
I could not decide if I wanted a Rhinoceros or Cthulhu as a mascot for this new project, so I went with both. The image you see above is what I ended up with. It’s absolutely outrageous and fits perfectly with our theme. That was going to be the name by the way “Outrageous DB” but it was kind of long, so I went with “Rage DB” instead. Right about now you may be thinking, wait, what are we doing, what is this new project? What is going on?
Well you see, over the last few months I’ve been taught that you are supposed to work backwards. Typically the last thing you do is come up with a mascot, so we’re doing that first. Maybe we look at where computing is going to be in a decade plus or minus a few years and design backwards for that future. Given the current state and trends in hardware it is not hard to imagine database servers running 1024 core 3.5GHz chips with 64TB of RAM. But you don’t have to take my word for it, take Brendan Greggs view of the future.
Hold on, I’m being told I went too far. I’m supposed to work backwards from the customer. Ah….Ok so let’s do that. It’s my project so I’m the customer. What do I want? I literally only want one thing and it’s a better graph database. Ok, but better how? Well it has to give us better performance, and handle more diverse workloads. In the past I’ve said that graph databases aren’t very good at telling you the average height of all Hollywood actors, but they are good at telling you the six degrees of Kevin Bacon. I think they could be better at both.
Ok, what else? It has to be easy to talk to? Are we still talking about a database? Yes, I mean it needs to listen in HTTP and respond in JSON. These things are ubiquitous and readily available. No custom binary protocol that needs drivers built for every language. So you can use it as is, or build a light wrapper around it in your favorite language for syntactic sugar.
Keep going… It needs to speak my language. Like what? Spanish? What are we talking about? I mean it needs to understand a programming language instead of forcing us to both learn a query language. After a few decades in the database space, the one thing that hasn’t changed is that both the developers “using the database” and the developers “building the database” always end up wasting a lot of time on query optimization. This time suck needs to stop.
Anything else? It needs to be multi-threaded unlike my previous project. Distributed software is hard, very hard. I think too may database software vendors are headed down a single path when there are two. Many core big RAM servers are in the future, we need to go where the future is. Ok Nostradamus, is that all? It needs to be in C++. But we don’t even know C++. Right, but that’s never stopped anyone before. We’ll pick it up along the way and maybe even get our audience to help us out, how hard can it be?
Alright, what’s our approach? Shared Nothing.
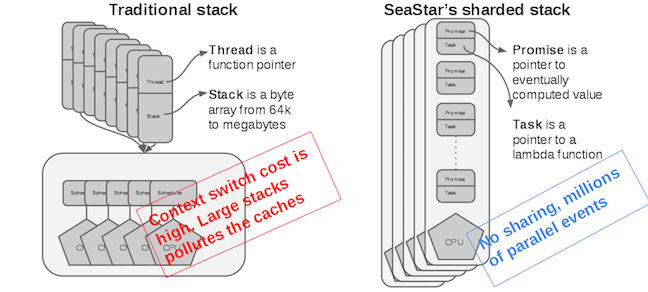
You can’t do shared nothing shards on a graph, that’s one of those NP-Hard unless P=NP problems. Right so we’ll share a little bit, we’ll take the relationship object and split it up. The properties of the relationship as well as the outgoing chain of relationships will belong to the same shard as the node starting the relationship. The incoming chain of relationships will belong to the “other” node. Each link in the chain will track the other node id together with the relationship id. Visually it looks a little something like this:

So instead of a shared object that needs to locked every time we mess with it so another thread doesn’t ruin it, we’ll have two objects living in two shards (or possibly the same shard) that only a single core each can mess with, so we won’t have to take locks. Are you sure about this? They’ve done studies you know, 60% of the time, it works every time. That doesn’t make sense. Anyway how do we figure out which shard a node belongs to in the first place?
