
I’ve been so busy these last 6 months I just finally got around to watching Luke Cage on Netflix. The season 1 episode 5 intro is Jidenna performing “Long live the Chief” and it made me pause the series while I figured out who that was. I’m mostly a hard rock and heavy metal guy, but I do appreciate great pieces of lyrical work and this song made me take notice. Coincidently on the Neo4j Users Slack (get an invite) @sleo asked…
The Graph has 3 type of Nodes (labels).
Two of them (A) & (C) are connected with a directional relation R of the same type.
Effectively the structure makes up of a big number of disjoint chains that look this way:
(A)-->(C)<--(A)-->(C)<--(A)-->(C)<--(A)-->(C)<-- (A)... (*length of the chain varies)
I need to extract the chain path (with all "C" nodes that it consists of) by requesting the chain with one of the "C"s unique ID (note: All "C" nodes are unique; "A" can be linked to multiple "C"s)
If we color A and C as green and yellow, what he wants to capture is:
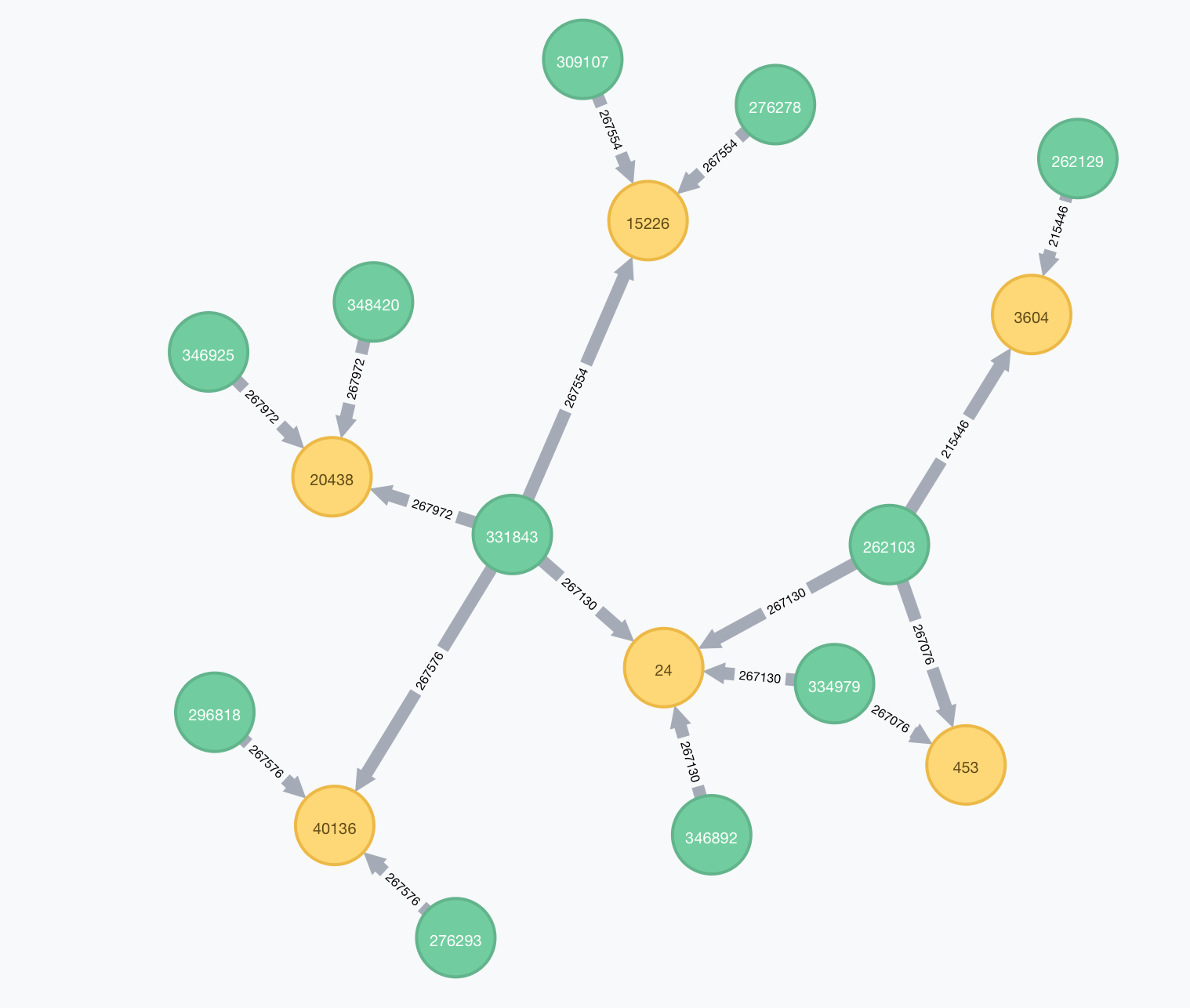
But not the Blue (B) nodes as seen here:
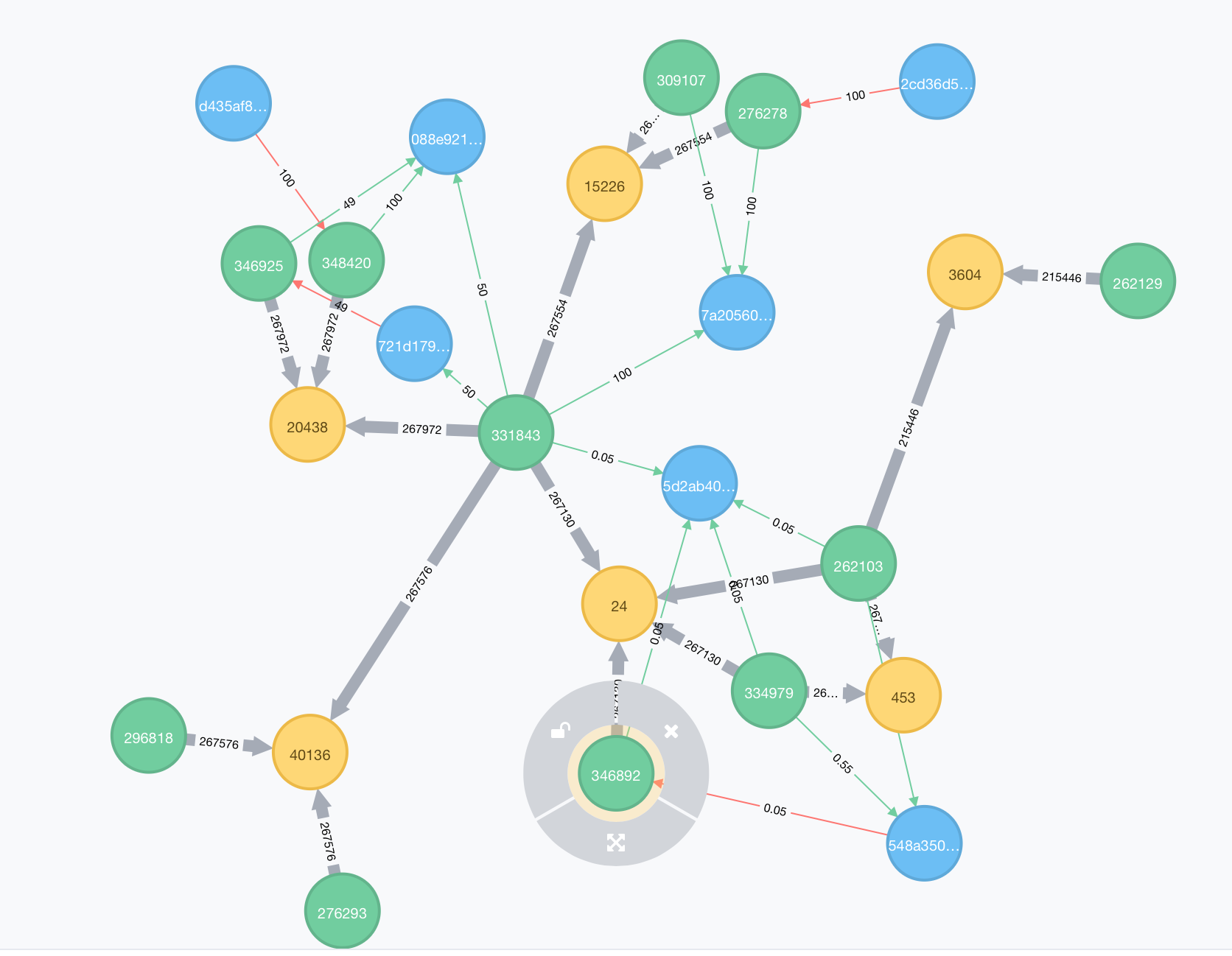
An alternating pattern of node types (A) and (C) and an alternating pattern of relationship directions all the while excluding (B) labeled nodes. So odd vs even… hip hop. Believe it or not the cypher team is working on allowing more complex path descriptions in Cypher but we don’t have time to wait so we’ll make use of the Cypher Stored Procedures feature to make this happen. There is a nice walk-through in the documentation but basically, we’ll start a new Maven project in Intellij and copy and paste a sample pom.xml (our dependencies) file from a template.
