
Let’s add a couple of performance tests to the mix. We learned about Gatling in a previous blog post, we’re going to use it here again. The first test will randomly choose users and documents (from the graph we created in part 2) and write the results to a file, the second test will re-use the results of the first one and run consistently so we can change hardware, change Neo4j parameters, tune the JVM, etc. and see how they affect our performance.
The full code for the Random Permissions test is here, I’ll just highlight the main parts:
We’ll create a text file where our tests and results will go:
val writer = {
val fos = new java.io.FileOutputStream("src/test/resources/data/test-data.txt")
new java.io.PrintWriter(fos,true)
}
Our test data file will need a header, so we can write a simple scenario that just writes it:
val createFile = scenario("Prepare test-data.txt file").
exec((s: Session) => {
writer.println("results,userid,documentids")
s
})
To complete the rest of this file, we need to get some data. We know the range of nodes our users and documents will be, so we’ll randomly grab some and fill two lists:
val rnd = new scala.util.Random val usersRange = 1 to 3000 val documentRange = 3101 to 1003100 var usersForSimulation = List.fill(200)(usersRange(rnd.nextInt(usersRange.length))) var documentsForSimulation = List.fill(1000)(documentRange(rnd.nextInt(documentRange.length)))
We’ll write a little Cypher to collect the unique_ids of the users we created earlier:
val fetchSomeUserIds = """START user=node({ids}) RETURN collect(user.unique_id) as uids"""
val userPostBody = """{"query": "%s", "params": {"ids": %s}}""".format(fetchSomeUserIds, JSONArray.apply(usersForSimulation).toString())
Next, we’ll execute the query via the REST API and parse the JSON response into a map from which we’ll get the ids and save those as “users”:
val userFetcher = exec(
http("Get some random people")
.post("/db/data/cypher")
.header("X-Stream", "true")
.body(userPostBody)
.asJSON
.check(status.is(200))
.check(bodyString.transform(mybody => {
val map:Map[String,_] = JSON.parseFull(mybody) match {
case Some(map:Map[String,_]) => map
case _ => Map()
}
val listone:List[List[List[String]]] = map.get("data") match {
case Some(results:List[List[List[String]]]) => results
case _ => List()
}
listone.head.head
}).saveAs("users")))
We’ll do this again with very similar code (not shown) but for documents as well. Now we’ll write a method to grab one the users:
val chooseRandomPerson = exec((session) => {
val users:List[String] = session.getTypedAttribute("users")
val user: String = users(rnd.nextInt(users length))
session.setAttribute("user_id", user)
})
We’ll do something similar for documents, but instead of grabbing a random one, we’ll grab up to 1000 of them and join them together in to a string separated by a space (since this is what our permissions REST API endpoint expects for input as shown in part 1.)
val chooseRandomDocuments = exec((session) => {
val documents:List[String] = session.getTypedAttribute("documents")
session.setAttribute("doc_ids", documents.take(1000).mkString(" "))
})
Now that we can choose a random person, and a set of documents we can write the rest of the test. Here we combine the user_id and doc_ids from the sessions into the body of the post method, check that we receive some document ids back, count the number of document ids returned, and save these into “count”. Finally we write the count, user_id and doc_ids to the file we created earlier, so we can re-use it later.
val checkPermissions = during(10) {
exec(chooseRandomPerson, chooseRandomDocuments)
.exec(
http("Post Permissions Request")
.post("/example/service/permissions")
.body("${user_id},${doc_ids}")
.header("Content-Type", "application/text")
.check(status.is(200))
.check(regex("[\"][a-f0-9-]*[\"]")
.exists)
.check(regex("[\"][a-f0-9-]*[\"]").count.saveAs("count"))
)
.exec((s: Session) => {
writer.println(s.getAttribute("count") + "," + s.getAttribute("user_id") + "," + s.getAttribute("doc_ids"))
s
})
.pause(0 milliseconds, 5 milliseconds)
}
We’ll write out a second scenario that will grab the users, grab the documents and perform the permissions check:
val scn = scenario("Permissions via Unmanaged Extension")
.exec(userFetcher, documentFetcher, checkPermissions)
Finally in our test setup, we have one user create the test-data.txt file, and we’ll have 10 users each fetch and execute the permissions test.
