
If you haven’t read part 1 then do that first or this won’t make sense, well nothing makes sense but this specially won’t.
So before going much further I decided to benchmark our new database and found that our addNode speed is phenomenal, but it was taking forever to create relationships. See some JMH benchmarks below:
Benchmark Mode Cnt Score Error Units ChronicleGraphBenchmark.measureCreateEmptyNodes thrpt 10 1548.235 ± 556.615 ops/s ChronicleGraphBenchmark.measureCreateEmptyNodesAndRelationships thrpt 10 0.165 ± 0.007 ops/s
Each time I was creating 1000 users, so this test shows us we can create over a million empty nodes in one second. Yeah ChronicleMap is damn fast. But then when I tried to create 100 relationships for each user (100,000 total) it was taking forever (about 6 seconds). So I opened up YourKit and you won’t believe what I found out next (come on that’s some good clickbait).
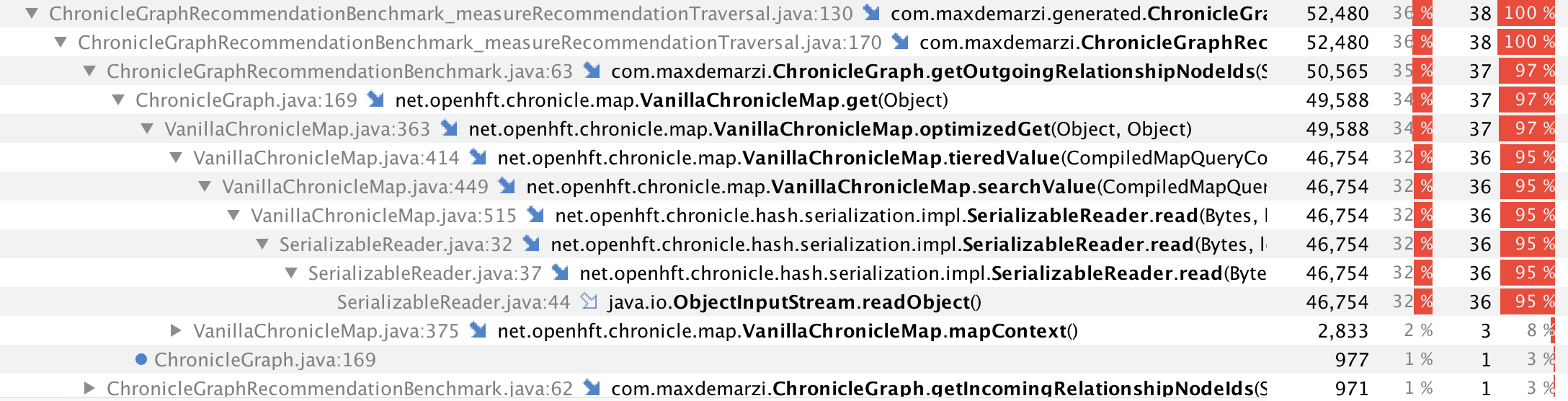
So wait, why is SerializableReader eating up all our time?
The cost of updating any value is the same as deserializating the whole object and reserializing it again. The larger the value the more expensive it is. It sounds like what you really need is a multi-map where you can have multiple values for the same key. — Peter Lawrey
But of course. Every time I added a relationship to the Set value in each ChronicleMap key it has to read it, open it up, change it, and save it back down again, and I was doing this twice one for the outgoing and one for the incoming relationship.
Update: Roman sent us a Pull Request to use a different serializer than the standard one:
SetMarshaller<String> cmValueMashaller = SetMarshaller
.of(new StringBytesReader(), CharSequenceBytesWriter.INSTANCE);
ChronicleMap<String, Set<String>> cmOut = ChronicleMap
.of(String.class, (Class<Set<String>>) (Class) Set.class) .of(String.class, (Class<Set<String>>) (Class) Set.class)
.valueMarshaller(cmValueMashaller)
...