Then we create a HipHop class with some @Context annotations:
public class HipHop {
// This field declares that we need a GraphDatabaseService
// as context when any procedure in this class is invoked
@Context
public GraphDatabaseService db;
// This gives us a log instance that outputs messages to the
// standard log, normally found under `data/log/console.log`
@Context
public Log log;
Our procedure has a few more annotations. First a description of what it does, then a procedure annotation with both a name and a mode. The mode tells us if this procedure will read, write, alter the schema of the database, etc. In our case we’ll call it “hiphop” and note that is a read only procedure. It takes a node as a parameter which we will use to start our traversal. The traversal expands and evaluates using a custom expander and evaluator. We’ll get to these in a moment. Finally it returns the paths found by the traversal in another class called PathResult.
@Description("com.maxdemarzi.hiphop(node) | Return Paths starting from node alternating pattern")
@Procedure(name = "com.maxdemarzi.hiphop", mode = Mode.READ)
public Stream<PathResult> hiphop( @Name("startNode") Node startNode) {
TraversalDescription myTraversal = db.traversalDescription()
.depthFirst()
.expand(hipHopExpander)
.evaluator(hiphopEvaluator);
return myTraversal.traverse(startNode).iterator().stream().map(PathResult::new);
}
PathResult is a super simple class that has a public “path” declaration and a constructor that sets it. The thing to note is the name of the variable “path”. We will use this when yielding from the result of our call.
public class PathResult {
public Path path;
PathResult(Path path) {
this.path = path;
}
}
The expander is pretty trivial. If we reach a “B” labeled node, we stop traversing. Otherwise depending on whether or not the length of the path is odd or even, we follow the incoming our outgoing relationships of the last node we traversed.
public class HipHopExpander implements PathExpander{
@Override
public Iterable<Relationship> expand(Path path, BranchState branchState) {
if (path.endNode().hasLabel(Label.label("B")) {
return Collections.emptyList();
}
if (path.length() % 2 == 0) {
return path.endNode().getRelationships(Direction.INCOMING);
} else {
return path.endNode().getRelationships(Direction.OUTGOING);
}
}
The evaluator makes double sure no pesky “B” nodes make it into our result set by excluding them.
public class HipHopEvaluator implements PathEvaluator {
@Override
public Evaluation evaluate(Path path, BranchState branchState) {
if (path.endNode().getLabels().iterator().next().name().equals("B")) {
return Evaluation.EXCLUDE_AND_CONTINUE;
} else {
return Evaluation.INCLUDE_AND_CONTINUE;
}
}
Now we could stop here, but we’re not finished if we don’t test our hip hop.

