
Last week I was helping out a user who was seeing lots of error messages in their application logs when connecting to Neo4j Aura. So I did like any good developer and I asked the all knowing all powerful google how to cleanse your Aura, and guess what it told me…
- Take a walk in the rain.
- Cleanse your aura by smudging it with healing herbs.
- Take a cleansing bath.
- Visualize the auras of others.
- Surround yourself with positive energies, and keep your aura close to you.
- Surround yourself with sunlight.
- Try and strengthen your aura with a simple exercise.
- Lastly, drink some bleach
Ok. I may have heard that last one on TV, but regardless they tried all those tips and they didn’t work. So I asked our Aura team what they suggested and they came up with upgrading the Neo4j Java driver they were using from 1.7.5 to 4.0.1. Tried that but it didn’t help. Then they suggested using “Transaction Functions” for their queries. What the heck are those? Well if you go to the the Aura “connect” tab in your console you’ll see that’s how they prefer you run your queries. These transaction functions will automatically recover from errors, retry queries and are able to be load balanced.
So they did all that… and they were still seeing “ServiceUnableException” errors and the dreaded:
WARNING: Transaction failed and will be retried in 33707ms
WARNING: Transaction failed and will be retried in 4230ms
WARNING: Transaction failed and will be retried in 1927ms
WARNING: Transaction failed and will be retried in 1161ms
WARNING: Transaction failed and will be retried in 30829ms
WARNING: Transaction failed and will be retried in 37952ms
WARNING: Transaction failed and will be retried in 18210ms
WARNING: Transaction failed and will be retried in 6454ms
WARNING: Transaction failed and will be retried in 14559ms
What did those mean? They mean that due to some connection issues between Aura and their app, the driver was waiting up to almost 38 seconds in some cases before retrying the transaction. Retrying the transaction is better than just getting an error, but in 38 seconds, the user had left their site, gone to their competitors and were half way into typing out their credit card information. We desperately needed to fix this. So I put on my detective hat and got to work.

