
People produce a lot of content. Messages, text files, spreadsheets, presentations, reports, financials, etc, the list goes on. Usually organizations want to have a repository of all this content centralized somewhere (just in case a laptop breaks, gets lost or stolen for example). This leads to some kind of grouping and permission structure. You don’t want employees seeing each other’s HR records, unless they work for HR, same for Payroll, or unreleased quarterly numbers, etc. As this data grows it no longer becomes easy to simply navigate and a search engine is required to make sense of it all.
But what if your search engine returns 1000 results for a query and the user doing the search is supposed to only have access to see 4 things? How do you handle this? Check the user permissions on each file realtime? Slow. Pre-calculate all document permissions for a user on login? Slow and what if new documents are created or permissions change between logins? Does the system scale at 1M documents, 10M documents, 100M documents?
In the Neo4j data modeling examples there is a solution using a graph.
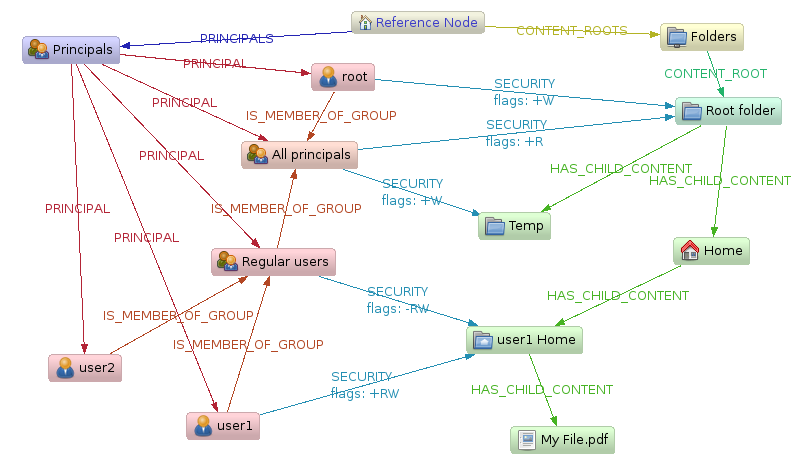
Users have direct permissions to documents (or folders), or via groups. Folders can have many child documents, which can have many child documents and “turtles all the way down”.
Having them in a graph makes it easy to:
- Find all files in the directory structure
- What files are owned by whom?
- Who has access to a File?
- … and so on
So back to our question. What if the search engine returned 1000 records and we needed to see which of these the user has access to. How can we do this in the graph?
Not by starting from the User and traversing to all the possible documents the user has access to (since this could take a very long time in a 100M document graph). Instead we will start with the documents and see if they have a direct permission relationship to the user or the groups the user belongs to. We do this for all the documents, and for those which we don’t have a direct relationship, we move up to the parent folder and try it again. We’ll be smart and merge any documents who share the same parent to reduce the number of checks. Doing it this way, we will traverse thousands of relationships (instead of millions) depending on how deep the document structure goes.
I’m going to walk-through the code using the Neo4j Core API inside an unmanaged extension so it can be accessed via REST and I’ll show you how I wrote a couple of performance tests (one random and one static) as well as how I generated our test data. This project is open source and available on github.
Let’s dig in. We need to create a test for our unmanaged extension, but we can’t test without some sample data, so let’s start by creating an ImpermanentGraphDatabase in MyServiceTest.java:
private ImpermanentGraphDatabase db;
private MyService service;
private ObjectMapper objectMapper = new ObjectMapper();
private static final RelationshipType KNOWS = DynamicRelationshipType.withName("KNOWS");
private static final RelationshipType SECURITY = DynamicRelationshipType.withName("SECURITY");
private static final RelationshipType IS_MEMBER_OF = DynamicRelationshipType.withName("IS_MEMBER_OF");
private static final RelationshipType HAS_CHILD_CONTENT = DynamicRelationshipType.withName("HAS_CHILD_CONTENT");
Before our tests are run, we want to populate our graph, and then tear it down:
@Before
public void setUp() {
db = new ImpermanentGraphDatabase();
populateDb(db);
service = new MyService();
}
@After
public void tearDown() throws Exception {
db.shutdown();
}
We’ll create a few users, groups, documents, and then link them to each other:
private void populateDb(GraphDatabaseService db) {
Transaction tx = db.beginTx();
try
{
Node personA = createPerson(db, "A");
Node personB = createPerson(db, "B");
Node personC = createPerson(db, "C");
Node personD = createPerson(db, "D");
Node doc1 = createDocument(db, "DOC1");
Node doc2 = createDocument(db, "DOC2");
Node doc3 = createDocument(db, "DOC3");
Node doc4 = createDocument(db, "DOC4");
Node doc5 = createDocument(db, "DOC5");
Node doc6 = createDocument(db, "DOC6");
Node doc7 = createDocument(db, "DOC7");
Node g1 = createGroup(db, "G1");
Node g2 = createGroup(db, "G2");
personA.createRelationshipTo(personB, KNOWS);
personB.createRelationshipTo(personC, KNOWS);
personC.createRelationshipTo(personD, KNOWS);
personA.createRelationshipTo(g1, IS_MEMBER_OF);
personB.createRelationshipTo(g2, IS_MEMBER_OF);
doc1.createRelationshipTo(doc4, HAS_CHILD_CONTENT);
doc2.createRelationshipTo(doc5, HAS_CHILD_CONTENT);
doc5.createRelationshipTo(doc7, HAS_CHILD_CONTENT);
Relationship secA1 = createPermission(personA, doc1, "R");
Relationship secA3 = createPermission(personA, doc3, "RW");
Relationship secB4 = createPermission(personB, doc4, "R");
Relationship secG2 = createPermission(g1, doc2, "R");
Relationship secG6 = createPermission(g2, doc6, "R");
tx.success();
}
finally
{
tx.finish();
}
}
The CreatePerson, CreateDocument and CreateGroup methods look like:
private Node createPerson(GraphDatabaseService db, String uid) {
Index<Node> people = db.index().forNodes("Users");
Node node = db.createNode();
node.setProperty("unique_id", uid);
people.add(node, "unique_id", uid);
return node;
}
The CreatePermission method is a little bit different since we’re creating a relationship.
