
The “footprints in the sand” poem is a story of a person walking on the beach with God and seeing two sets of footprints. The footprints represent the joys and sorrows of this persons life. During the worst of times the trail shows just one set of footprints. Confused as to why they would be abandoned at their time of need, God replies that “when you see only one set of footprints, it was then that I carried you”. It’s a touching poem, but a single set of footprints in the sand isn’t very graphy. Things get interesting when you superimpose the paths one over the other. We can then start to see where many paths converged and diverged, see how deep the footprints got at times, when they split where they went and where did they end up.
We’ve talked about paths here before. You may recall treating sentences like paths and combining them together based on the same words being used to understand what many people are saying in Opiniosis and the follow up. We’ve seen paths of users as they navigate an IVR system or a website. We’ve tracked paths of transaction data to find the source of fraud. We’ve looked at order histories as paths to see what people are likely to purchase next. We’ve seen paths in supply chains modeling Bills of Materials… and a bunch of others I’m forgetting. If paths interest you, there is also a video about Customer Journey Analytics you may want to watch.
Today, I’m going to start off with a very simple top of the sales funnel example using marketing activities and we’ll see where we take it. Let’s say we have an “activities.csv” file with the columns, email, date and activity. This file has the list of what activities a user performed and when. We’ll represent the user with an email address and their activities are things like registered for a webinar, signed up for a newsletter, attended a live event, downloaded the software, etc. With the goal of ultimately creating opportunities from our users.
email,date,activity drezet2@icloud.com,2019-01-12,book reziac5@yahoo.ca,2019-09-29,book esbeck2@sbcglobal.net,2019-01-31,opportunity juerd8@gmail.com,2019-06-08,webinar
We want to create 3 types of nodes. One for the emails, one for the type of activity, and another for the activity itself. The first two have natural “primary keys” so lets go ahead and create constraints for them so we don’t make more than one of each and we back our unique properties with an index so they are easy to find during imports and queries. We’ll also add an index on the type property of the Activity node so we can get these quickly later on:
CREATE CONSTRAINT ON (e:Email) assert e.address IS UNIQUE; CREATE CONSTRAINT ON (a:ActivityType) assert a.name IS UNIQUE; CREATE INDEX ON :Activity(type);
You’ll want to copy the activities.csv file included in this repository to your Neo4j “import” directory. Then follow along with me as we first create the Email nodes:
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM 'file:///activities.csv' AS row
MERGE (e:Email {address:row.email});
Next, we’ll create the ActivityType nodes:
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM 'file:///activities.csv' AS row
MERGE (at:ActivityType {name:row.activity});
…and finally we’ll create the Activity nodes.
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM 'file:///activities.csv' AS row
MATCH (e:Email {address:row.email})
CREATE (a:Activity {date: date(row.date), type:row.activity})
CREATE (e)-[:PERFORMED]->(a);
You may be thinking, wait a minute, why did we create ActivityType nodes if we aren’t going to relate them to anything? We’ll get to that part later, just keep it in mind. After we run this last LOAD CSV command, we are able to see what activities were performed with these kind of queries:
MATCH p=(e:Email {address:"drezet2@icloud.com"})-[:PERFORMED]->()
RETURN p
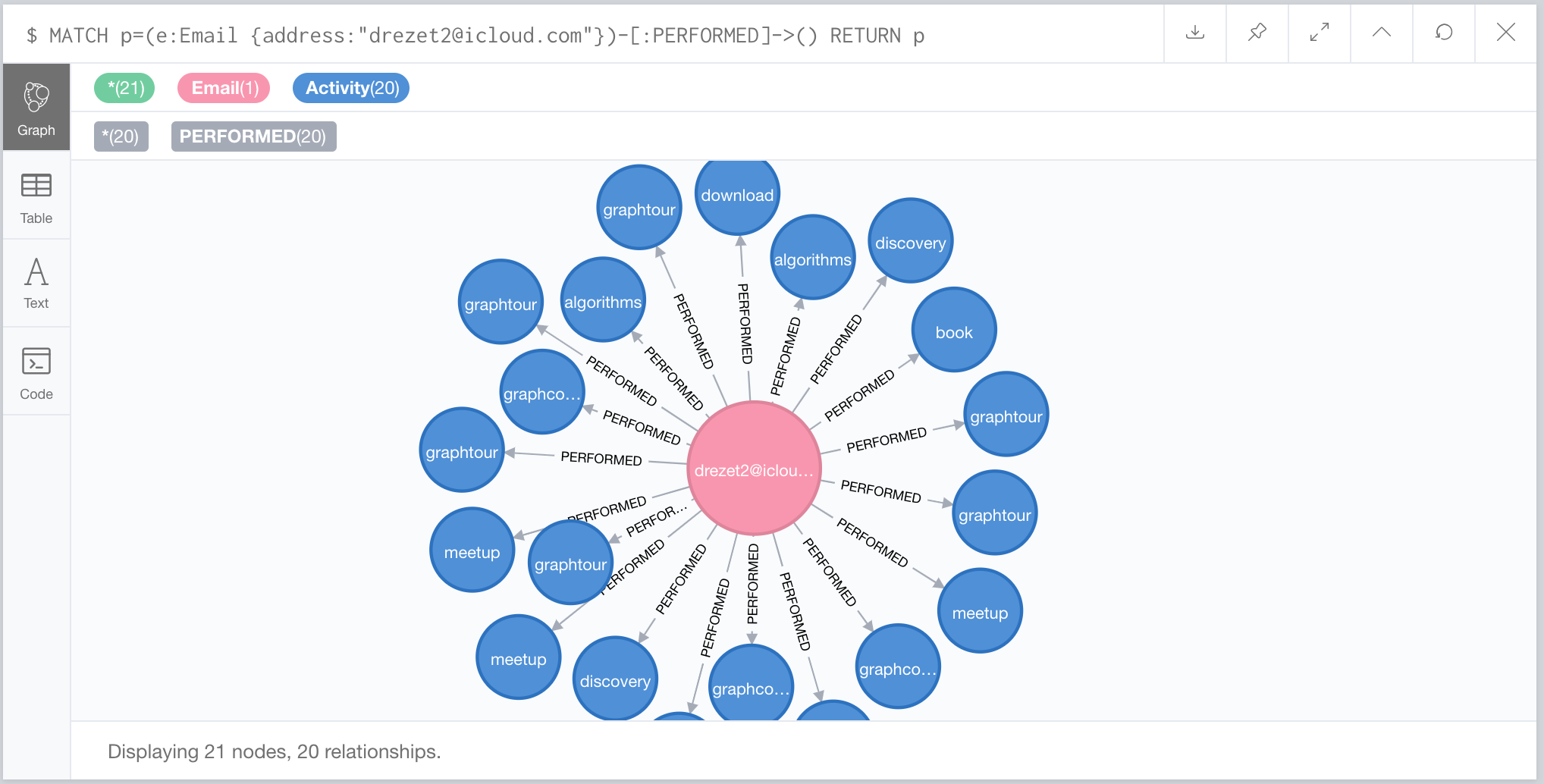
That’s great and all, but we want to ask questions about the sequence of events in our users activities, so let’s convert these activities in a linked list. We can do this by starting from each Email, traversing the PERFORMED relationship, and collecting them ordered by date. Then we’ll create a NEXT relationship from the Email to the first activity they performed and create a NEXT relationship for each one of the activities:
MATCH (e:Email)-[r:PERFORMED]->(a) WITH e, a ORDER BY a.date ASC WITH e, COLLECT(a) AS activities, HEAD(COLLECT(a)) AS first CREATE (e)-[:NEXT]->(first) FOREACH (n IN RANGE(0, SIZE(activities)-2) | FOREACH (prev IN [activities[n]] | FOREACH (next IN [activities[n+1]] | CREATE (prev)-[:NEXT]->(next) )));
If you have a large dataset, it may be better to link the activities in batches. You can run this query until no more relationships are created. The query looks for Emails that do not have any NEXT relationships but have PERFORMED relationships, and in chunks of 1000 at a time, creates the linked lists for each.
