
What would you think if I ran out of time,
Would you stand up and walk out on me?
Lend me your eyes and I’ll write you a post
And I’ll try not to run out of memory.
Oh, I get by with a little help from my threads
Mm, I get high with a little help from my threads
Mm, gonna try with a little help from my threads
Today we are going to take a look at how to take a Neo4j traversal and split it up into lots of smaller traversals. I promise it will be electrifying.
We were faced with the problem of figuring out which parts of a power grid were electrified. Our traversal would start at a power supplier which produced electricity for the grid at an initial Voltage. Electricity on the grid goes from High Voltage to Low Voltage. As we traverse, if we run into equipment at a higher voltage than we had before we stop that branch of the traversal. If we run into off-switches at either end of the connections between equipment, we had to stop that branch of the traversal. This traversal would continue until it couldn’t branch anymore and we’d captured our objective of finding all the equipment that is energized by a power supplier.
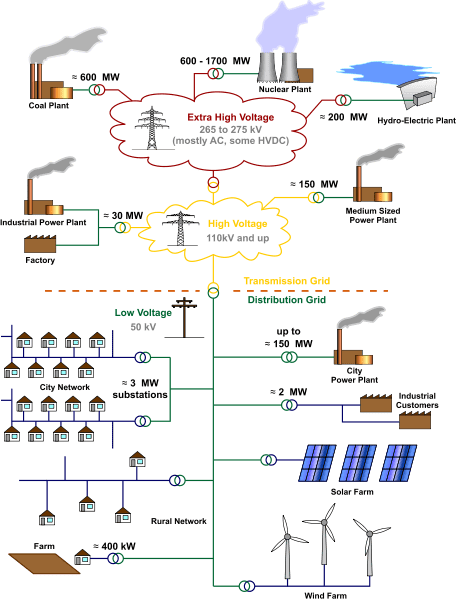
To make things interesting, we needed to handle a test graph of 20 million pieces of equipment in under 15 minutes, and another test graph of 200 million pieces of equipment in under 30 minutes. The real graph would end up with about 500 million pieces of equipment. We went about trying to model this in different ways, and ultimately settled on a very simple model optimized for this purpose.
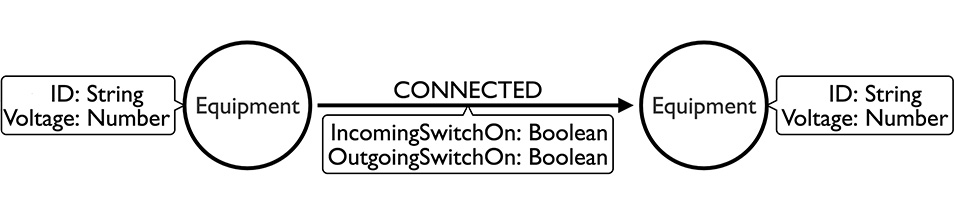
Every piece of equipment is just a node, and it is connected to other pieces of equipment by a single relationship with two boolean properties. If either one of these is false, then the traversal cannot continue down this branch. If they are both true, then we check the voltage on the second node and allow it if it is the same or lower.
Let’s take a look at how we would write this Traversal using the Traversal API. First we would get all the starting equipment nodes (yes, there could be multiple). For each we would start a traversal by getting the voltage of our initial node and using that as our initial branch state with a custom expander and evaluator (I’ll talk about these in a second). Then for every path, we look at the last node and if we haven’t seen it globally (across the multiple traversals, remember we can have many starting points) then we add it to the result set.