Which improves our Relationship writes by about 3.5x, which is great, but not quite enough:
Benchmark Mode Cnt Score Error Units CGraphBenchmark.measureCreateEmptyNodesAndRelationships.old thrpt 10 0.165 ± 0.007 ops/s CGraphBenchmark.measureCreateEmptyNodesAndRelationships.new thrpt 10 0.573 ± 0.022 ops/s
Ok, so Peter suggests a Multi-Map… but what I really need is a Multi-Map that can be reversed… so as any developer would do I turn to StackOverflow.

Yes, that sounds good and Slavik gives us an implementation that’s almost what I needed. The only thing missing was not just finding a key by value, but storing the reverse of the relationship in a second MultiMap. So I tweaked it to do just that and called it a ReversibleMultiMap.
public class ReversibleMultiMap<K extends String, V extends String> implements Multimap<K, V> {
private Multimap<K, V> key2Value = ArrayListMultimap.create();
private Multimap<V, K> value2key = ArrayListMultimap.create();
So now whenever we add or remove things from this class, it will do it twice. The normal way from key2Value and in reverse from value2key.
@Override
public boolean put(K key, V value) {
value2key.put(value, key);
return key2Value.put(key, value);
}
@Override
public boolean remove(Object key, Object value) {
value2key.remove(value, key);
return key2Value.remove(key, value);
}
Awesome, this will make all our relationship methods much easier to write and reason about.
public boolean addRelationship (String type, String from, String to) {
related.putIfAbsent(type, new ReversibleMultiMap<>());
return related.get(type).put(from, to);
}
I decided I wanted to leave the train wreck of the implementation I wrote yesterday alone and started a new repository. The ArrayListMultimap above comes from the Google Guava Library which you’ve seen me use before on this blog.
So somehow mixing Guava and Chronicle I ended up with GuancicleDB, but Google told me what I really wanted was GuancialeDB which is some kind of cured meat, so that’s our new name.

Look at that amazing logo. You can cut it up in cubes, you can slice it, you can just eat it whole like a lion. It exemplifies the multi-model nature of our database. Ok, listen. All the good names are taken. Just ask the CockRoachDB guys. Besides, we can change the name later, it’s not like we added a stupid “4j” to the thing.
In case you haven’t figured it out yet, the reason for storing the relationships both ways is that I’m kinda trying to replicate what we do at Neo4j. I hope you have seen this internals blog post before, but if you haven’t go ahead and take a look. The important piece is the last image shown below:

Neo4j uses fixed sized records, so we know node 12 is at some offset location plus 12 * NODE_SIZE (which I think is around 16 or 17 bytes) and relationship 99 is at some offset location plus 99 * RELATIONSHIP_SIZE (which I think is around 33 or 34 bytes). This makes it easy to get from one spot to the next in O(1) without an index. We aren’t using an index which is O(log n), we’re using a hash, so it’s somewhere between O(1) and O(log n) in the worst case.
This dual relationship storage costs us in terms of space and complicates methods like removeNode, but this ReversibleMultiMap makes things a bit easier. Compare this method with the previous one:
public boolean removeNode(String id) {
nodes.remove(id);
for (String type : related.keySet()) {
ReverseableMultiMap<String, String> rels = related.get(type);
for (String value : rels.get(id) ) {
relationships.remove(id + "-" + value + type);
}
for (String key : rels.getKeysByValue(id) ){
relationships.remove(key + "-" + id + type);
}
rels.removeAll(id);
}
return true;
}
Here, we first remove the node from our “nodes” ChronicleMap. Then for each relationship type we get its outgoing relationships and grab their target nodes. Now we can delete any relationships that had properties from the “relationships” ChronicleMap and then we do the reverse relationships properties and finally remove the relationships themselves with removeAll. Ok, so what about performance. Well our create node speed is about the same since that part hasn’t changed, but oh my take a look at the relationships.