MATCH (e:Email) WHERE SIZE((e)-[:NEXT]->()) = 0 AND SIZE((e)-[:PERFORMED]->()) > 0 WITH e LIMIT 1000 MATCH (e)-[r:PERFORMED]->(a) WITH e, a ORDER BY a.date ASC WITH e, COLLECT(a) AS activities, HEAD(COLLECT(a)) AS first CREATE (e)-[:NEXT]->(first) FOREACH (n IN RANGE(0, SIZE(activities)-2) | FOREACH (prev IN [activities[n]] | FOREACH (next IN [activities[n+1]] | CREATE (prev)-[:NEXT]->(next) )));
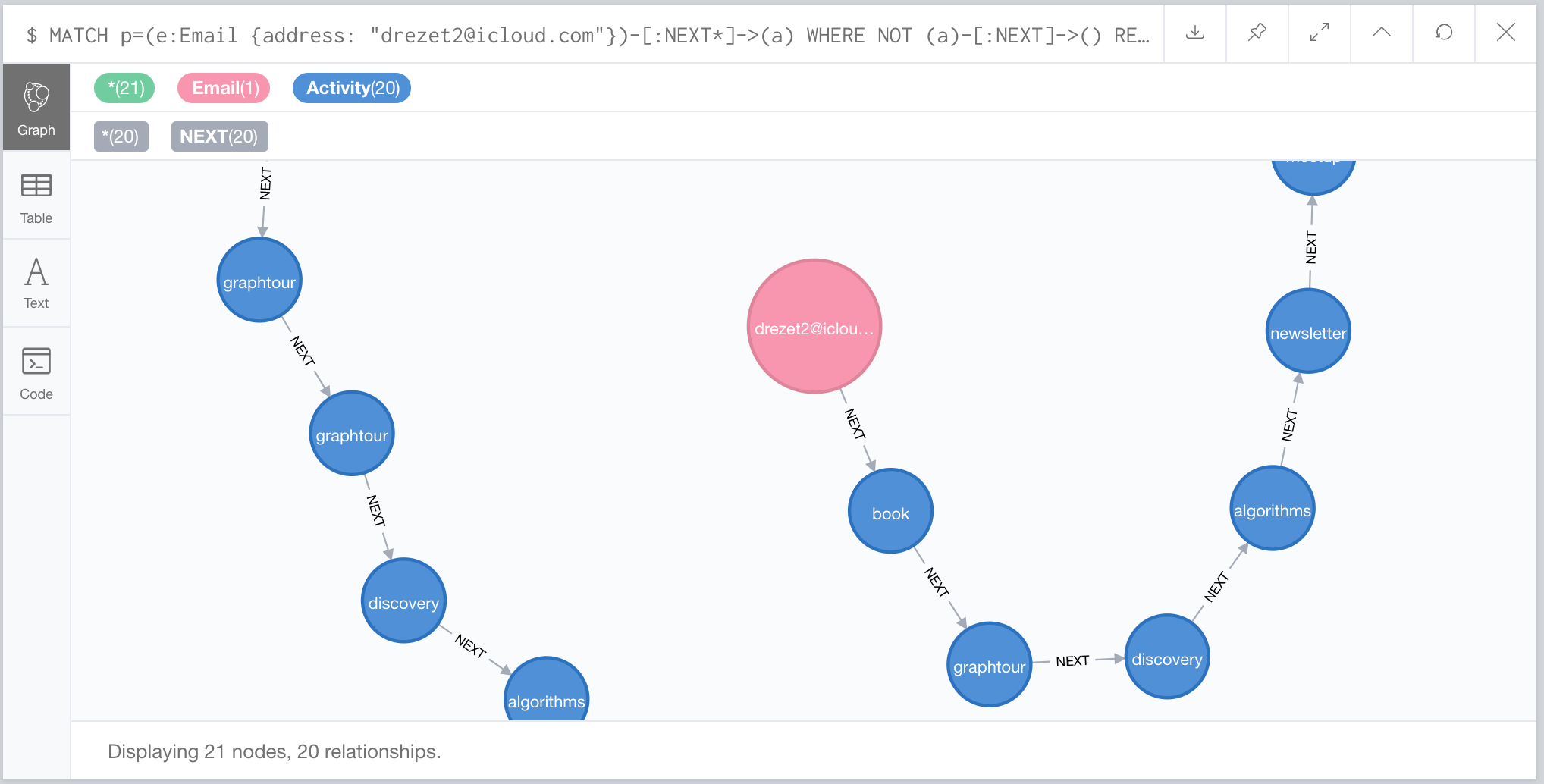
Let’s see the full list of activities for one email address. We’ll traverse using NEXT*. The * (star) in Cypher means “keep going”, so it will continue traversing NEXT relationships until there are no more. The WHERE part of this query is asking Cypher to return the longest path, where the last activity it finds does not have a NEXT relationship:
MATCH p=(e:Email {address: "drezet2@icloud.com"})-[:NEXT*]->(a)
WHERE NOT (a)-[:NEXT]->()
RETURN p
That’s a lot of activities, how about if we get the distinct activity types for this one email address:
MATCH p=(e:Email {address: "drezet2@icloud.com"})-[:NEXT*]->(a)
RETURN COLLECT(DISTINCT a.type)

The data was made up randomly, but we can tell a story about user. They downloaded the neo4j graph databases book, went to a graph tour, had a discovery call with a sales development rep, downloaded the algorithms book, signed up to our newsletter, went to a meetup, went to our big graph connect conference and lastly downloaded Neo4j. That’s a lot of activities for this user, but not the one we want. We want all our users to eventually have the “opportunity” to use Neo4j in their work. Let’s see the kind of activities that get us there. How about staring with the count of activity types one to three steps from an opportunity:
