
A few posts ago I showed you how to build a Boolean Logic Rules Engine in Neo4j. What I like about it is that we’ve pre-calculated all our potential paths, so it’s just a matter of matching up our facts to the paths to get to the rule and we’re done. But today I am going to show you a different approach where we are going to have to calculate what is true as we go along a decision tree to see which answer we get to.
Yes, it will be a bit slower than the first approach, but we avoid pre-calculation. It also makes things a bit more dynamic, as we can change the decision tree variables on the fly. The idea is to merge code and data into one, to gain the benefit of agility.
Let’s model a super simple decision tree in Neo4j. Imagine you are a “bouncer” at a club, and the club policy is that anyone over 21 is allowed in, anyone under 18 is not allowed, but they make a special case where women 18 and older are allowed in.
It could look like this in Neo4j:
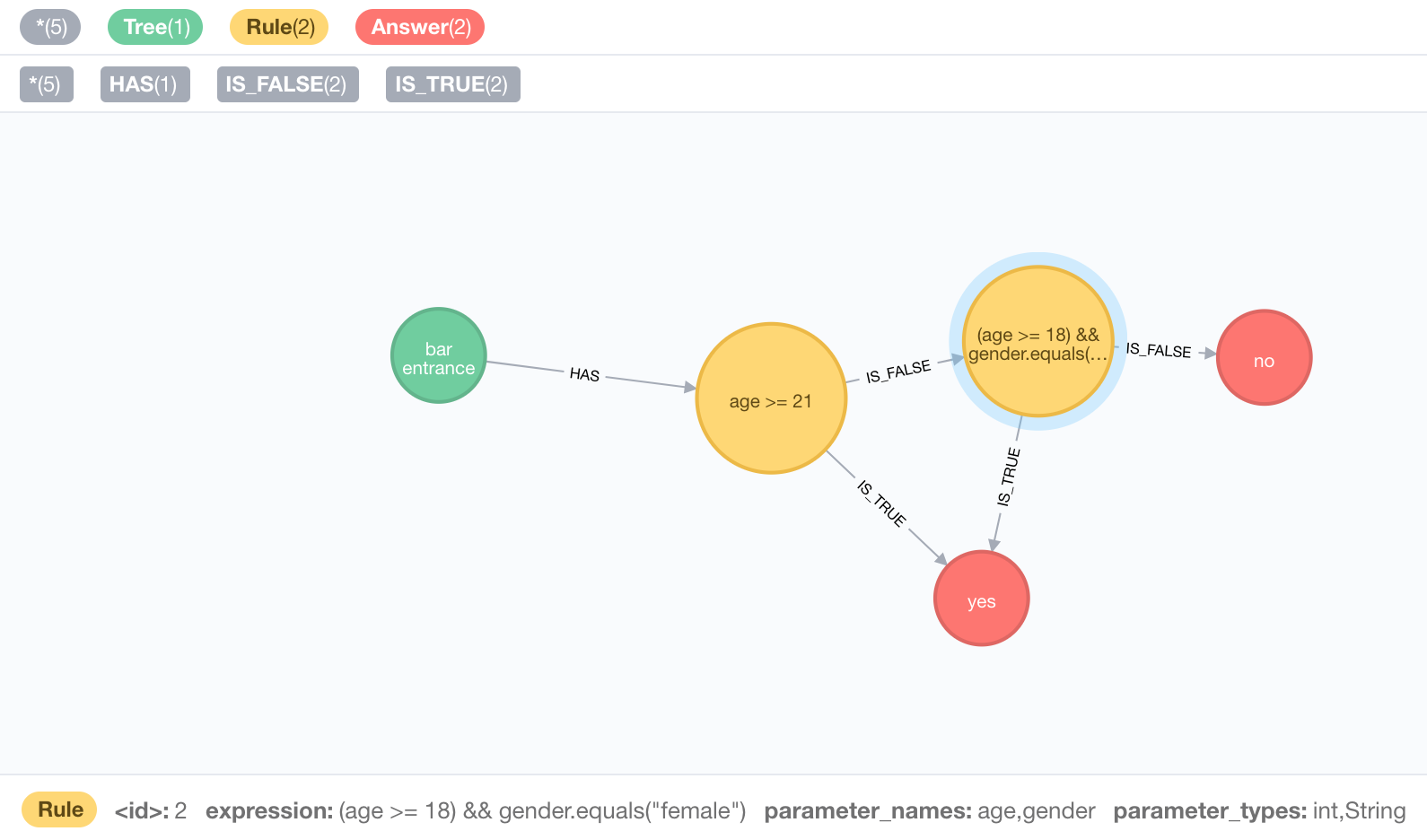
What we have here is a “Tree” node with an id property of “bar entrance” in green, two “Answer” nodes (yes and no) in red, and two Rule nodes in yellow. The first rule node asks, is the age greater than or equal to 21. It has an “IS_TRUE” relationship to the “yes” Answer node, and an “IS_FALSE” relationship to the second Rule node. The second Rule node asks if the age is greater than or equal to 18, AND the gender is “female”. It also has an “IS_TRUE” relationship to the “yes” Answer node, and an “IS_FALSE” relationship to the “no” Answer node.
