
You ever eaten at a “Fusion Cuisine” type of restaurant? It’s a bit of a gamble. Personally I’m always up for eating just about anything… except Pho. That stuff messes me up. But back to fusion cuisine. I think my favorite is Indian and Mexican. Take your favorite Indian dish, wrap that in the warm embrace that is a burrito tortilla, heaven. Well, just about anything wrapped in a burrito is perfect. Why am I taking about Fusion and Wrapping stuff? Well, today we are going to add Auto Complete into our Dating Site, but before we can do that I need to talk to you about Neo4j’s Fusion Indexes and how they wrap the Lucene Indexes as well as our generation-aware B+tree (GB+Tree) indexes.
One of the tricky things about Neo4j is that we don’t enforce types. For any node (even those with the same label), your “phone number” property may be a 9 digit number, may be a string, may be an array of numbers, or strings, or may be something represented by an array of bytes. Neo4j doesn’t care, it’s schema optional, with heavy emphasis on the optional. To deal with this, we have the concept of a Fusion Index, that merges different indexes of different value types into one.
In Neo4j 3.3 we introduced a Native Index for Numbers, in 3.4 we added a Native Index for Strings…and I think in version 3.5 we are planning on adding Native Indexes for all(most?) the types Neo4j supports. Neo4j 3.5 Alphas are already out in the Pre-Release section of the download center and you can expect 3.5 GA to drop before the end of the year (probably a couple of weeks after Halloween).
Ok so why am I telling you all this. Well… In the schema indexes of 3.3 and earlier that used the “die hard” Lucene indexes reads were pretty fast for both STARTS WITH and CONTAINS type of queries. However it was terrible at write speeds. The new Native Indexes are very fast for writes and STARTS WITH, but not so much for CONTAINS. Also neither schema index supports Full Text and Case Insensitive type of searches. So our Auto Complete feature has to take that into account.
We have options, we could use the “Explicit Indexes” which map directly to Lucene Indexes and deal with that. We could modify the “dbms.index.default_schema_provider” parameter to use “lucene-1.0” and get fast CONTAINS, or we can just go with the default for 3.4+ and use the new Native Indexes. In our current use case I want to Auto Complete on “Attribute”, “City”, “Tag” and “Thing” nodes so I will stick with the default native indexes of Neo4j 3.4. If we were adding full text search features to the dating site, we would probably make a different choice.
On to the implementation. Instead of creating an Auto Completes for each thing, we are going to just build one that takes labels and properties as parameters:
@GET
@Path("/{label}/{property}/{query}")
public Response getQuery(@PathParam("label") final String label,
@PathParam("property") final String property,
@PathParam("query") final String query,
@QueryParam("limit") @DefaultValue("25") final Integer limit,
@QueryParam("display_property") final String displayProperty,
@Context GraphDatabaseService db) throws IOException {
We will have a list of allowed Labels:
private static final HashSet<String> labels = new HashSet<String>() {{
add("Attribute");
add("City");
add("Tag");
add("Thing");
}};
…and a list of allowed Properties:
private static final HashSet<String> properties = new HashSet<String>() {{
add("lowercase_full_name");
add("lowercase_name");
}};
… and check that these are being requested by the query:
if (!labels.contains(label)) {
throw AutoCompleteExceptions.labelNotValid;
}
if (!properties.contains(property)) {
throw AutoCompleteExceptions.propertyNotValid;
}
Then we use “StringSearchMode.PREFIX” to indicate we want a “STARTS WITH” type query. Why did we call it that? I don’t know and it doesn’t matter… which reminds me, those are the names that Helene gave her pet turtles back in college. So when people would ask her, what are your turtle’s names, she would sincerely answer “I don’t know” and “It doesn’t matter”. Yes, she is a genius. Alright, for each node in our iterator we pop the id and a display property.