MATCH p=(a1:Activity)-[:NEXT*1..3]->(a2:Activity) WHERE a2.type = "opportunity" RETURN [x IN NODES(p) | x.type], COUNT(p) ORDER BY count(p) DESC
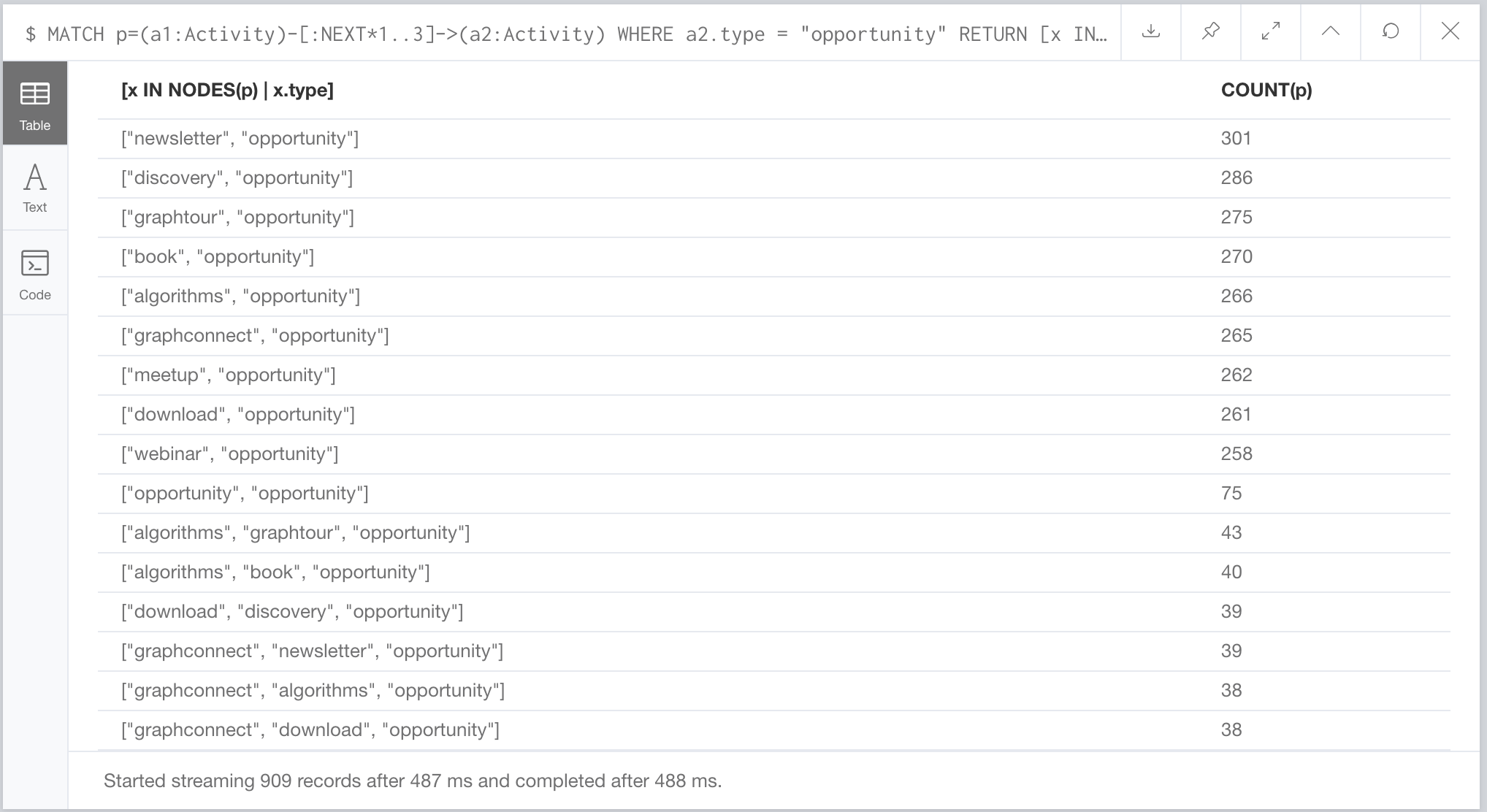
Remember the data is made up so don’t read too much into this, but according to our query after signing up for our newsletter, the most seen next activity is an opportunity. Don’t we all wish it was that easy. Second on our list is a discovery call leading to an opportunity, third is coming to one of our graph tour events, and so on…
Let’s compare the activities of two email addresses. We’ll traverse the NEXT relationships for each one and collect the distinct type of their activity. From there we can split them into those that are unique to the first email, unique to the second email and types they both have in common:
MATCH p=(e:Email {address: "drezet2@icloud.com"})-[:NEXT*]->(a),
p2=(e2:Email {address: "ghost5@msn.com"})-[:NEXT*]->(a2)
WITH COLLECT(DISTINCT a.type) AS e_activities,
COLLECT(DISTINCT a2.type) AS e2_activities
RETURN [x IN e_activities WHERE NOT(x IN e2_activities)] AS unique_e,
[x IN e2_activities WHERE NOT(x IN e_activities)] AS unique_e2,
[x IN e_activities WHERE (x IN e2_activities)] AS common

It looks like “drezet2@icloud.com” came to a graph tour event, and signed up to our newsletter while “ghost5@msn.com” watched one of our webinars, while they both performed various activities in common. If you are a long time reader you may recognize this query to being a very similar one we ran on the Bill of Materials blog post to find unique parts. These are completely different use cases and sets of data, but they share the same structure so the questions we ask are similar.