private Relationship createPermission(Node person, Node doc, String permission) {
Relationship sec = person.createRelationshipTo(doc, SECURITY);
sec.setProperty("flags", permission);
return sec;
}
Finally we’ll write a couple of tests that once we have a “permissions” method should pass:
@Test
public void shouldRespondToPermissions() throws BadInputException, IOException {
String ids = "A,DOC1 DOC2 DOC3 DOC4 DOC5 DOC6 DOC7";
Response response = service.permissions(ids, db);
List list = objectMapper.readValue((String) response.getEntity(), List.class);
assertEquals(new HashSet<String>(Arrays.asList("DOC1", "DOC2", "DOC3", "DOC4", "DOC5", "DOC7")), new HashSet<String>(list));
}
@Test
public void shouldRespondToPermissions2() throws BadInputException, IOException {
String ids = "B,DOC1 DOC2 DOC3 DOC4 DOC5 DOC6 DOC7";
Response response = service.permissions(ids, db);
List list = objectMapper.readValue((String) response.getEntity(), List.class);
assertEquals(new HashSet<String>(Arrays.asList("DOC4", "DOC6")), new HashSet<String>(list));
}
From here we move on to the actual graph algorithm in MyService.java:
First we define our Relationship Types:
private ObjectMapper objectMapper = new ObjectMapper();
private static enum RelTypes implements RelationshipType
{
IS_MEMBER_OF,
SECURITY,
HAS_CHILD_CONTENT
}
Our permissions method takes a string parameter that contains a user id a comma, and a space separated list of document ids. We take the input and initialize some variables that will hold our data as we traverse the graph.
@POST
@Path("/permissions")
public Response permissions(String body, @Context GraphDatabaseService db) throws IOException {
String[] splits = body.split(",");
PermissionRequest ids = new PermissionRequest(splits[0], splits[1]);
Set<String> documents = new HashSet<String>();
Set<Node> documentNodes = new HashSet<Node>();
List<Node> groupNodes = new ArrayList<Node>();
Set<Node> parentNodes = new HashSet<Node>();
HashMap<Node, ArrayList<Node>> foldersAndDocuments = new HashMap<Node, ArrayList<Node>>();
We need to find the user, and all the documents passed in as search hits from our search engine:
IndexHits<Node> uid = db.index().forNodes("Users").get("unique_id", ids.userAccountUid);
IndexHits<Node> docids = db.index().forNodes("Documents").query("unique_id:(" + ids.documentUids + ")");
try
{
for ( Node node : docids )
{
documentNodes.add(node);
}
}
finally
{
docids.close();
}
We will also need all the groups the user belongs:
Node user = uid.getSingle();
if ( user != null && documentNodes.size() > 0)
{
for ( Relationship relationship : user.getRelationships(
RelTypes.IS_MEMBER_OF, Direction.OUTGOING ) )
{
groupNodes.add(relationship.getEndNode());
}
We are going to iterate through these document nodes. In the loop, we check to see if the user node has a direct relationship to the document and if so add it (and any possible children documents to a “document” list which we will return at the end.
