
At the end of the NODES conference opening Keynote, Neo4j presents a demo of sub 20ms query performance on a graph of 11 shards, 101 shards and 1129 shards. Quite an impressive feat. Then the CEO asks “is this too good to be True?”. TLDR: Yes. Well, let’s find out why.
The “code” for the demo was released on github so we can dive in. We will start with the weirdest part of the code:
if (configStore.isNonMockedDataSource()) {
const session = conn.driver.session({ defaultAccessMode: neo4j.session.READ, database: query.db });
const result = await session.run(query.query, query.params);
session.close();
const { resultAvailableAfter, resultConsumedAfter } = result.summary;
return resultAvailableAfter.toNumber() + resultConsumedAfter.toNumber() + 1;
} else {
const wait = Math.random() * 100 + 10; // 10ms -> 100ms
await sleep(wait);
return wait;
}With that bit of code, you can switch between actually running the query or simulating the query being run and get results from 10ms to 110ms (despite what the comment says). Of course you can change that to be anything you want for example Math.random() * 10 + 10 to get result between 10ms and 20ms. Why would you leave that in your demo code? It clearly shows that they could have shown us any numbers they wanted to for the demo regardless of the query performance.
Ok, so that’s really bizarre, but let’s say they didn’t just blatantly shows us fake numbers even thought they were completely setup for that. Let’s keep digging in. What does the query do? You can see the whole query here, but let’s break it up so it makes more sense.
call {
use fabric.persons
match (p:Person {id:1346680336})-[r:HAS_INTEREST]->(t:Tag)
return t.id as tagId
}We start by using the “persons” shard to find a single person and their interests. The same person every single time since the id is hardcoded, not coming from some list or a generated id. The query is returning the ids of the Tag nodes they are interested in. Assuming they have more than one interest of course, otherwise it would just return one tagId (hint hint). We continue the query:
with distinct tagId
unwind /*shardsForTag(tagId)*/ [g in [g IN range(tagId-10,tagId+10,2) | g % size(fabric.graphIds())] where g>0] as gid
We call distinct on tagId so that we only have unique tag ids just in case a Person node has multiple HAS_INTEREST relationships to the same Tag node (they don’t). Then skipping the comment /*shardsForTag(tagId)*/ we take a tagId and subtract and add 10 to get an array that we are going to step over by 2. So let’s say the tagId is 60. This would give us range(50,70,2) so g would be [50,52,54,56,58,60,62,64,66,68,70] so 11 values. Then we perform the modulo operator. We started with 11 shards, so taking the first value of 50 % 11 is equal to 6. If we do this for 101 and 1129 we get:
[6, 8, 10, 1, 3, 5, 7, 9, 0, 2, 4] // [g in [g IN range(50,70,2) | g % 11 ]]
[50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70] // [g in [g IN range(50,70,2) | g % 101 ]]
[50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70] // [g in [g IN range(50,70,2) | g % 1129 ]]The zero shard id is probably the Persons shard so we eliminate any zeros in this line: where g>0] as gid
call {
use fabric.graph(gid)
with tagId
match (post:Post)-[:HAS_TAG]->(tag {id:tagId})
where post.creationDate = date("2021-04-06")
match (author:Person)<-[:HAS_CREATOR]-(post)
return author.id as authorId, post as post limit 1
}
Next we query 10-11 shards starting with the tag, then to a Post node that has that tag, and the creator of that post. Notice we have a LIMIT 1 tacked on the end of the query, so we return as soon as we find a matching pattern. Is this a realistic production style query? No. Definitely not. But let’s continue on.
with authorId, post order by post.creationDate desc limit 10
call {
use fabric.persons
with authorId
match (author:Person {id:authorId})
return author
}
return author, postHere we sort the post by the creationDate but we know from before the creationDate is always the same from where post.creationDate = date(“2021-04-06”) so that is kind of pointless. Then we limit 10 which doesn’t help if we only have one tag they are interested in (hint hint), but if our user has more than one interest then it does. We then call the Persons shard getting the authors Person node and return the 10 posts and their authors.
What was that about having more than one interest? Let’s see how the data is generated, specifically the interests.
for ( int i = 0; i < BATCH_SIZE && personNodes.hasNext(); i++ ) {
Node person = innerTx.getNodeById( personNodes.next().getId() );
person.createRelationshipTo( innerTx.getNodeById( tagNodeIds.get( random.nextInt( numberOfTags ) ) ), HAS_INTEREST );This bit of code tell us that: each Person node has one and only one HAS_INTEREST relationship to a Tag node. That doesn’t seem like a realistic scenario, does it?

This means that our query is going to make calls against 10 or 11 shards regardless of the size of our graph. So it doesn’t matter that the graph is made up of 11, 101 or 1129 shards. They only query 11 of them each time. No wonder the performance “scales”, the query and dataset have been artificially designed to always do the same amount of “work” regardless of the size of the cluster.
I’m at GraphConnect 2022 and they are still peddling this ”demo”.
It’s shameful.
There is another query in the demo, it is supposed to hit all the shards and you can see it run at 59:30 on the video. But you know what’s weird…when they run the query “live” it returns in 2.2 seconds:

However when it is run in the test harness, it runs in 66ms. Isn’t that weird?
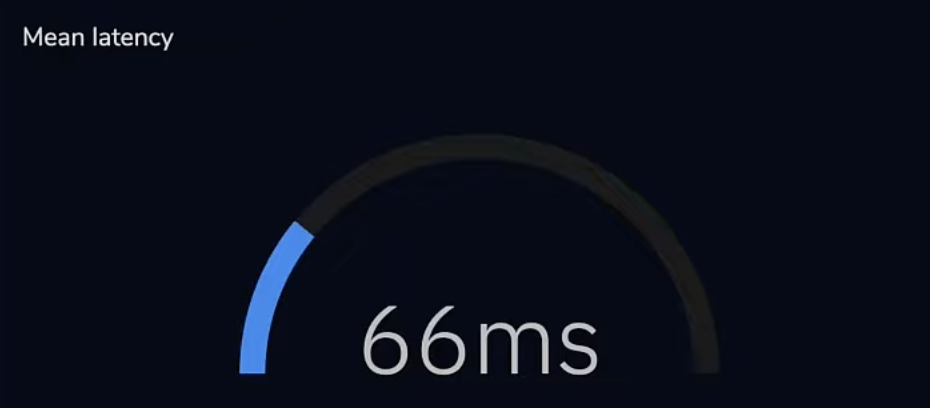
Not sure what to make of that. The live query says it only returns 20 records, so 98% of the time the 1129 shards are coming back with no results what so ever and basically just wasting time. Doesn’t seem very realistic does it?
Update: Looks like Neo4j admits the claims didn’t hold up in this LDBC Council presentation (slide 4).