What we are going to do is build a Cypher stored procedure that takes an id of the decision tree we are going to traverse, and a set of facts. In our case we care about the gender and age facts about the person our bouncer is considering to let into the club. For example we could call the procedure like this:
CALL com.maxdemarzi.traverse.decision_tree('bar entrance', {gender:'male', age:'20'})
YIELD path
RETURN path;
It would return a path, because we want to know how it got to the answer, not just what the answer is. Neo4j is pretty good at traversing nodes and relationships, but it doesn’t really know how to interpret an expression like “age >= 21”. It needs some way to compile that expression and evaluate it. To accomplish this task we can add Janino to Neo4j.
<dependency>
<groupId>org.codehaus.janino</groupId>
<artifactId>janino</artifactId>
<version>${janino.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.codehaus.janino</groupId>
<artifactId>commons-compiler</artifactId>
<version>${janino.version}</version>
<scope>provided</scope>
</dependency>
We will see it in action later, let’s get the stored procedure setup first. We will first find the tree we care about by getting the id in the parameters, and if we find it return the path in our decisionPath method.
@Procedure(name = "com.maxdemarzi.traverse.decision_tree", mode = Mode.READ)
@Description("CALL com.maxdemarzi.traverse.decision_tree(tree, facts) - traverse decision tree")
public Stream<PathResult> traverseDecisionTree(
@Name("tree") String id,
@Name("facts") Map<String, String> facts) throws IOException {
// Which Decision Tree are we interested in?
Node tree = db.findNode(Labels.Tree, "id", id);
if ( tree != null) {
// Find the paths by traversing this graph and the facts given
return decisionPath(tree, facts);
}
return null;
}
Our decisionPath method, will build a TraversalDescription, using a new DecisionTreeExpander for each set of facts, a static DecisionTree Evaluator and return the paths it finds. This is pretty straight forward using Neo4j’s Traversal API.:
private Stream<PathResult> decisionPath(Node tree, Map<String, String> facts) {
TraversalDescription myTraversal = db.traversalDescription()
.depthFirst()
.expand(new DecisionTreeExpander(facts))
.evaluator(decisionTreeEvaluator);
return myTraversal.traverse(tree).stream().map(PathResult::new);
}
Let’s start backwards by looking at that decision tree evaluator. It will simply return a valid path when we get to an Answer node, otherwise it will keep going:
public class DecisionTreeEvaluator implements PathEvaluator {
@Override
public Evaluation evaluate(Path path, BranchState branchState) {
// If we get to an Answer stop traversing, we found a valid path.
if (path.endNode().hasLabel(Labels.Answer)) {
return Evaluation.INCLUDE_AND_PRUNE;
} else {
// If not, continue down this path if there is anything else to find.
return Evaluation.EXCLUDE_AND_CONTINUE;
}
}
Now on to the expander. In the constructor, we will take a Map of facts holding the key and value of the things we know. We will also create a new ExpressionEvaluator and set it to be a boolean type. This means it will evaluate an expression and return true or false.
public class DecisionTreeExpander implements PathExpander {
private Map<String, String> facts;
private ExpressionEvaluator ee = new ExpressionEvaluator();
public DecisionTreeExpander(Map<String, String> facts) {
this.facts = facts;
ee.setExpressionType(boolean.class);
}
The expand method of our Expander tells the Traversal where to go next. If we reach an Answer node, we stop expanding since we made it to a valid path. If we get to a node that has a rules node to evaluate (like the “Tree” node at the root of our Decision Trees) we go get those rules:
@Override
public Iterable<Relationship> expand(Path path, BranchState branchState) {
// If we get to an Answer stop traversing, we found a valid path.