Set<Node> startingEquipment = new HashSet<>();
Set results = new HashSet<>();
ArrayList<Long> skip = new ArrayList<>();
try (Transaction tx = db.beginTx()) {
((Collection) input.get("ids")).forEach(
(id) -> startingEquipment.add(db.findNode(Labels.Equipment, "equipment_id", id)));
if (startingEquipment.isEmpty()) {
throw Exceptions.equipmentNotFound;
}
startingEquipment.forEach(bus -> {
InitialBranchState.State<Double> ibs;
ibs = new InitialBranchState.State<>((Double) bus.getProperty("voltage", 999.0), 0.0);
TraversalDescription td = db.traversalDescription()
.depthFirst()
.expand(expander, ibs)
.uniqueness(Uniqueness.NODE_GLOBAL)
.evaluator(evaluator);
for (org.neo4j.graphdb.Path position : td.traverse(bus)) {
Node endNode = position.endNode();
if (!skip.contains(endNode.getId())) {
results.add(position.endNode().getProperty("equipment_id"));
skip.add(endNode.getId());
}
endNode.setProperty("Energized", true);
}
});
tx.success();
}
return Response.ok().entity(objectMapper.writeValueAsString(results)).build();
Now, let’s talk about the custom expander. It needs to check the voltage of where we just arrived and make sure we can continue by comparing the voltage and updating the branch state. Then it must continue with any relationships that have both our switch states to on. Like this:
public class EnergizationExpander implements PathExpander<Double> {
@Override
public Iterable<Relationship> expand(Path path, BranchState<Double> branchState) {
ArrayList<Relationship> rels = new ArrayList<>();
Node endNode = path.endNode();
Double voltage = (Double) endNode.getProperty("voltage", 999.0);
if (voltage <= branchState.getState()) {
// Set the new voltage
branchState.setState(voltage);
endNode.getRelationships(Direction.OUTGOING, RelationshipTypes.CONNECTED).forEach(rel -> {
if ((Boolean)rel.getProperty("incoming_switch_on", false) &&
(Boolean)rel.getProperty("outgoing_switch_on", false)) {
rels.add(rel);
}
});
}
return rels;
}
Finally the custom evaluator must check the last node and confirm that the voltage is lower or equal to the previous voltage in order to be included.
public class EnergizationEvaluator implements PathEvaluator<Double> {
@Override
public Evaluation evaluate(Path path, BranchState<Double> branchState) {
// Path with just the single node, ignore it and continue
if (path.length() == 0 ) {
return Evaluation.INCLUDE_AND_CONTINUE;
}
// Make sure last Equipment voltage is equal to or lower than previous voltage
Double voltage = (Double) path.endNode().getProperty("voltage", 999.0);
if (voltage <= branchState.getState()) {
return Evaluation.INCLUDE_AND_CONTINUE;
} else {
return Evaluation.EXCLUDE_AND_PRUNE;
}
}
That’s it. It’s not terribly complicated, but the problem is performance. It was taking hours on the 20 million equipment dataset and we needed it to be under 15 minutes. So what do we do? Well one of the things we can do is go to a lower level API… even to the super secret low level SPI. I tried that, and it was much better but not good enough. One error we see all the time when people build their own Neo4j extensions is that they hold the result set in memory and then release it all at the end of the traversal. That increases memory pressure and generally slows you down. It’s better to stream out the results right away. So I did that and it was under 15 minutes (finally) but we could do better. We had to in order to deal with the large test dataset anyway.
I’m gonna multi-thread this sucka. But how? My first attempt using Futures resulted in worse times than before and I traced the culprit to each future having to start its own transaction in order to interact with the graph. So what we really need is long running threads that start a single transaction and do all their work there. In addition, as the work is produced it needs to be streamed out. Ok, so how did I do this… well, in not the most elegant way that’s for sure. We start by creating 2 Queues. One queue will contain our work, and the second will have our results.