What I really want to know, is what sequence of activities tend to lead to an opportunity. Let’s find this out. First let’s count the number of activities that followed each other by type:
MATCH (a1:Activity)-[:NEXT]->(a2:Activity)
WITH a1.type AS a1type, a2.type AS a2type, count(*) AS count
MATCH (at1:ActivityType {name: a1type}), (at2:ActivityType {name: a2type})
MERGE (at1)-[r:NEXT]->(at2)
SET r.count = count
Now we’ve linked the Activity Type nodes to something! Each other. With the strength of their relationship being the count of the number of times they followed each other. Let’s see the top 3 5-hop paths users took:
MATCH path = (at:ActivityType)-[:NEXT*..5]->() WHERE ALL (r IN relationships(path) WHERE r.count > 1) RETURN [at IN nodes(path)| at.name] AS actions, reduce(sum=0, r IN relationships(path) | sum + r.count) AS score ORDER BY score DESC LIMIT 3

Maybe in ancient times, “all roads lead to Rome”, but in today’s day and age, it looks like all roads lead to coming to our Graph Connect conference. The next one is on April 20-22 in New York City, so how about you come check it out. Talking about the current and past centers of the known world reminds me of Centrality algorithms. Using the Neo4j Graph Algorithms library we can run Weighted PageRank on our Activity Type nodes to see which ones are the most important. At least in terms of being the next activity performed:
CALL algo.pageRank.stream('ActivityType', 'NEXT', {iterations:20, dampingFactor:0.85, weightProperty: "count"})
YIELD nodeId, score
RETURN algo.asNode(nodeId).name AS page,score
ORDER BY score
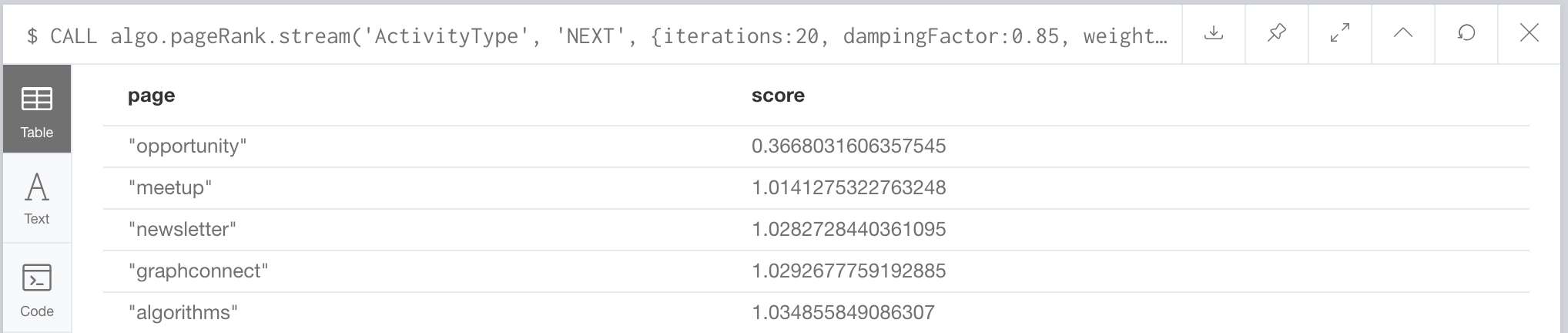
Ok, so opportunity has the lowest score, which makes sense because it means they are going to be busy implementing a Neo4j project and don’t have time to do anything else (I’m just kidding, data was randomly created but I made less opportunities than the rest). The other activities all have about the same score… that’s what you get when you have random data, but if you had real data you would hopefully see something more interesting like dead-end activities and activities that generate more engagement.
What else can we learn. How about what is the most likely next activity for a user to take based on their last 3 activities? How do we go about doing that? Well, we start off by getting the longest path of the users activities, we then grab the last 3 activities. Then we find paths of activities amongst all users that follow the same sequence of types, and go out one more NEXT relationship to see what they ended up doing. The query looks like this:
MATCH path=(e:Email {address: "drezet2@icloud.com"})-[:NEXT*]->(a)
WHERE SIZE((a)-[:NEXT]->()) = 0
WITH [at IN nodes(path)| at.type][-3..] AS last
MATCH (a1:Activity)-[:NEXT]->(a2)-[:NEXT]->(a3)-[:NEXT]->(a4)
WHERE a1.type = last[0] AND a2.type = last[1] AND a3.type = last[2]
RETURN a4.type, COUNT(*) AS count
ORDER BY count DESC
LIMIT 5

Coming to a graph tour or having a discovery call seem the most likely candidates. But I have to tell you this query worries me a bit performance wise. I try to avoid checking property values during a traversal, and here we are doing a ton of that. This query ends up with around 45k db hits. Let’s see if we can bring that down.