ResourceIterator<Node> nodes =
db.findNodes(Label.label(label), property, query, StringSearchMode.PREFIX);
nodes.forEachRemaining(node -> {
HashMap<String, Object> map = new HashMap<>();
map.put(ID, node.getId());
if (displayProperty != null) {
map.put(displayProperty, node.getProperty(displayProperty));
} else {
map.put(property, node.getProperty(property));
}
results.add(map);
});
So searching for the string we want is fine as long as we clean up the data somewhat. This means removing diacritical marks like accents and umlauts and flipping everything to lowercase. I found a quick and dirty way on stack overflow posted as a gist:
Normalizer.normalize(string, Normalizer.Form.NFD).replaceAll("[^\\p{ASCII}]", "").toLowerCase());
I can use this to convert all my city names, but we have the problem of lots of city names being repeated. To help the user figure out which one they want we will add the state and country into the search field for all cities. What we will do is for each country, go to each state, and for each one get the city name and add a new property combining the name, state and country and cleaning it up:
@POST
public Response transform(@Context GraphDatabaseService db) throws IOException {
try (Transaction tx = db.beginTx()) {
ResourceIterator<Node> countries = db.findNodes(Labels.Country);
while (countries.hasNext()) {
Node country = countries.next();
String countryName = (String)country.getProperty(NAME);
for (Relationship rel : country.getRelationships(Direction.INCOMING, RelationshipTypes.IN_LOCATION)) {
Node state = rel.getStartNode();
String stateName = (String)state.getProperty(NAME);
for (Relationship rel2 : state.getRelationships(Direction.INCOMING, RelationshipTypes.IN_LOCATION)) {
Node city = rel2.getStartNode();
String cityName = (String)city.getProperty(NAME);
city.setProperty(LOWERCASE_FULL_NAME,
Normalizer.normalize(cityName + ", " + stateName + ", " + countryName, Normalizer.Form.NFD)
.replaceAll("[^\\p{ASCII}]", "").toLowerCase());
}
}
}
tx.success();
}
return Response.ok().entity(objectMapper.writeValueAsString("Transformed Cities")).build();
}
We can now use this auto complete in our registration. Flipping to the front end, we can add this to our API. We could have gone with a general auto complete path, but I want to specify city here to make sure I only use the lowercase_full_name property.
@GET("autocompletes/City/lowercase_full_name/{query}")
Call<List<City>> autoCompleteCity(@Path("query") String query,
@Query("display_property") String display_property);
Now in our routes, we just want to bring back some JSON fro this call, making sure to lowercase any user input:
get("/autocomplete/city/{query}", req -> {
Response<List<City>> cityResponse = App.api.autoCompleteCity(req.param("query").value().toLowerCase(), "full_name").execute();
if (cityResponse.isSuccessful()) {
return cityResponse.body();
}
throw new Err(Status.CONFLICT, "There was a problem autocompleting the city");
}).produces("json");
Once we hook this into the UI using something like jQuery Typeahead search, we get a pretty dropdown:
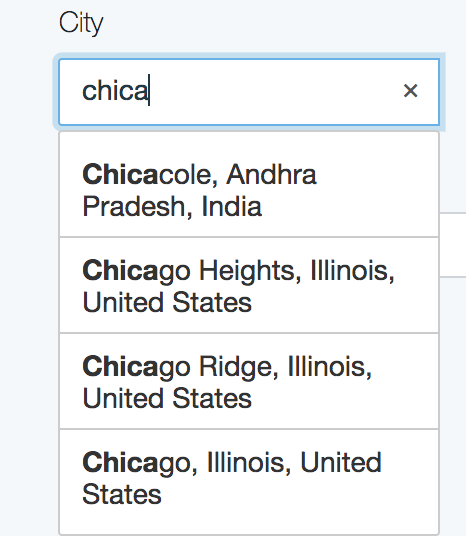
That is being fed by our requests and JSON payloads:

We can use the same ideas for the Attributes and Things.
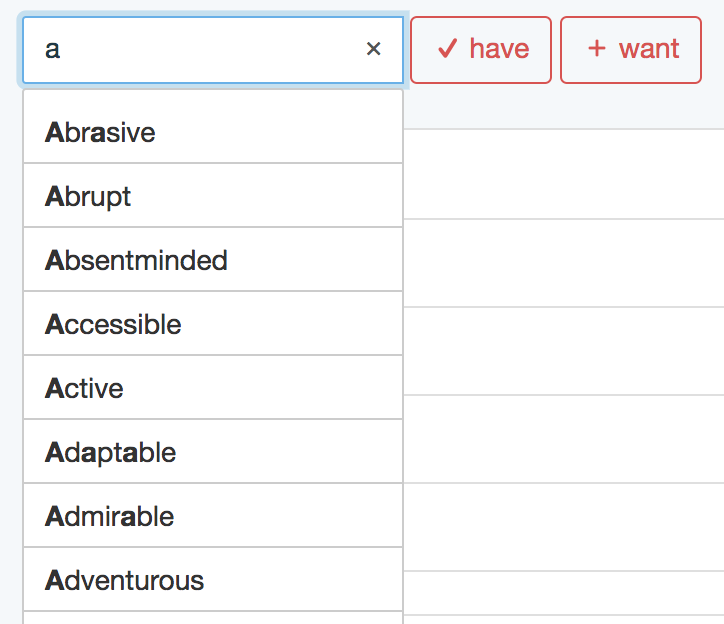
That’s it for autocomplete for our site. Stay tuned for the next part.