if (path.endNode().hasLabel(Labels.Answer)) {
return Collections.emptyList();
}
// If we have Rules to evaluate, go do that.
if (path.endNode().hasRelationship(Direction.OUTGOING, RelationshipTypes.HAS)) {
return path.endNode().getRelationships(Direction.OUTGOING, RelationshipTypes.HAS);
}
Now, once we get to a Rule Node. We pass it to the isTrue method. If it evaluates to True, it continues down the IS_TRUE relationship. If it evaluates to False, it continues down the IS_FALSE relationship. Pretty straight forward right?
if (path.endNode().hasLabel(Labels.Rule)) {
try {
if (isTrue(path.endNode())) {
return path.endNode().getRelationships(Direction.OUTGOING, RelationshipTypes.IS_TRUE);
} else {
return path.endNode().getRelationships(Direction.OUTGOING, RelationshipTypes.IS_FALSE);
}
} catch (Exception e) {
// Could not continue this way!
return Collections.emptyList();
}
}
Ok, now we are in the isTrue method, what do we do here. First we get the properties of the Rule node. Then we set the parameterNames (which should be a comma separated list of strings) into a String Array. Then we set the parameterType (which should be another comma separated list of strings) into an Array by converting each class name into a Type. So for example a “boolean” will convert to a boolean.class:
private boolean isTrue(Node rule) throws Exception {
Map<String, Object> ruleProperties = rule.getAllProperties();
String[] parameterNames = Magic.explode((String) ruleProperties.get("parameter_names"));
Class<?>[] parameterTypes = Magic.stringToTypes((String) ruleProperties.get("parameter_types"));
Next, we will fill an arguments array with the facts passed into the Expander, set these parameters on our ExpressionEvaluator, “cook” (scan, parse, compile and load) the expression and finally return the output of its evaluation:
Object[] arguments = new Object[parameterNames.length];
for (int j = 0; j < parameterNames.length; ++j) {
arguments[j] = Magic.createObject(parameterTypes[j], facts.get(parameterNames[j]));
}
ee.setParameters(parameterNames, parameterTypes);
ee.cook((String)ruleProperties.get("expression"));
return (boolean) ee.evaluate(arguments);
}
I’ve skipped the “Magic” methods, but you can find them here. That’s all the code we need to write, now to test it. First we need to create our Decision Tree in Cypher:
CREATE (tree:Tree { id: 'bar entrance' })
CREATE (over21_rule:Rule { parameter_names: 'age',
parameter_types:'int',
expression:'age >= 21' })
CREATE (gender_rule:Rule { parameter_names: 'age,gender',
parameter_types:'int,String',
expression:'(age >= 18) && gender.equals(\"female\")' })
CREATE (answer_yes:Answer { id: 'yes'})
CREATE (answer_no:Answer { id: 'no'})
CREATE (tree)-[:HAS]->(over21_rule)
CREATE (over21_rule)-[:IS_TRUE]->(answer_yes)
CREATE (over21_rule)-[:IS_FALSE]->(gender_rule)
CREATE (gender_rule)-[:IS_TRUE]->(answer_yes)
CREATE (gender_rule)-[:IS_FALSE]->(answer_no)
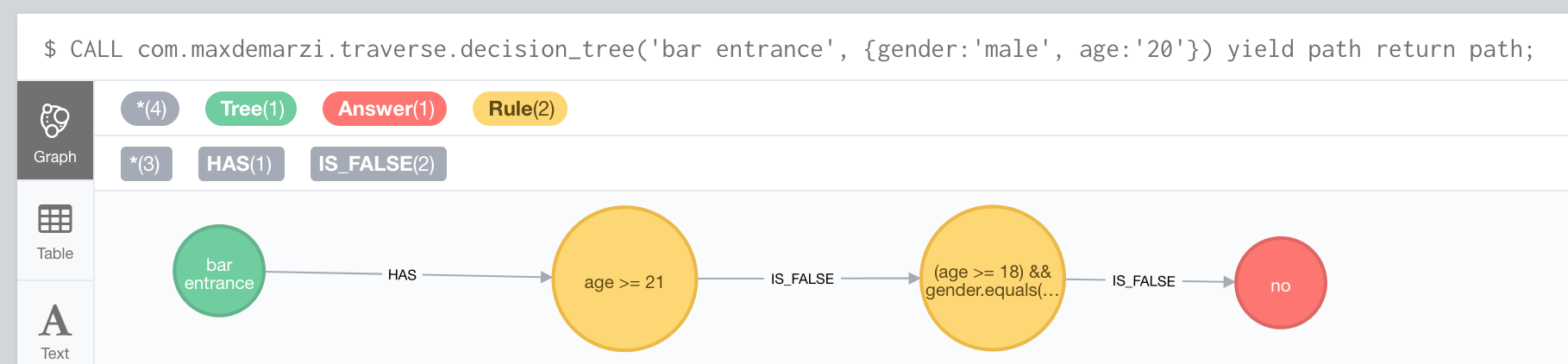
…and call the stored procedure with different parameters. A 20 year old male?