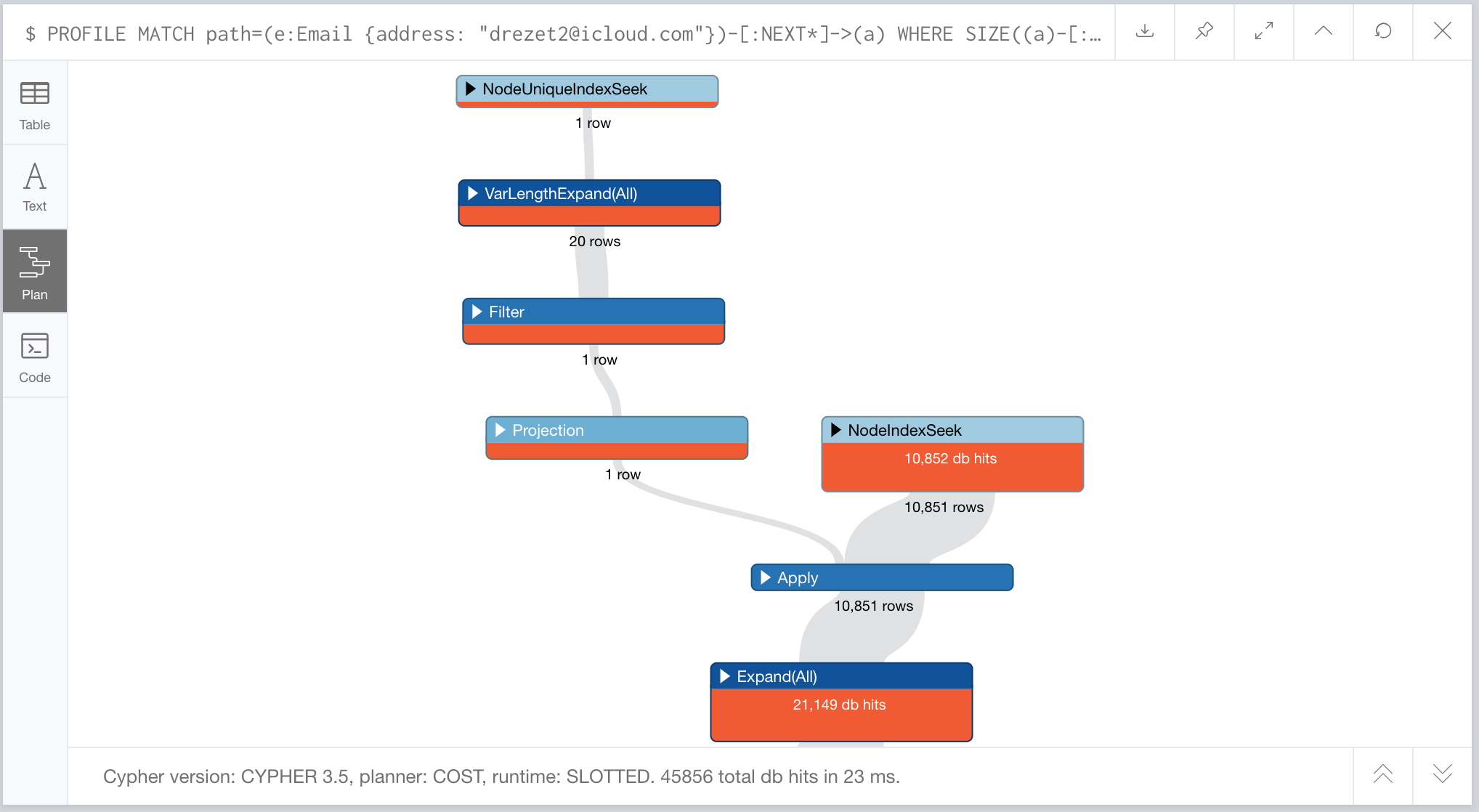
What could we do? Long time readers may be thinking, I know. He is going to promote the activity type of the next activity into the NEXT relationship so we end up with NEXT_WEBINAR, NEXT_MEETUP, NEXT_GRAPH_CONNECT, etc relationship types. We can create custom relationship types for the next action using APOC:
MATCH (a1:Activity)-[:NEXT]->(a2:Activity)
CALL apoc.create.relationship(a1, "NEXT_" + toUpper(a2.type), {}, a2) YIELD rel
RETURN COUNT(rel)
If we run that query, we end up with this kind of model:
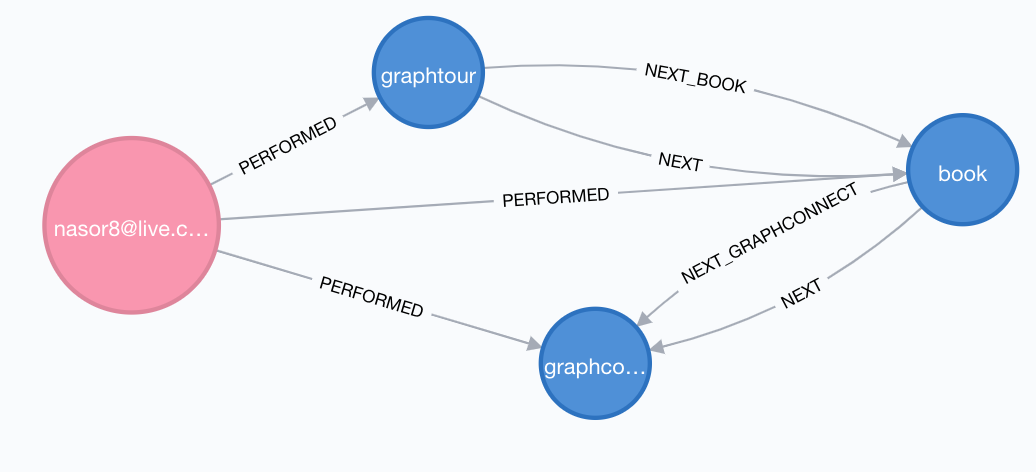
We can rewrite the query to check the relationship types as it traverses by using the TYPE function and adding “NEXT_” to the uppercase types we want. Not the prettiest query but not too bad:
MATCH path=(e:Email {address: "drezet2@icloud.com"})-[:NEXT*]->(a)
WHERE SIZE((a)-[:NEXT]->()) = 0
WITH [at IN nodes(path)| at.type][-3..] AS last
MATCH (a1:Activity)-[r1]->(a2)-[r2]->(a3)-[:NEXT]->(a4)
WHERE a1.type = last[0]
AND TYPE(r1) = "NEXT_" + toUpper(last[1])
AND TYPE(r2) = "NEXT_" + toUpper(last[2])
RETURN a4.type, COUNT(*) AS count
ORDER BY count DESC
But what happens when we profile this query?