We derive the shard_id which represents a physical core in our server from a 64 bit hash generated from the node “type” and “key” which are user defined. A node “type”? Don’t you mean “label”? No. Allowing nodes to have multiple labels was a terrible idea, we’ll find another way to make groups later, for now every node has one and only one “type”. Let me give you an example: a node of type “User” with a key of “max” could generate a hash 123456… and given a 4 core server end up with shard_id 2, so it belongs to that shard. Just so we’re clear, the properties, the outgoing relationships and any of their properties all belong to that same shard 2.
When a node is added to a shard, it is given an internal id for array style access and an external id which contains both the shard_id and the internal id bit shifted. So Node 1 on shard 0 has an external id of 256, Node 1 on shard 1 is 257, Node 2 on shard 0 is 512, etc. Wait so this only goes up to 256 shards? Yes, how many servers do you run with more than 256 physical cores right now? Touché, but I thought Brendan said 1024…
So we have one database split into multiple shards is that it? Nope, I skipped a step. We have one database which contains many graphs, each of which is split into shards. Some people will always want multi-tenancy, so we’re going to bake it right in from the start instead of bringing it in later as an afterthought. Will we be able to query across graphs? No. No man… I believe you’d get your ass kicked saying something like that.
Each shard owns the data it holds and nothing more… except for shard 0. This shard is special as we do need to have a few locks which it will own. The first lock is the node type lock to convert node type strings into ids and copy them to the other shards so they all agree. The second lock is the same but for relationship types. What about property keys? I don’t want to have to do a bunch of checking when dealing with properties so each shard will just hash them into a 64 bit number and hope we don’t run into conflicts. We’re going to need a JSON parser so I’ll bring in the simdjson library and to keep track of numeric ids we can use Roaring Bitmaps both from Daniel Lemire. For our maps we’re going with tsl::sparse_maps from Thibaut Goetghebuer-Planchon. I’m also bringing in LuaJIT from Mike Pall and Sol from JeanHeyd Meneide to connect it to our database.
Lua? What on earth for? We’re stealing a page from Tokyo Cabinet and Redis, and using Lua as our language for complex queries. We’re not going to use a query language, we’re going to use a programming language. Why are we doing this? Well it has been my experience that you cannot take a graph project to production without at least one pluggable or custom stored procedure to handle a complex query. So instead of teasing people with an easy to use declarative query language that you end up throwing away as queries get complex or a the mental acrobatics required to write complex queries in the first place, we’re just going to dive right into to a simple programming language.
I can’t follow all that text, give me a picture I can stare at please:
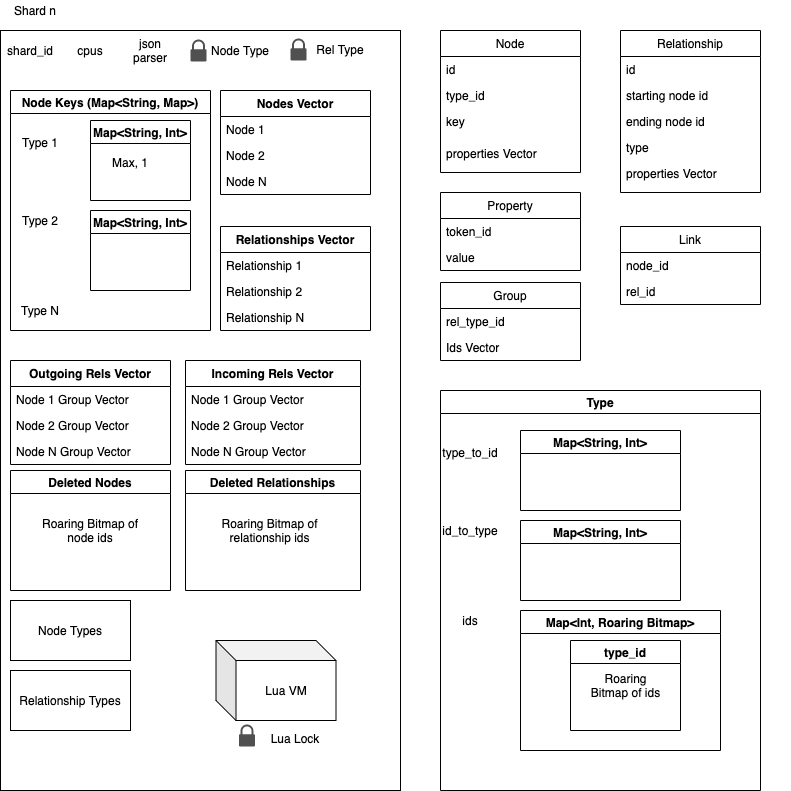
What we’re looking at above is the bits and pieces of a single shard. Notice the Lua Lock near the bottom on that Lua VM. This means that a shard can only run one Lua “script” at a time. Should we add more? Will that just make a mess? Not sure yet. What’s the deal with the properties Vector for both Nodes and Relationships? It allows any node or relationship to have any number of properties of any type which is great in theory, but horrible in practice when it comes to performance.
