</artifactId>
<version>${jacoco.version}</version>
<executions>
<execution>
<id>prepare-agent</id>
<goals>
<goal>prepare-agent</goal>
</goals>
</execution>
</executions>
</plugin>
I’m using JaCoCo here instead of Cobertura because Cobertura uses JavaNCSS and it won’t recognize Lambda expressions from Java 8 just yet. I was getting all kinds of these weird errors, because it ran into a “->{“.
[WARN] JavaNCSS got an error while parsing the java file /Users/maxdemarzi/Projects/GuancialeDB/src/main/java/com/maxdemarzi/server/RelationshipProperties.java ParseException in STDIN Last useful checkpoint: "com.maxdemarzi.server.RelationshipProperties" Encountered " ">" "> "" at line 29, column 74.
I’ll also need a Docker file:
FROM azul/zulu-openjdk:latest MAINTAINER Max De Marzi<maxdemarzi@gmail.com> EXPOSE 8080 COPY $ROOT/conf/application.conf /conf/application.conf COPY $ROOT/target/GuancialeDB-1.0-SNAPSHOT.jar GuancialeDB-1.0-SNAPSHOT.jar CMD ["java", "-jar", "GuancialeDB-1.0-SNAPSHOT.jar"]
I am using zulu-openjdk because there is no issue with licensing and they do a great job of certifying their builds.
Now when we push to github.com, our tests will be run on Travis CI:
Our test coverage will be reported to Coveralls:

Our docker image will be pushed to Docker Hub:
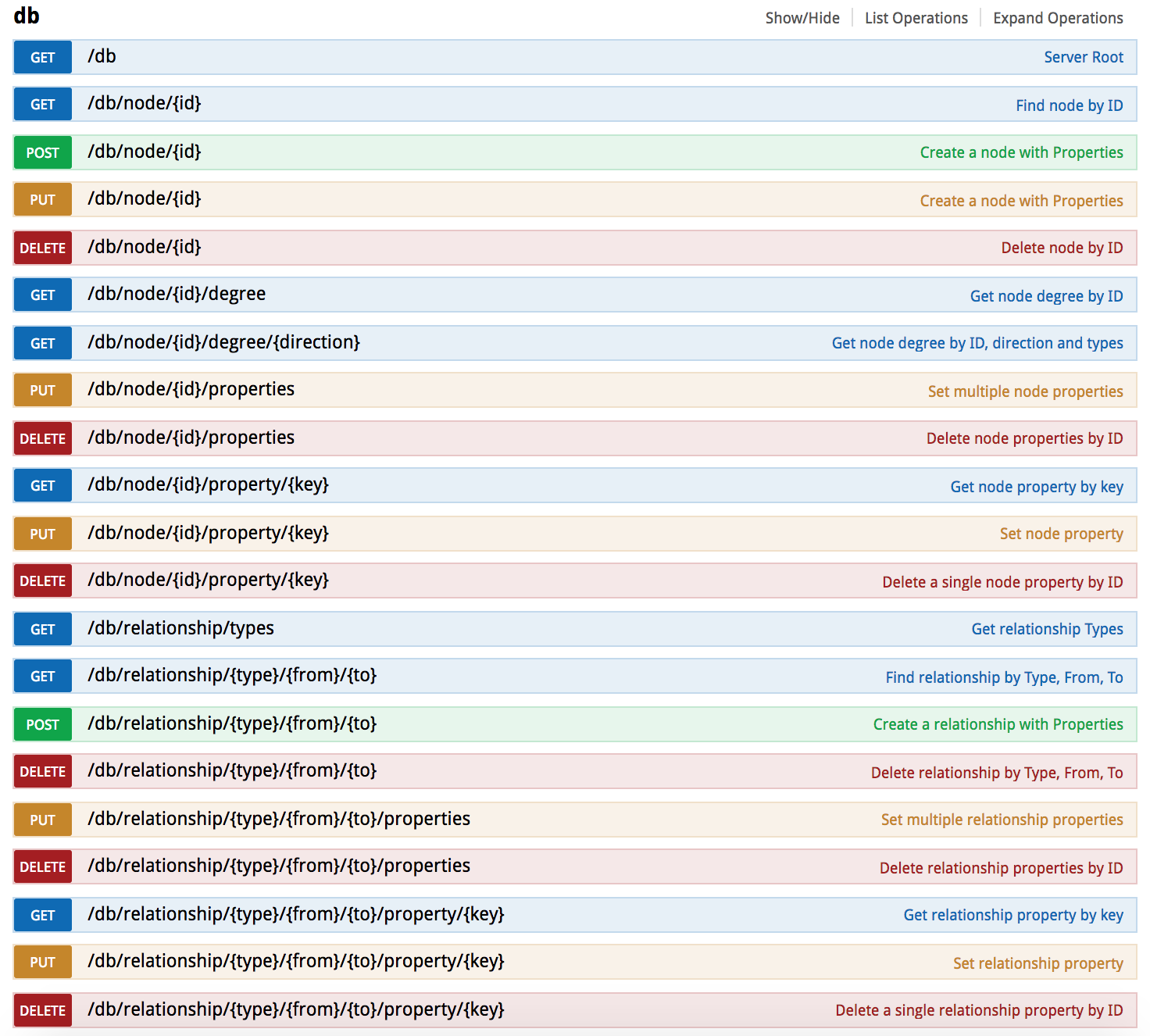
After a bit of somewhat tedious work our REST API currently looks like this:
But you don’t have to take my word for it. Grab the docker image and run it yourself right now. We’ll save metrics and the shell for another post since this one is already running long in the tooth. As always, source code is on github.
On to Part 5.

[…] In part 4 I promised metrics and a shell, so that’s what we’ll tackle today. We are lucky that the Metrics library can be plugged into Jooby without much effort… and double lucky that the Crash library can also be plugged into Jooby without much effort. This is what we are all about here because we’re a bunch of lazy, impatient developers who are ignorant of the limits of our capabilities and who would rather reuse open source code instead of falling victim to the “Not Invented Here” syndrome and do everything from scratch. […]