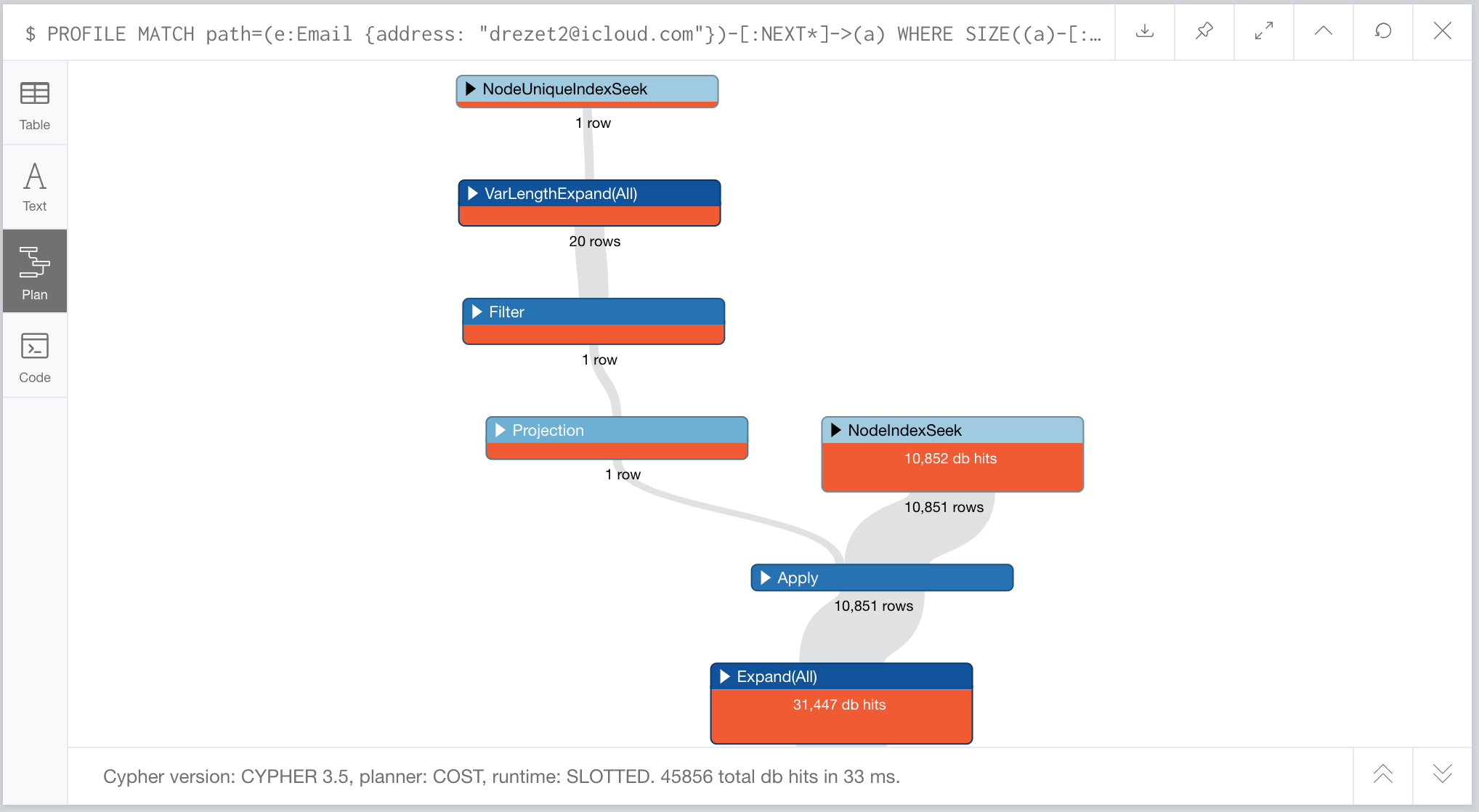
It’s the same number of hits, but instead of checking the node property we are checking the relationship type. How can we tell it to just traverse the relationship types we want instead of traversing them all and then checking? Well, we can use APOC to make that happen, take a look at this query:
MATCH path=(e:Email {address: "drezet2@icloud.com"})-[:NEXT*]->(a)
WHERE SIZE((a)-[:NEXT]->()) = 0
WITH [at IN nodes(path)| at.type][-3..] AS last
CALL apoc.cypher.run("MATCH (a1:Activity)-[:NEXT_" + toUpper(last[1]) +
"]->(a2)-[:NEXT_" + toUpper(last[2]) +
"]->(a3)-[:NEXT]->(a4) WHERE a1.type ='" + last[0] +
"' RETURN a4.type AS type, COUNT(*) AS count", null)
YIELD value
RETURN value.type, value.count
ORDER BY value.count DESC
It looks pretty ugly, but it gives us the performance we want right?

Only 105 db hits? But it took 15ms? That doesn’t seem right… and it isn’t. Whenever we use APOC in a query, we can pretty much throw out the number of db hits returned since the profiler doesn’t understand what APOC (or any stored procedure) is doing.
But that doesn’t really help us much. Ok, sure we cut the time in half, but can we do better? In Neo4j the relationships of each node are partitioned off, and then partitioned again by type and direction. But an Activity node will have a PERFORMS relationship back to the Email, and potentially two NEXT relationships, so splitting it by type so we don’t have to check the next node type property doesn’t buy us much. We need a new approach. Let’s delete all those relationships.
What if instead, we created a sort of “static path” index of what the next actions where for this action?
We can traverse the NEXT relationships from an email, get all the paths of size 3 or more, take the end of the paths, and then go back to the third node counting backward and set the “next_activities” property with a concatenation of it’s type plus the types of the next two activities:
MATCH path=(e:Email {address: "drezet2@icloud.com"})-[:NEXT*3..]->(a)
WITH nodes(path)[-3] AS activity,
REDUCE(types = nodes(path)[-3].type,
n IN nodes(path)[-2..]| types + "-" + n.type) AS key
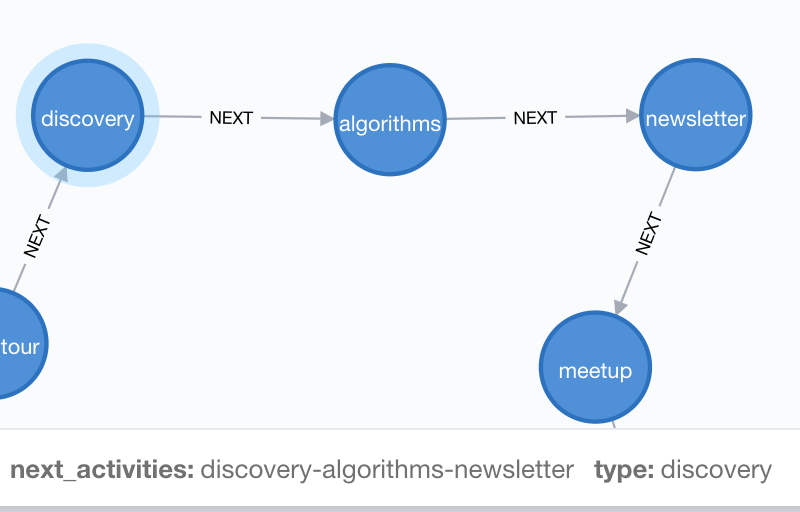
SET activity.next_activities = key
Now when I put my mouse over an Activity and take a peek at the “next_activities” property we can see “discovery-algorithms-newsletter”, which happen to be the types of it and the next two activities.