We create another class, “HipHopTest” with a fixture that contains our sample database and with the HipHop procedure we created:
public class HipHopTest {
@Rule
public final Neo4jRule neo4j = new Neo4jRule()
.withFixture(MODEL_STATEMENT)
.withProcedure(HipHop.class);
Our test graph is pretty simple. It’s just a cypher statement that builds the following relationships:
private static final String MODEL_STATEMENT =
// (c1)<--(a1)-->(c2)<--(a2)-->(c3)
// (c1)<--(a1)-->(b1)<--(a2)-->(c3)
"CREATE (c1:C {id:'c1'})" +
"CREATE (a1:A {id:'a1'})" +
"CREATE (b1:B {id:'b1'})" +
"CREATE (c2:C {id:'c2'})" +
"CREATE (a2:A {id:'a2'})" +
"CREATE (c3:C {id:'c3'})" +
"CREATE (c1)<-[:RELATED]-(a1)" +
"CREATE (a1)-[:RELATED]->(c2)" +
"CREATE (c2)<-[:RELATED]-(a2)" +
"CREATE (a1)-[:RELATED]->(b1)" +
"CREATE (b1)<-[:RELATED]-(a2)" +
"CREATE (a2)-[:RELATED]->(c3)";
Our test method will use the rest api to call it, although we could have used bolt too, whatever. I’m taking the lazy route here and just making sure I get 5 paths back. There are only 5 paths because we start with a single c1 node path and make our way to c3 path. Skipping any paths with B labeled nodes.
@Test
public void testHipHop() throws Exception {
HTTP.Response response = HTTP.POST(neo4j.httpURI().resolve("/db/data/transaction/commit").toString(), QUERY);
int results = response.get("results").get(0).get("data").size();
List<Map> results = (List<Map>)actual.get("results");
assertEquals(5, results);
}
Our query starts by finding “c1” and then calling our hiphop stored procedure yielding path and returning it as seen below:
private static final HashMap<String, Object> PARAMS = new HashMap<String, Object>(){{
put("id", "c1");
}};
private static final HashMap<String, Object> QUERY = new HashMap<String, Object>(){{
put("statements", new ArrayList<Map<String, Object>>() {{
add(new HashMap<String, Object>() {{
put("statement", "MATCH (c1:C {id: $id}) CALL com.maxdemarzi.hiphop(c1) yield path return path");
put("parameters", PARAMS);
}});
}});
}};
It passes as expected. Now you’ve seen me write a ton of “Unmanaged Extensions” and these always start with opening a transaction and closing it at the end. In a procedure however you are put already inside a transaction, so you don’t have to worry about transaction management at all. You don’t have to worry about what http endpoint your extension will live, and you can actually make nodes or relationships as your parameters, not just numbers and strings. I think they are pretty cool, so when you find yourself unable to express what you want in Cypher directly, just write a stored procedure and you are back in business. The code is on github as always.

I cannot help but mention the stored procedure compiler that helps resolve some common mistakes at compilation time: https://github.com/neo4j/neo4j/tree/3.2/community/procedure-compiler (available since 3.1).
More context here: https://fbiville.github.io/2016/07/12/Compilers-hate-him-Discover-this-one-weird-trick-with-Neo4j-stored-procedures.html.
[…] build ourselves another Cypher Stored Procedure. We’ll call this one dimensionalSearch and take a map parameter as […]
[…] is taking about 240ms with our simple dataset. So we are going to try to speed it up by building a cypher stored procedure. We will make it dynamic so we can take two or more labels. We’ll use my favorite library […]
[…] will see it in action later, let’s get the stored procedure setup first. We will first find the tree we care about by getting the id in the parameters, and if […]