setUp(
createFile.users(1),
scn.users(10).ramp(10).protocolConfig(httpConf)
)
Now we can run our simulation:
Choose a simulation number:
[0] simulations.RandomPermissions
[1] simulations.TestPermissions
0
================================================================================
2013-03-24 13:36:23 20s elapsed
---- Prepare test-data.txt file ------------------------------------------------
Users : [#################################################################]100%
waiting:0 / running:0 / done:1
---- Permissions via Unmanaged Extension ---------------------------------------
Users : [#################################################################]100%
waiting:0 / running:0 / done:10
---- Requests ------------------------------------------------------------------
> Get some random people OK=10 KO=0
> Get some random documents OK=10 KO=0
> Post Permissions Request OK=897 KO=0
================================================================================
When we check our test-data.txt file we can now see our header line, and 897 very long lines consisting of the results, the user_id and the document_ids of our test:
results,userid,documentids 38,9a9a0c20-71cc-0130-92a0-20c9d042eca9,a2dffb30-71cc-0130-92a0-20c9d042eca9 9dd3bbb0-71cc-0130-92a0-20c9d042eca9 ...
Now we are ready to write our second test. Here will reference the test-data.txt file we created with the first test, and parse it into a “circular” array. If we ever run out of lines in this test, the test will go back to the beginning of the file and continue.
val testfile = csv("test-data.txt").map {
_.map {
case (key, value) => key match {
case "results" => (key, value.toInt)
case _ => (key, value)
}
}
}.toArray.circular
Our actual POST looks very similar to the first test, except in this case we are checking the results we get against the expected count of results:
val scn = scenario("Permissions via Unmanaged Extension")
.feed(testfile)
.during(30) {
exec(
http("Post Permissions Request")
.post("/example/service/permissions")
.body("${userid},${documentids}")
.header("Content-Type", "application/text")
.check(status.is(200))
.check(regex("[\"][a-f0-9-]*[\"]")
.count.is(session => session.getTypedAttribute[Int]("results"))
))
.pause(0 milliseconds, 5 milliseconds)
}
For this test, we’ll run with 20 concurrent users, ramping up over 10 seconds, for the 30 second duration of our test:
setUp(
scn.users(20).ramp(10).protocolConfig(httpConf)
)
================================================================================
2013-03-24 14:49:06 40s elapsed
---- Permissions via Unmanaged Extension ---------------------------------------
Users : [#################################################################]100%
waiting:0 / running:0 / done:20
---- Requests ------------------------------------------------------------------
> Post Permissions Request OK=2836 KO=0
================================================================================
Simulation finished.
Simulation successful.
Generating reports...
Reports generated in 0s.