Our ids are 64 bits, and can steal 8 for 256 core ids, leaving us with 56 bits for ids which is extremely large. We can steal 10 for 1024 and leave 54 which is still a ton. Could we move the type_id into the id? 38 bits gives us about 275 billion ids, so we could use 16 bits for the type giving us 65536 node types and 65536 relationship types. Is that enough or would 36/20 be better? What about properties? In that design they are stored in a vector per node, that doesn’t seem optimal. Maybe we can try a column based approach to storing properties, but that would require Schema. Can we have the best of both worlds? I have some ideas.
But enough about the data structures, let’s talk about the methods. Imagine if you will a cake. A 3 layered cake. That’s the design we’re starting with. The bottom layer is made up of the singular shard methods which operate only on a single shard (duh). The middle layer has the peered methods which may call singular shard methods on multiple shards, the top layer is all frosting and Lua methods meant to be run synchronized which just call the peered methods without function overloading so we don’t confuse anybody (and not lose any performance figuring it out). The peered methods have to figure out which shard or shards to send their requests to and try to minimize multi-shard operations.
As an example if we are creating a relationship and both nodes of that relationship happen to be on the same shard, we call one single shard method to handle this case instead of calling two single shard methods on the same shard. When traversing relationships, the shard ids of the “other” nodes are used to group requests together to each shard in a batch instead of sending many requests one at a time.
There are two Execution Flows:
HTTP Request -> Peered Method -> Sharded Method(s) -> Result to JSON
HTTP Request -> Lua – Synchronized Wrapper -> Peered Method(s) -> Sharded Method(s) -> Result to JSON
Every main stream programming language already has libraries to connect via HTTP and consume JSON, you can use your browser or a browser plugin like “advanced rest client” to talk to the database if you want. By having an HTTP only interface, we skip having to find developers that are experts in many different languages to build and maintain custom drivers in every language we want to support. It’s a nightmare, believe me. By using JSON we can skip building a custom protocol and to be honest 99.9% of the time the end user will just use JSON in and out of their application. This goes against the request of being the fastest we can be, but it’s a good compromise for wider adoption and ease of use. We can always add other options later.
At the heart of it all is the Seastar library from the makers of ScyllaDB which takes care of the coordination between shards and even gives us an HTTP server with metrics for Prometheus as an added bonus. It’s also being used by Vectorized.io in their Red Panda event streaming platform and Ceph for their distributed storage system.
I built an initial proof of concept sitting at https://github.com/maxdemarzi/triton which you can take a look at right now if you’d like. It’s a little over 10k lines of C++ code including some unit tests. It’s all in memory with zero durability for now. If you stop the program (or it crashes) it will restart empty. Huge disclaimer: I have been writing Java code almost exclusively for the last 8 years and Ruby before that, so I didn’t know C++ when I wrote that. I still don’t know C++ but I didn’t know it then either. We are not going to use that repository for this blog series since it’s a “first draft”, instead we’re going to manually fork it and beyond incrementally so we all learn from my mistakes together, and hopefully I convince some of you to help. That repository sits on https://github.com/ragedb/ragedb
Can we really build a database in a few blog posts? No. It still takes a team of folks and a few years of hard labor, but we can build something right now. Stay tuned for Part 2.