Let’s do it for all the email addresses, and all the actions. We need emails have have performed more than 2 actions, and their first activity doesn’t have the “next_activities” property set. We will run this query until we no longer update any properties, 1000 emails at a time, so in our case we run it 5 times:
MATCH (e:Email)
WHERE SIZE((e)-[:PERFORMED]->()) > 2
WITH e
MATCH (e)-[:NEXT]->(a)
WHERE NOT EXISTS(a.next_activities)
WITH e
LIMIT 1000
MATCH path=(e)-[:NEXT*3..]->(a)
WITH nodes(path)[-3] AS activity,
REDUCE(types = nodes(path)[-3].type,
n IN nodes(path)[-2..]| types + "-" + n.type) AS key
SET activity.next_activities = key
Before we can really take advantage of this “static path” index, we need to create a new index on this property:
CREATE INDEX ON :Activity(next_activities);
With that in place, we can rewrite our query to find the next_activities property based on a key made up of the previous 3 activity types in a path:
MATCH path=(e:Email {address: "drezet2@icloud.com"})-[:NEXT*]->(a)
WHERE SIZE((a)-[:NEXT]->()) = 0
WITH REDUCE(types = nodes(path)[-3].type,
n IN nodes(path)[-2..]| types + "-" + n.type) AS key
MATCH (a1:Activity)-[:NEXT]->(a2)-[:NEXT]->(a3)-[:NEXT]->(a4)
WHERE a1.next_activities = key
RETURN a4.type, COUNT(*) AS count
ORDER BY count DESC
How fast is this query?

About 1000 db hits in 2ms. That’s more like it.
But hold on a second. This query just tells us what they are likely to do next. We don’t necessarily want that. We want to guide them into performing an action that will lead them to an opportunity quickly. We can get that by making sure the following action after the one we “recommend” is an opportunity:
MATCH path=(e:Email {address: "drezet2@icloud.com"})-[:NEXT*]->(a)
WHERE SIZE((a)-[:NEXT]->()) = 0
WITH REDUCE(types = nodes(path)[-3].type,
n IN nodes(path)[-2..]| types + "-" + n.type) AS key
MATCH path1=(a1:Activity)-[:NEXT]->(a2)-[:NEXT]->(a3)-[:NEXT]->(a4)-[:NEXT]->(a5)
WHERE a1.next_activities = key
AND a4.type <> "opportunity"
AND a5.type = "opportunity"
RETURN a4.type, COUNT(DISTINCT path1) AS count
ORDER BY count DESC

That doesn’t give us a lot of choices, what if we want to recommend activity types that eventually lead to an opportunity? We can see if any activities after (a4) are opportunities:
MATCH path=(e:Email {address: "drezet2@icloud.com"})-[:NEXT*]->(a)
WHERE SIZE((a)-[:NEXT]->()) = 0
WITH REDUCE(types = nodes(path)[-3].type,
n IN nodes(path)[-2..]| types + "-" + n.type) AS key
MATCH path1=(a1:Activity)-[:NEXT]->(a2)-[:NEXT]->(a3)-[:NEXT]->(a4), path2=(a4)-[:NEXT*]->(a5)
WHERE a1.next_activities = key
AND a4.type <> "opportunity"
AND ANY (x IN nodes(path2) WHERE x.type = "opportunity")
RETURN a4.type, COUNT(DISTINCT path1) AS count
ORDER BY count DESC
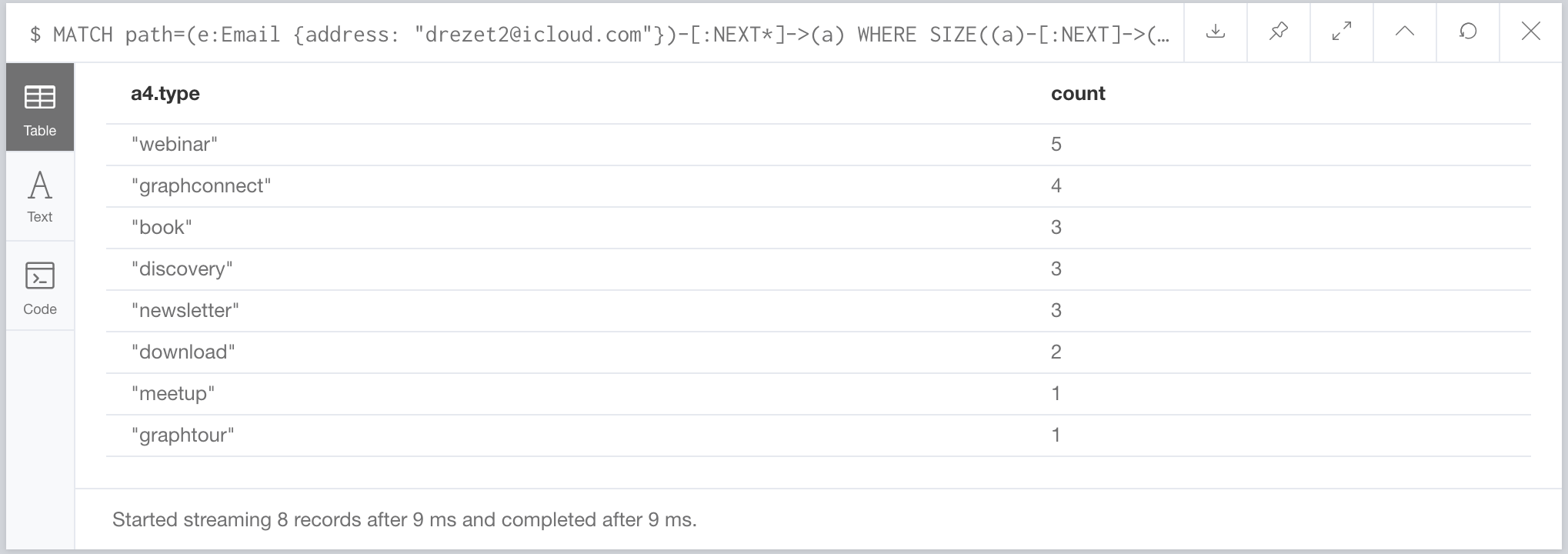
Nice. Now the next_activities property is a long String, in a production system we may want to shorten that up a bit. We can do that by just taking the first few characters of the activity type and using that as our key:
"next_activities": "meetup-download-discovery" "next_activities": "me-do-di"
If we wanted to predict the next activity of a user with just their last two activities, we could use STARTS WITH against the next_activities property:
MATCH path=(e:Email {address: "drezet2@icloud.com"})-[:NEXT*]->(a)
WHERE SIZE((a)-[:NEXT]->()) = 0
WITH nodes(path)[-2].type + "-" + nodes(path)[-1].type AS key
MATCH path1=(a1:Activity)-[:NEXT]->(a2)-[:NEXT]->(a3), path2=(a3)-[:NEXT*]->(a4)
WHERE a1.next_activities STARTS WITH key
AND a3.type <> "opportunity"
AND ANY (x IN nodes(path2) WHERE x.type = "opportunity")
RETURN a3.type, COUNT(DISTINCT path1) AS count
ORDER BY count DESC
Having to do that second path traversal using NEXT* is slowing us down a bit. What if we could “know” the activity path a user is on is a good one, if it leads to an opportunity right away? Well, we can create a new property “next_winning_activities” using the same trick.