The Aura administration page has some useful information that can help us determine what may be causing the issues. Was the database instance size they picked too small for their dataset? How would we know that? By looking at the Page Cache Miss Ratio and seeing if they numbers were high. Take a look:
That’s a negative. They were appropriately sized, maybe even bigger than they needed. OK. What else? How about their queries? Did they have long running queries that were causing issues? Maybe a missing index or a “death star query”. That’s when you have unbounded path queries in your MATCH statement like -[*]- . Take a look:
That’s a negative. The average query time is close to nothing and the peak queries are less than 30ms. Could something on the server be causing out of memory issue? We already saw they were appropriately sized, so this is doubtful but take a look:
That’s a negative. Ok… Could we have a run away query causing garbage collection? Let’s take a look:
That’s a negative as well. It’s completely flat. Ok, so memory seems fine, what about CPU? We saw the query times were super fast, but could they maybe have too many of them coming in at the same time? Take a look:
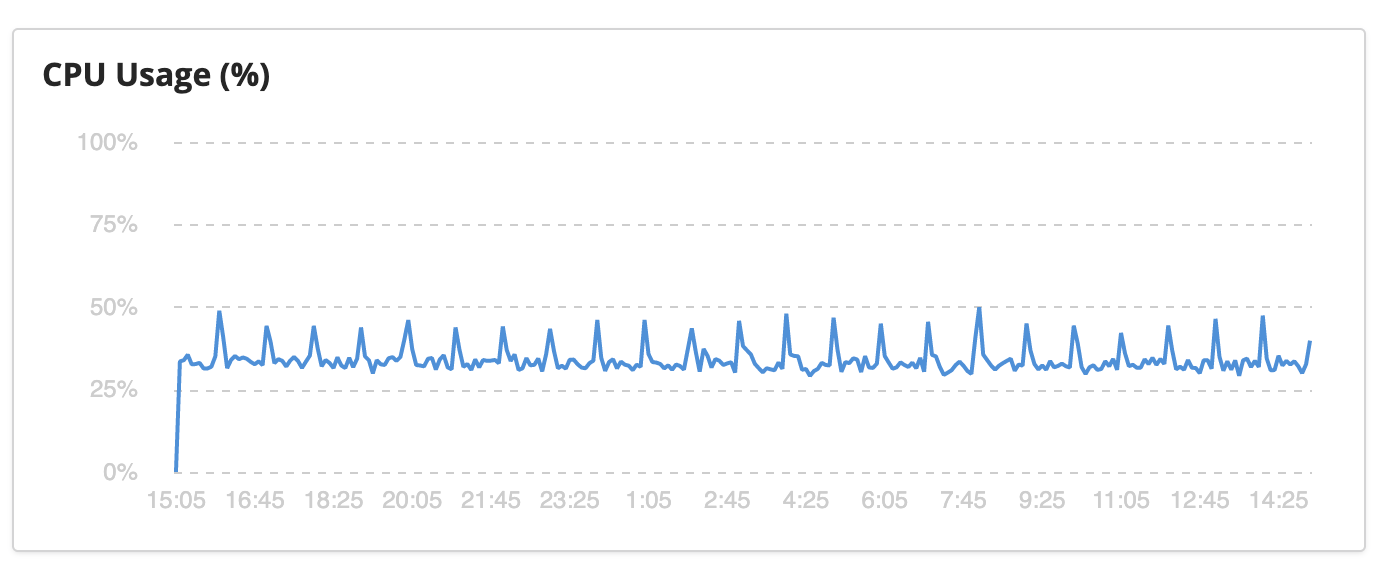
That’s a negative. It’s bouncing between 30% to 50%, the peaks are a scheduled job that imports new data from another system. So that’s not it either. Dejected I went back to the Aura team to get some answers as to why Aura was so unstable compared to other on premise Neo4j clusters I had used in the past. Turns out it’s supposed to be that way.

Neo4j Aura runs special versions of Neo4j that get deployed constantly. Configuration changes at every level happen constantly. Virtual Servers are being moved around to different physical servers constantly. They even have chaos monkeys killing servers and letting them recover automatically. The environment is in a constant state of being on fire by design so when an actual fire happens, it is business as usual.
But… the driver and the application weren’t really expecting so much turbulence. I gave the Aura team a sample database and application that mimicked the customer workload and they came back with two configuration suggestions. First, don’t let any connection linger for more than 8 minutes. There are processes that currently automatically close them at 10 minutes, so there was really no point going longer than that.
.withMaxConnectionLifetime(8, TimeUnit.MINUTES)
