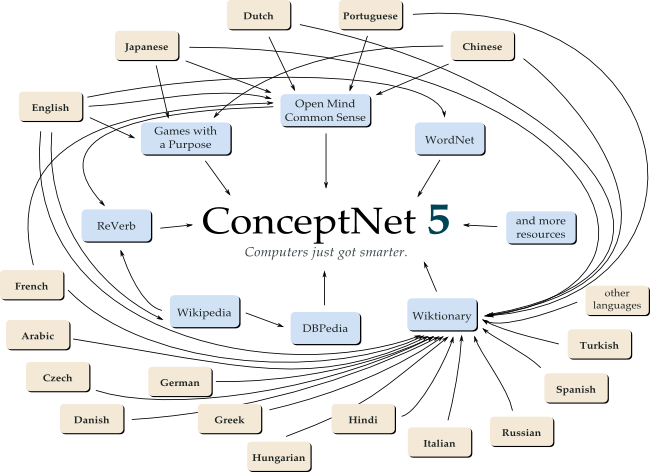
From the second we are born we are collecting a wealth of knowledge about the world. This knowledge is accumulated and interrelated inside our brains and it represents what we know. If we could export this knowledge and give it to a computer, it would look like ConceptNet. ConceptNet is a semantic network that…
…is built from nodes representing concepts, in the form of words or short phrases of natural language, and labeled relationships between them. These are the kinds of things computers need to know to search for information better, answer questions, and understand people’s goals.