MATCH (e:Email) WHERE SIZE((e)-[:PERFORMED]->()) > 2 WITH e MATCH (e)-[:NEXT]->(a) WHERE NOT EXISTS(a.next_winning_activities) WITH e MATCH (e)-[:PERFORMED]->(a) WHERE a.type = "opportunity" WITH DISTINCT e LIMIT 1000 MATCH path=(e)-[:NEXT*3..]->(a), path2=(a)-[:NEXT*]->() WHERE ANY (x IN tail(nodes(path2)) WHERE x.type = "opportunity") WITH nodes(path)[-3] AS activity, REDUCE(types = nodes(path)[-3].type, n IN nodes(path)[-2..]| types + "-" + n.type) AS key SET activity.next_winning_activities = key
…and add an index to it:
CREATE INDEX ON :Activity(next_winning_activities);
Then our queries become a little simpler:
MATCH path=(e:Email {address: "drezet2@icloud.com"})-[:NEXT*]->(a)
WHERE SIZE((a)-[:NEXT]->()) = 0
WITH REDUCE(types = nodes(path)[-3].type, n IN nodes(path)[-2..]| types + "-" + n.type) AS key
MATCH path1=(a1:Activity)-[:NEXT]->(a2)-[:NEXT]->(a3)-[:NEXT]->(a4)
WHERE a1.next_winning_activities = key
RETURN a4.type, COUNT(DISTINCT path1) AS count
ORDER BY count DESC
…and super fast!
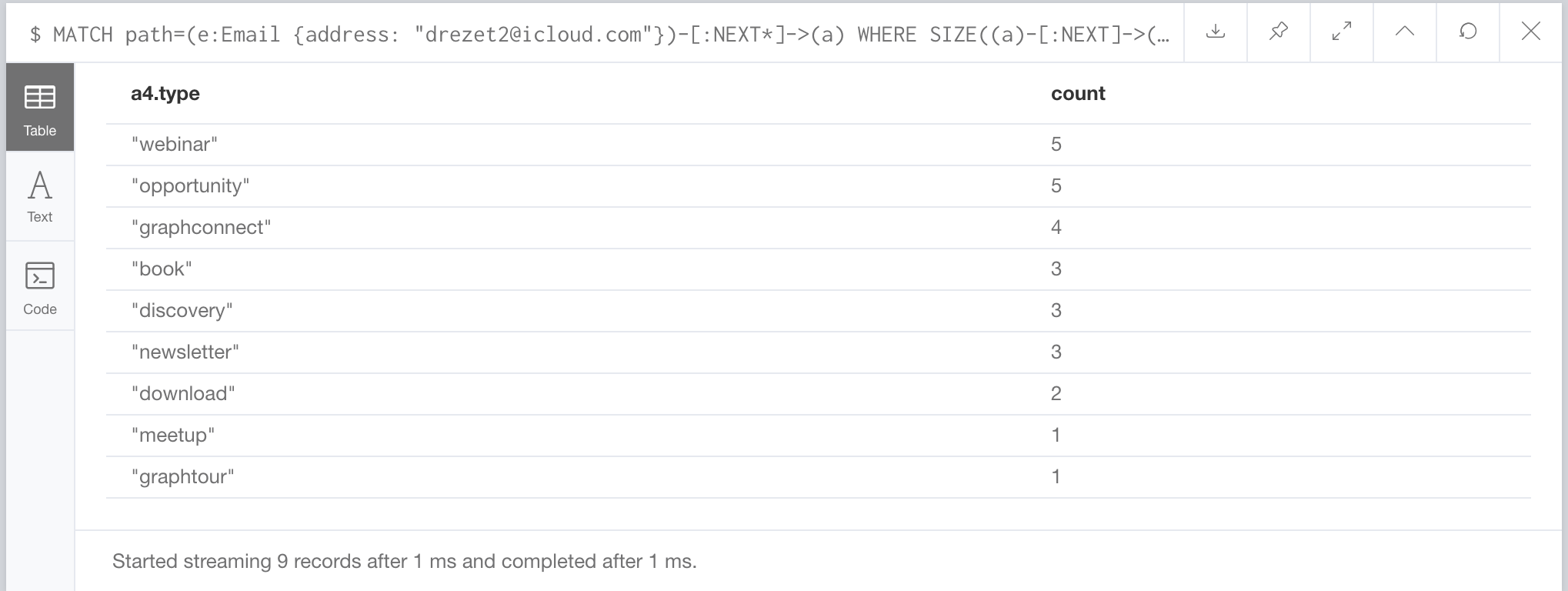
Well, I hope you liked exploring marketing activities in Neo4j. There is plenty more exploring to do, but I think we’ve gone on long enough. You can of course use the same ideas in many different uses cases where events and their sequences matter. Code as always is on github. Do you like this static path index trick? What kind of queries can you think of? Leave your answers in the comments below.
Update:
I don’t know why I didn’t think of this earlier, but we could put the next_activities and next_winning_activities on the last node instead of the first node in the pattern and avoid the first two NEXT hops for even more speed.