Benchmark Mode Cnt Score Error Units GuancialeDBBenchmark.measureCreateEmptyNodes thrpt 10 1686.604 ± 274.524 ops/s GuancialeDBBenchmark.measureCreateEmptyNodesAndRelationships thrpt 10 47.859 ± 4.412 ops/s
We are now doing about 48 operations per second where before it took us 6 seconds to do 1 operation (remember we are creating 100k relationships in each operation). That’s like almost 300 times faster write speed. How well does it perform reading? Well how about an actual traversal, a recommendation. We are going to start with the items I like, then find other people who liked those items, and then we’re going to find things those people liked that I haven’t liked yet, count them up and return the top 10.
public List measureRecommendationTraversal() throws IOException {
Set<String> itemsYouLike = db.getOutgoingRelationshipNodeIds("LIKES", "person" + rand.nextInt(personCount));
Map<String, LongAdder> occurrences = new HashMap<>();
for (String item : itemsYouLike) {
for (String person : db.getIncomingRelationshipNodeIds("LIKES", item)) {
Set<String> itemsYouMightLike = db.getOutgoingRelationshipNodeIds("LIKES", person);
itemsYouMightLike.removeAll(itemsYouLike);
for (String unlikeditem : itemsYouMightLike) {
occurrences.computeIfAbsent(unlikeditem, (t) -> new LongAdder()).increment();
}
}
}
List<Map.Entry<String, LongAdder>> itemList = new ArrayList<>(occurrences.entrySet());
Collections.sort(itemList, (a, b) -> ( b.getValue().intValue() - a.getValue().intValue() ));
return itemList.subList(0, Math.min(itemList.size(), 10));
}
We will vary the number of items, the number of likes, and the people doing the liking for our tests. I’ve modified the likesCount column to show likes per person and total likes. Take a look at the results below:
Benchmark (itemCount) (likesCount) (personCount) Score Error Units GDBRB.measureRecommendationTraversal 200 10 - 10k 1000 5743.075 ± 435.999 ops/s GDBRB.measureRecommendationTraversal 200 10 - 100k 10000 471.123 ± 38.216 ops/s GDBRB.measureRecommendationTraversal 200 100 - 100k 1000 13.102 ± 1.287 ops/s GDBRB.measureRecommendationTraversal 200 100 - 1M 10000 1.386 ± 0.082 ops/s GDBRB.measureRecommendationTraversal 2000 10 - 10k 1000 31663.653 ± 2360.847 ops/s GDBRB.measureRecommendationTraversal 2000 10 - 100k 10000 3150.472 ± 431.150 ops/s GDBRB.measureRecommendationTraversal 2000 100 - 100k 1000 56.848 ± 6.973 ops/s GDBRB.measureRecommendationTraversal 2000 100 - 1M 10000 6.008 ± 0.906 ops/s
The sparser our graph is the faster this query returns. You can see this comparing our fastest two results which both have 1000 people, and 10k relationships but vary in 200/2000 items. You can see this again in our worst two results where the 2000 item graph is sparser and faster.
I think this is workable for now. Sorry for the first false start, but I learn more from my screw-ups than when I get it right the first time, and I hope you do too. So stay tuned for next time, when we will put a web server in front of this thing and add an API.
On to Part 3

Using a minimally specialized value marshaller for ChronicleMap<String, Set> versus the default (built-in Java serialization), that is a one-line change (https://github.com/maxdemarzi/ChronicleGraph/pull/1/files#diff-6c2e7f6535b182a70060e8aa46a01026R62), makes the “measureCreateEmptyNodesAndRelationships” benchmarks three times faster: https://github.com/maxdemarzi/ChronicleGraph/pull/1
[…] On to Part 2 […]
[…] you haven’t read part 1 and part 2 then do that first or you’ll have no clue what I’m doing, and I’d like to be the […]
[…] read parts 1, 2 and 3 before continuing or you’ll be […]
[…] in Part 2 we ran some JMH tests to see how many empty nodes we could create. Let’s try that test one […]