So we tried that and the number of errors dropped significantly. However, some error remained, we weren’t quite out of the woods yet. The second suggestion they gave me was to double check any connection that had been idle for more than 2 minutes to make sure it was still alive.
.withConnectionLivenessCheckTimeout(2, TimeUnit.MINUTES)
With these changes the Driver configuration now looks like this.
Driver driver = GraphDatabase.driver(conf.getString("neo4j.uri"),
AuthTokens.basic(conf.getString("neo4j.username"), conf.getString("neo4j.password")),
org.neo4j.driver.Config.builder()
.withMaxConnectionLifetime(8, TimeUnit.MINUTES)
.withConnectionLivenessCheckTimeout(2, TimeUnit.MINUTES)
.withEncryption().build()
…and the results:
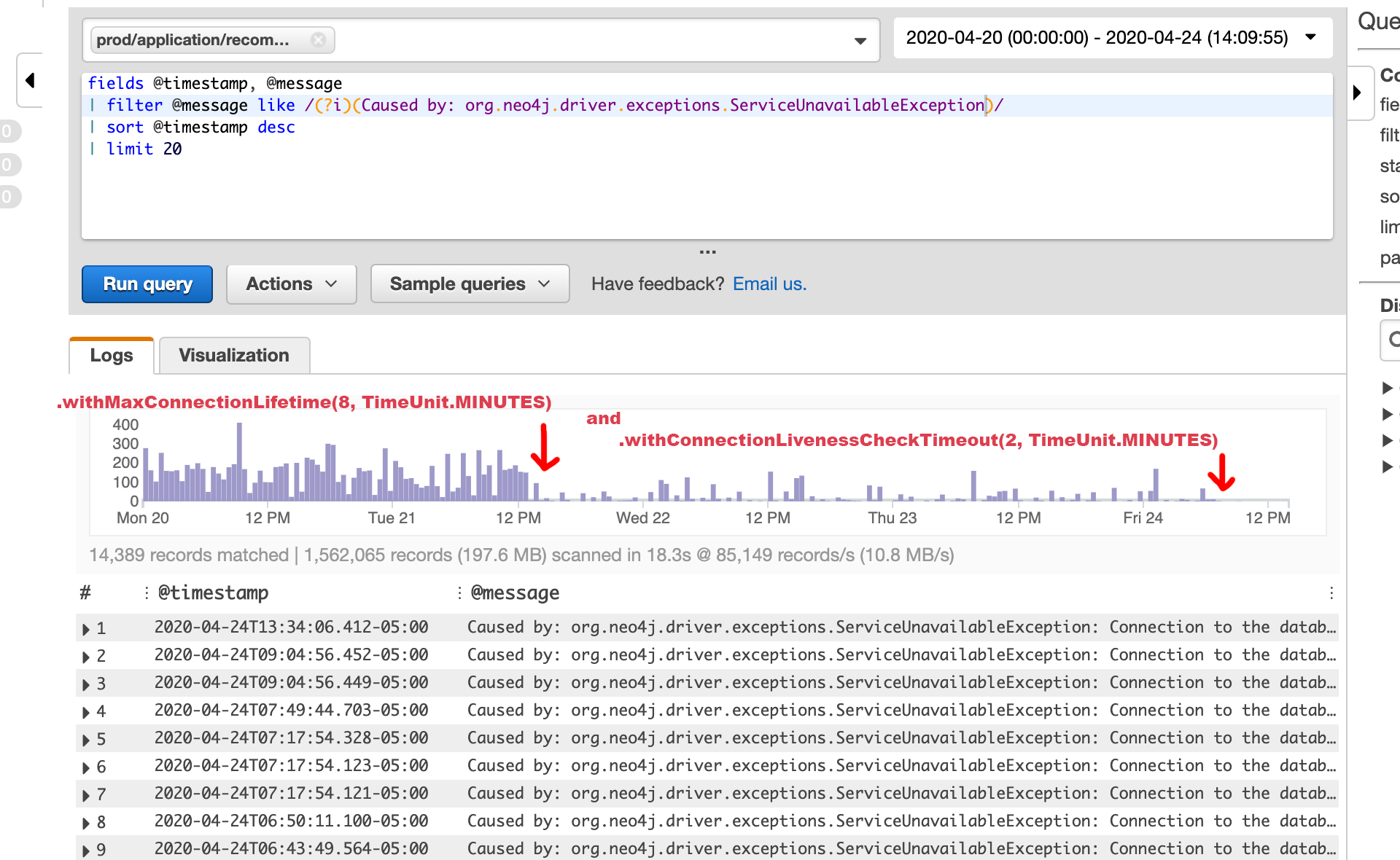 .
.
A dramatic reduction in the number of errors. You can see on the chart where something changed even without the red arrows. So is this what you should be doing when connecting to Aura? Maybe, Maybe not. Take a look at your logs after you’ve upgraded to the latest driver and are using Transaction Functions. If you do see errors then it may be worth a try to add these settings. Try one, check and then try the other. Your workload may be very different that the one this customer had, so as always, test and if you try these things and still have issues… Please reach out to the Aura team or me directly.

What do you think of the latency for a database? Putting a DB far away from your code may dramatically drop performance? What do you think?
Go to your favorite website in Chrome. Right click, then choose “Inspect”.
All the way on the right is the “Audits” tab. Click on that.
Then switch your device to “Desktop” on the right and click “Generate report”.
Losing a few ms to the network latency between the DB and the App is nothing, nothing, compared to the time wasted by css, images, javascript, fonts and whatever else. So I wouldn’t stress over it.
But if you do, you can always host your own Neo4j next to your App. Or even put your app in Neo4j using Unmanaged Extensions.
Quite out of topic question:
I read several posts where you emphasise the power of the (Java) Traversal API in order to build complex and efficient queries. Do you know if the Traversal API is available in AuraDB? I’m trying to find information on how to integrate/use the Java Traversal API in AuraDB, but I didn’t found so much.
The Traversal API has been deprecated. https://neo4j.com/docs/java-reference/current/#tutorial-traversal-java-api