BlockingQueue<Work> queue = new LinkedBlockingQueue<>(); BlockingQueue<String> results = new LinkedBlockingQueue <>();
We’ll start one worker per core, passing in both queues when we create them.
public static final int CPUS = Runtime.getRuntime().availableProcessors();
for (int i = 0; i < CPUS; ++i) {
service.execute(new Worker(queue, results));
}
We will get all the starting points like before, and add them to our work queue. The Work object just holds the node id and the voltage of that node id. We are keeping “branch state” manually.
for (String equipmentId : (Collection<String>) input.get("ids")) {
Cursor<NodeItem> nodes = ops.nodeCursorGetFromUniqueIndexSeek(descriptor, equipmentId);
if (nodes.next()) {
long equipmentNodeId = nodes.get().id();
energized2.add((int) equipmentNodeId);
jg.writeString(equipmentId);
queue.add(new Work(equipmentNodeId, (Double)ops.nodeGetProperty(equipmentNodeId, propertyVoltage)));
}
nodes.close();
}
Before we take a look at the work being done, let’s talk about the results. I need a way to kill these threads and close things down. So what I decided to do is to have the results queue poll in a loop for up to 1 second. If there is an value there then great, we stream it out. If not we end our traversal. Remember that results are being added to the queue as work is being done, so if a whole second passes with no new results, it’s pretty much done. Neo4j can traverse millions of relationships per second per core, so I think my assumption is good. Worst case we can up this a bit.
JsonGenerator jg = objectMapper.getJsonFactory().createJsonGenerator(os, JsonEncoding.UTF8);
jg.writeStartArray();
String result;
do {
result = null;
try {
result = results.poll(1, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
if (result == null) {
break;
}
jg.writeString(result);
} while (true);
jg.writeEndArray();
jg.flush();
jg.close();
service.shutdown();
service.awaitTermination(5, TimeUnit.SECONDS);
Alright, let’s look at the Worker now. In the Worker “run” method, we are looping taking from the work queue. The “take()” method blocks, so if there is nothing to do it will wait until something appears.
try (Transaction tx = Energization.dbapi.beginTx()) {
ThreadToStatementContextBridge ctx = Energization.dbapi.getDependencyResolver().resolveDependency(ThreadToStatementContextBridge.class);
ReadOperations ops = ctx.get().readOperations();
do {
Work item = this.processQueue.take();
this.processEntry(item, ops);
count++;
} while (true);
The processEntry method does the real work. Just like before we check the relationship properties before continuing and if they are both set to true, we verify the voltage is less than or equal to our current voltage. If it all looks good, it adds the new equipment to the results queue, and creates a new work item with the new equipment and the new voltage as properties:
private void processEntry(Work work, ReadOperations ops) throws EntityNotFoundException, InterruptedException, IOException {
relationshipIterator = ops.nodeGetRelationships(work.getNodeId(), org.neo4j.graphdb.Direction.BOTH);
while (relationshipIterator.hasNext()) {
c = ops.relationshipCursor(relationshipIterator.next());
if (c.next()
&& (boolean) c.get().getProperty( Energization.propertyIncomingSwitchOn)
&& (boolean) c.get().getProperty( Energization.propertyOutgoingSwitchOn)) {
long otherNodeId = c.get().otherNode(work.getNodeId());
if (!energized2.contains((int) otherNodeId)) {
double newVoltage = (double) ops.nodeGetProperty(otherNodeId, Energization.propertyVoltage);
if (newVoltage <= (double) work.getVoltage()) {
if(energized2.checkedAdd((int) otherNodeId)) {
results.add((String) ops.nodeGetProperty(otherNodeId, Energization.propertyEquipmentId));
processQueue.put(new Work(otherNodeId, newVoltage));
}
}
}
}
}
}
So what was the final verdict… On my 4 core desktop, the 20 million equipment dataset returns in under a minute, and the 200 million equipment dataset in 15 minutes. Well under our requirements. On a proper 32 or 64 core server, this will be lightning fast. As always, the source code is on github. Traversal Multi-Threading. When you absolutely, positively got to kill every core in the server, accept no substitutes.
Now if that looks way too complicated… no worries. I hear we might see this fellow below learn some new tricks.


[…] my word for it. Try it yourself. Code is on github as always. Now we could go even faster if we multi-threaded the traversal. I’ve already shown you how to do that, so I’ll leave it as an exercise for the […]
[…] model, what I like to do next is build an API. In a typical POC bootcamp we may be asked to solve a single very complex or time sensitive traversal, or we be asked to help build a Minimum Viable Product. In that short time, the most we can really […]