Please open the following file : /Users/maxdemarzi/Projects/neo_permissions/performance/target/results/testpermissions-20130324144824/index.html
Let’s take a look at the performance:
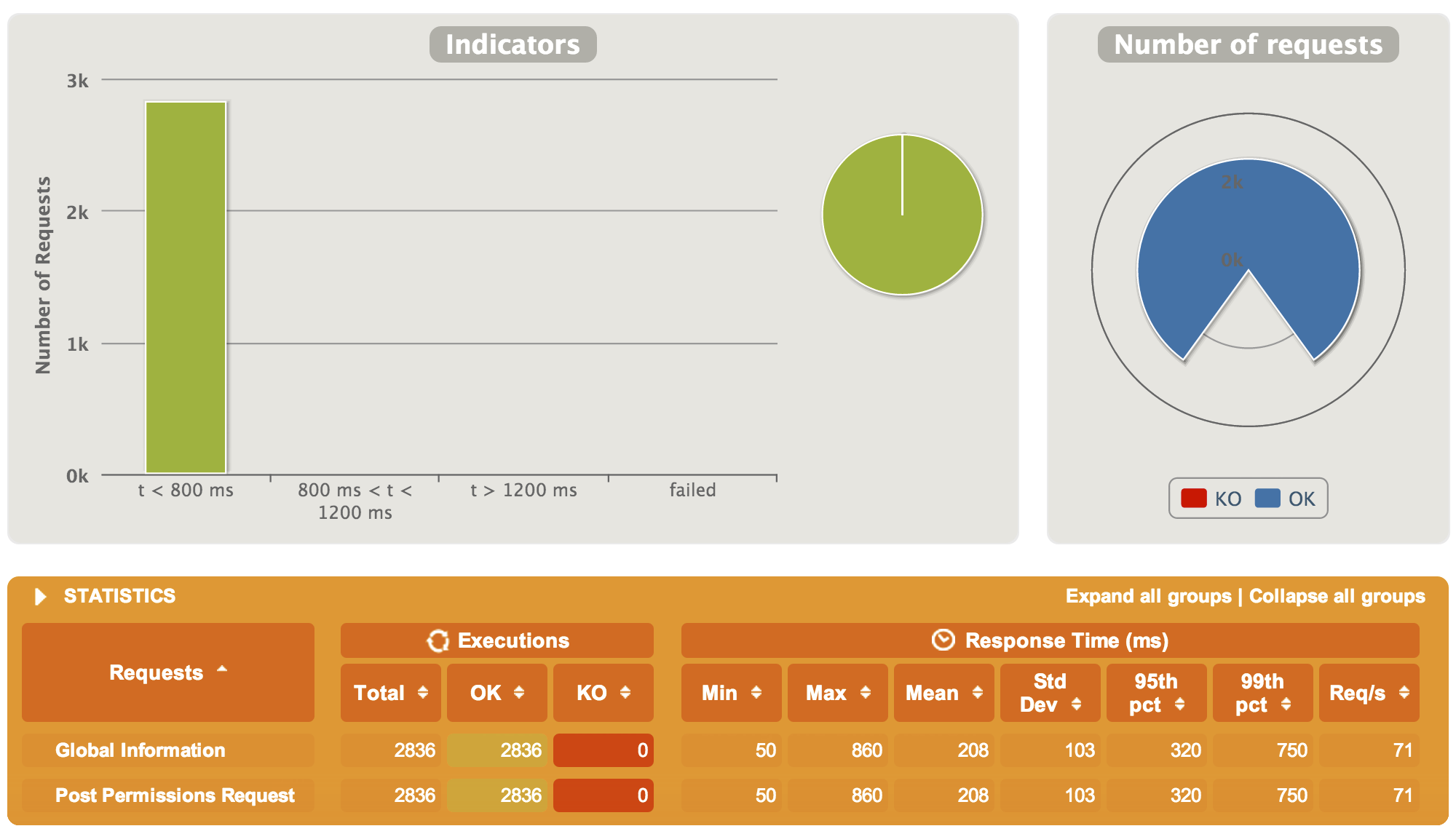
With up to 20 concurrent users, we got 71 requests per second with a mean latency of 208 ms. Not bad at all considering it’s just running on my laptop along with a hundred other things including the test suite (don’t do that in real world tests).