Iterator listIterator ;
do {
listIterator = documentNodes.iterator();
Node document = (Node) listIterator.next();
listIterator.remove();
//Check against user
Node found = getAllowed(document, user);
if (found != null) {
if (foldersAndDocuments.get(found) != null) {
for(Node docs : foldersAndDocuments.get(found)) {
documents.add(docs.getProperty("unique_id").toString());
}
} else {
documents.add(found.getProperty("unique_id").toString());
}
}
If the user doesn’t have a direct connection to the document, maybe one of the groups they belong to does:
//Check against user Groups
for (Node group : groupNodes){
found = getAllowed(document, group);
if (found != null) {
if (foldersAndDocuments.get(found) != null) {
for(Node docs : foldersAndDocuments.get(found)) {
documents.add(docs.getProperty("unique_id").toString());
}
} else {
documents.add(found.getProperty("unique_id").toString());
}
}
}
If we had no luck setup to try the parent node of this document:
// Did not find a security relationship, go up the folder chain
Relationship parentRelationship = document.getSingleRelationship(RelTypes.HAS_CHILD_CONTENT,Direction.INCOMING);
if (parentRelationship != null){
Node parent = parentRelationship.getStartNode();
ArrayList<Node> myDocs = foldersAndDocuments.get(document);
if(myDocs == null) myDocs = new ArrayList<Node>();
ArrayList<Node> existingDocs = foldersAndDocuments.get(parent);
if(existingDocs == null) existingDocs = new ArrayList<Node>();
for (Node myDoc:myDocs) {
existingDocs.add(myDoc);
}
if (myDocs.isEmpty()) existingDocs.add(document);
foldersAndDocuments.put(parent, existingDocs);
parentNodes.add(parent);
}
If we get to the end of our documents, we switch to the parents of our documents and iterate through those until there are no more parents (reached the root folder of our document tree).
if(listIterator.hasNext() == false){
documentNodes.clear();
for( Node parentNode : parentNodes){
documentNodes.add(parentNode);
}
parentNodes.clear();
listIterator = documentNodes.iterator();
}
} while (listIterator.hasNext());
Unless we ran into an error, we return the document list:
} else {documents.add("Error: User or Documents not found");}
uid.close();
return Response.ok().entity(objectMapper.writeValueAsString(documents)).build();
}
The getAllowed method just checks to see if a security relationship with the property flag containing “R” is found:
private Node getAllowed(Node from, Node to){
ConnectedResult connectedResult = isConnected(from, to, Direction.INCOMING, RelTypes.SECURITY);
if (connectedResult.isConnected){
if (connectedResult.connectedRelationship.getProperty("flags").toString().contains("R")) {
return connectedResult.connectedRelationship.getEndNode();
}
}
return null;
}
The isConnected method lets us know if two nodes are related to each other by some directed relationship:
private ConnectedResult isConnected(Node from, Node to, Direction dir, RelationshipType type) {
for (Relationship r : from.getRelationships(dir, type)) {
if (r.getOtherNode(from).equals(to)) return new ConnectedResult(true, r);
}
return new ConnectedResult(false, null);
}
Now when we run our tests:
But how fast is it… and does it scale? To find out we’ll need to create a larger graph and a set of performance tests.
Stay tuned for part two.

Great write up. I was just wondering if we can go ahead and use a similar approach for data in relational databases. I can try to implement something, but just wanted an opinion if it makes sense or not
You could…. but as the # of your documents increases and the depth of your file tree increases, your performance is going to get destroyed.
Stay away from Monster Joins.
While I am a fan of graph databases, I have to jump in here to say that you could easily model this the same way with relational. User_id/doc_id table joined to the search results. This table could actually be an indexed view, meaning it is persisted data so the joins will not have a cost during the query.
Alternatively, you could also segment users into permission groups (ie, HR) and do the same for documents. Then on user login, you know the user permission group(s), which is easy and fast. On the search, you append to the “where” clause: “and doctype in (‘HR’)” for example. This way you do not need another join; it is just another search predicate. If a doc can have multiple types, then you need 1 other table to store those (again, indexed views can be your friend here if you’re worried about the joins).
[…] Permission Resolution With Neo4j – Part 1 by Max De Marzi. […]
[…] try tackling something a little bigger. In Part 1 we created a small graph to test our permission resolution graph algorithm and it worked like a […]
[…] We’ll do something similar for documents, but instead of grabbing a random one, we’ll grab up to 1000 of them and join them together in to a string separated by a space (since this is what our permissions REST API endpoint expects for input as shown in part 1.) […]
Hi
Good description. I have a few questions regarding this model since I am considering using a similar model for my current work, some of the features related to the below queries will help me in formulating my security setup:
1. How do you compare this to RBAC, where you have the roles, objects hierarchy?
2. How do you model negative permissions and check for the conflicts.
3. What happens if a user “x” has permissions for all the documents in a folder but 1 document y.
4. You are assuming that every link between the users is a subsumption link. How would you extend this to more customized relationships with different levels of subsumption? For example if the user nodes formed a lattice, how can we check for the permission resolution.
Thanks for your time and sorry if it is lot of questions to ask.
-AJ
You can find a simple gist on RBAC in Neo4j at https://gist.github.com/mikesname/6008933
You can always make your model more complex, for example add an “X” for excludes in the “flags” property of the security relationship and check for that.
You can have these exclude flagged relationships to any document or folder.
The users in this case were connected to groups in a tree hierarchy, not sure a lattice would make much difference.