CALL com.maxdemarzi.traverse.decision_tree('bar entrance', {gender:'male', age:'20'})
YIELD path
RETURN path;
Our answer is “No”:
A 19 year old female?
CALL com.maxdemarzi.traverse.decision_tree('bar entrance', {gender:'female', age:'19'})
YIELD path
RETURN path;
Our answer is “Yes”:

Pretty neat right? You can make pretty simple or extremely complicated decision trees and change them on the fly, Neo4j will read the properties of the Rule nodes with every request. You can keep multiple versions of decision trees and compare their results, you can create potential decision trees and run your old facts through, etc.
As always the source code is on github, enjoy.
Part 2 is now published. Also video below:

Great post. I’ve been wanting to rewrite app.hoppa.io (alpha) in neo4j, but haven’t had the time yet.
I looked at this with interest, as I am looking to integrate my rule engine – a potential product (Ritc – ritc.io) – loosely coupled – with neo4j. So our detailed assumptions are different, but our visions seem to be similar, at least from what I see here. I think there is great potential connecting these two technologies.
I’m interested in this. And I want to know why it returns two paths when you import “com.maxdemarzi.traverse.decision_tree(‘bar entrance’, {gender:’female’, age:’19’}) ” ?
That’s an artifact of the Neo4j Browser which “auto connects” nodes when displayed as a graph. In the actual returned result you only get one path.
Got it, thanks.
[…] We’re actually executing this code as we’re running the traversal. We need to bring back Cypher. In this case, that is because we have to build a tree. To build a tree in Cypher, we have to create a tree node and then create some rules. The rule says over 21, the second rule is a gender rule, over 18. We have our answer nodes, and then we connect everything together. Now we have to pass in some facts to our stored procedure and see whether we fail or not. If it’s a male, 20 years old, we pass in gender male. If the male is age 20, we run this query, and it comes back with no. Sorry, you’re staying home. You’re not allowed to go into the club. Not only that, it comes back with a path, which tells us how we get to the answer of no. It went through, “Age over 21?”, nope, and then gender does not equal female. Therefore, he doesn’t get let in. Our second user happens to be a woman who is 19. We run this query, and the answer is true. She’s not over 21, but she is over 18 and a woman. Therefore, she is allowed in. What this has done is taking code as data. This is deliverable to an end user, and the query ran in real time. This use case came from a project where users were building pharmaceutical drug recommendations. These drug recommendations were based on research. The research comes out every quarter, and they have the decision tree of what drug do I give someone based on all the evidence and relevant medical papers. There is a group of doctors who were analyzing this data and building a decision tree based on it. These guys were doing it by hand through just expert knowledge. However, there are other ways to build decision trees. […]
There’s a problem that keeps bothering me. Assuming there are thousands of rules, how can I find the logic among these rules, for example, the order of indicators, and integrate the rules into a tree or forest? And the conclusion must be on the leaf nodes.
Read parts 2-4 and things will make more sense. In part 4 I show you how to create the decision trees from the raw data.
Great post. And interesting POC. However I am having a problem getting it up and running on the latest docker image. I have the config altered accordingly. However the procedures do not seem to be registered. At least they don’t appear to be be so.
I have the plugins folder exposed on the host and the 3 jar files exist there. The only thing I can think of is that they are not being picked up somehow. Am I missing something obvious??
is this available in Python