What about the bigger 10M document graph:
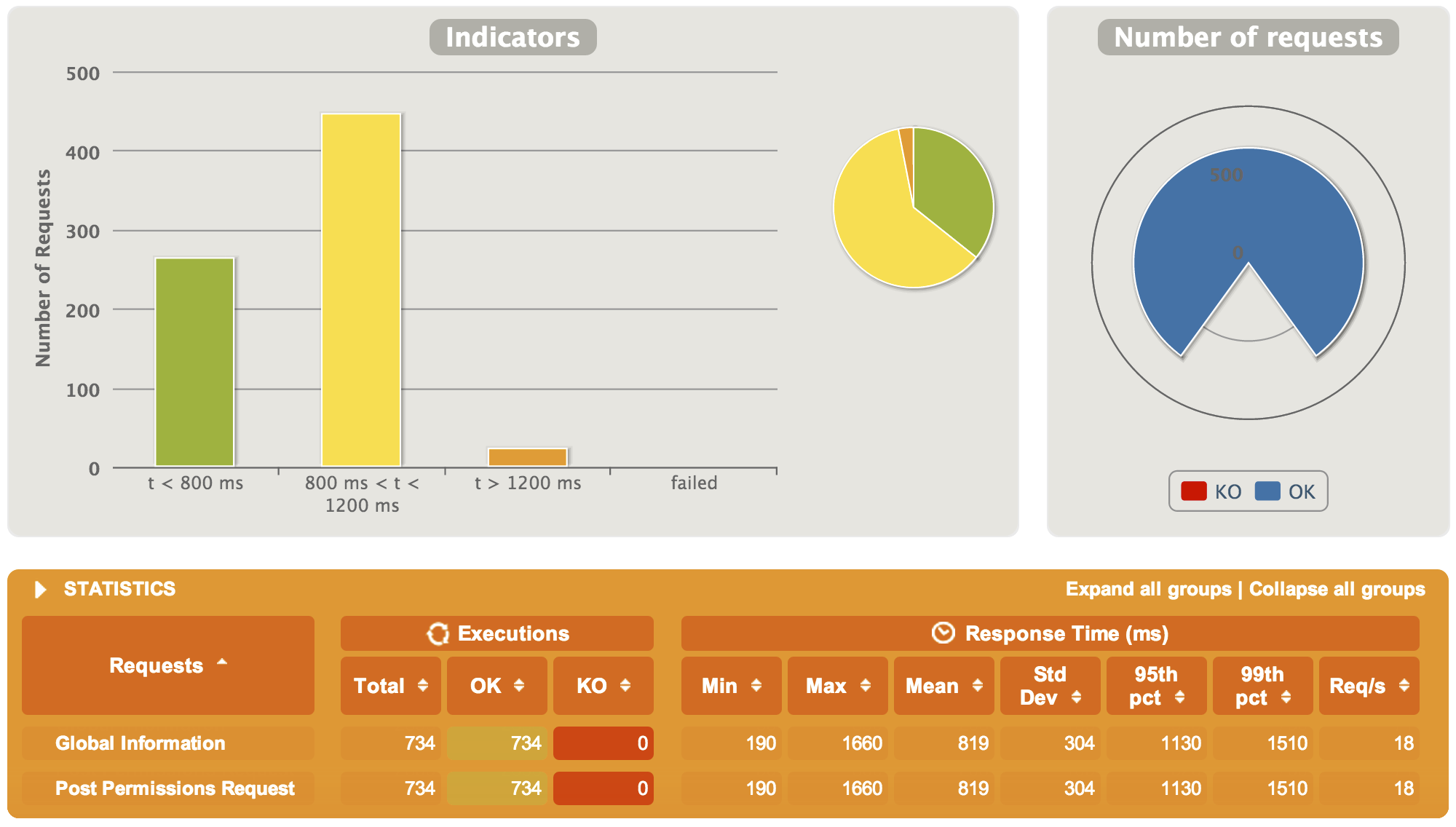
We grew our documents by 10x, and our performance dropped to 1/4x. Taking a look at the chart below, we can see a ton of dips in the very wobbly requests line indicating heavy Java Garbage Collection going on. We can try to tune this a bit, but realistically these numbers are telling us we should be looking at heavier duty hardware (than a laptop) to run this algorithm in the larger graph.
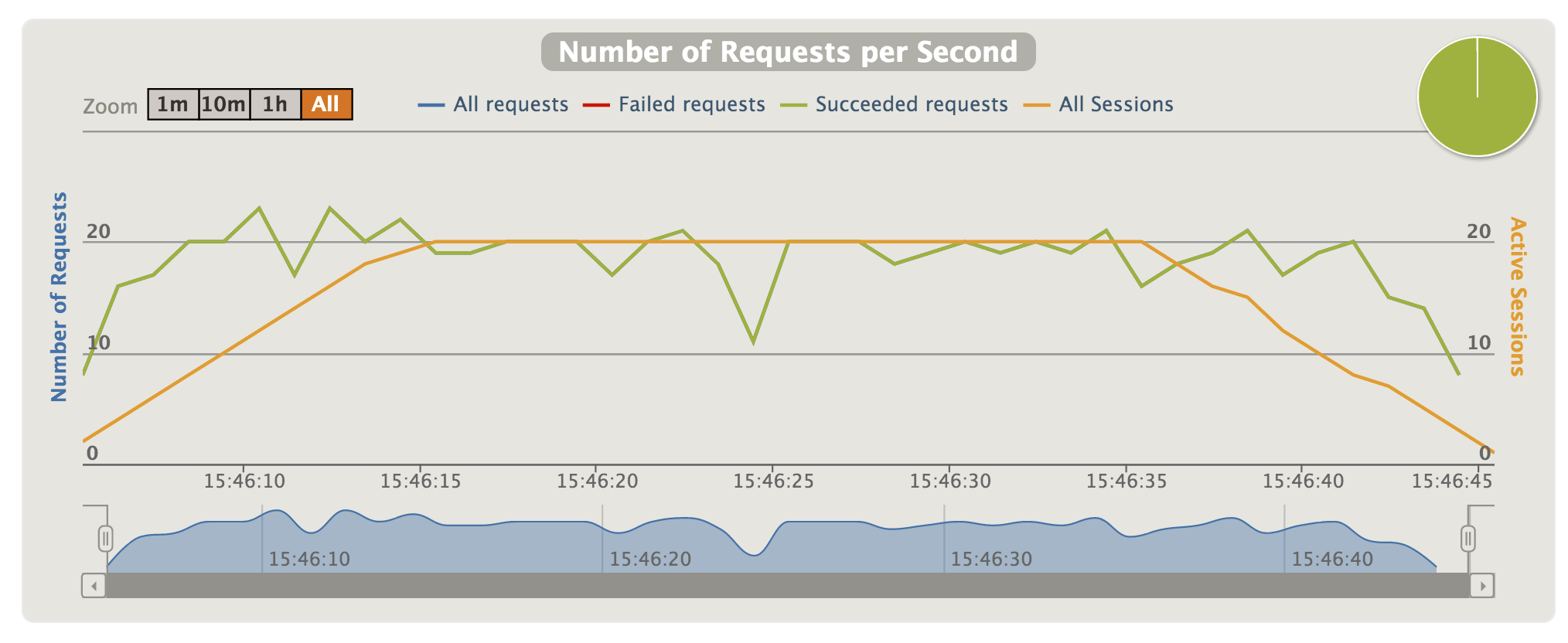
Unlike the friends of a friend tests, the requests time for Neo4j doesn’t stay constant. Our permission resolution algorithm has to travel up the depth of the graph x the 1000 random documents we chose. The deeper the graph the slower it will be. In this sample data set, the depth can be artificially high since it is not bound, but I very much doubt a real world document management system would have files nested 100 directories deep.
How well (lousy) would this fair on a relational database?
A 10 Million row table joined to itself 100 times…omgwtfbbq.

Conclusion
Now that you have finished this three part series, you should know how to:
- Write a graph algorithm using the Java API
- Expose it to REST via an unmanaged extension
- Unit test it
- Create test graphs
- Create performance tests
- Build your own Neo4j Proof of Concept
Up next is a few posts on the Neo4j Traversal API, but also let me know what you’d be interested in reading about in the comment section below.

[…] consider putting SSD drives on these servers as well. You won’t regret it. As always, test, test, test, test your configurations and find the right one for your […]