
Sometimes I contrast Neo4j against relational databases by saying Neo4j is more like a dynamic typed language, and relational databases are more like a static typed language. In Neo4j you don’t have Tables or table definitions, any property can be of any valid value (Java primitives, arrays of Java primitives as well as time and spatial types). Two nodes with the same Label can have completely different properties, and any key can be of any type for different nodes. So for example a User labeled node may have the “id” property be “xyz”, while the “id” property for a Location labeled node may be a spatial type… but another User labeled node may also have the “id” property be a number or an array of floats, or whatever. This kind of freedom can drive people crazy, but it can also be leveraged to make very dynamic applications easy.
Let’s take an application where Users are able to make Forms for people to fill out. The responses of the forms are tied together into projects, and typically a person fills out one or more of the forms in a single project. Users then want to look at these responses over various forms and filter across them. For example people filled out the value 1 for field “xyz” in form “f3”, and we want to see how they filled out form “f4”. We’ll add a second filter based on form “f4” and now look at how the filled out form “f5”, and so on. Kind of like a fancy reverse osmosis water filter.

Let’s create a model for this data. From the description of the application, we need a few kind of nodes: Project, Form, Field, and Person. The Project has People and Forms, the Forms have Fields, the Person has Values. Let’s tie these together:

Let’s try a query. I want to see all the responses to “Form 3” in “Project 1” by people who answered:
- “abc” to “Field 1” in “Form 1”
- 123 to “Field 2” in “Form 1”
- “xyz” to “Field 19” “Form 2”
Let’s write a Cypher query to get the answer:
MATCH (prj:Project {id:'Project 1'})-[:INCLUDES]->(p:Person),
(p)-[hv:HAS_VALUE]->(f:Field)
WHERE f.id = 'Field 1' AND hv.value = "abc"
WITH DISTINCT p
MATCH (p)-[hv:HAS_VALUE]->(f:Field)
WHERE f.id = 'Field 2' AND hv.value = 123
WITH DISTINCT p
MATCH (p)-[hv:HAS_VALUE]->(f:Field)
WHERE f.id = 'Field 19' AND hv.value = "xyz"
WITH DISTINCT p
MATCH (p)-[hv:HAS_VALUE]->(f:Field)<-[:HAS_FIELD]-(form:Form)
WHERE form.id = "Form 3"
RETURN p, f, hv
ORDER BY p, f.id
Let’s break the query down. We start off by finding the Project we are interested in and getting all the Person nodes in the project. Then we add our first filter that checks the value of “Field 1” and only allows the Person nodes that responded “abc” to pass through to our next filter. We repeat this two more times for the second and third filter, and at the end we get all the responses to “Form 3” for any users that made it through all the filters.
Assuming we have unique “id” properties for all the Fields, we don’t even have to link to the intermediate Form nodes. However if we didn’t, we can add them to our filter pattern:
MATCH (prj:Project {id:'Project 1'})-[:INCLUDES]->(p:Person),
(p)-[hv:HAS_VALUE]->(f:Field)<-[:HAS_FIELD]-(form:Form)
WHERE f.id = 'Field 1' AND hv.value = "abc" AND form.id = "Form 1"
...
So the query is simple, but a bit long and it has one obvious problem. We traverse the responses from Person to Field multiple times. Every time it’s with less and less Person nodes, but still that kind of sucks. Can we do better? Well what if we traversed the responses from every Person node to their Field nodes just once and collected the answers we cared about along the way? Then we checked their values and made sure they were all what we wanted. It could look something like this:
MATCH (prj:Project {id:'Project 1'})-[:INCLUDES]->(p:Person),
(p)-[hv:HAS_VALUE]->(f:Field)
WHERE f.id IN ['Field 1', 'Field 2', 'Field 4']
WITH p, COLLECT({field:f.id, value:hv.value}) AS answers
WHERE ALL (x IN answers WHERE
(CASE x.field WHEN 'Field 1' THEN x.value = "abc"
WHEN 'Field 2' THEN x.value = 123
WHEN 'Field 4' THEN x.value = "xyz"
END))
WITH DISTINCT p
MATCH (p)-[hv:HAS_VALUE]->(f:Field)<-[:HAS_FIELD]-(form:Form)
WHERE form.id = "Form 3"
RETURN p, f, hv
ORDER BY p, f.id
There’s one thing that still bothers me about this query. We are checking the response of every answer for every person in the project. If we had lots of forms and lots of answer this may be a lot of unnecessary work. There seems like there is something missing in our model that would allow us to do this. To make it even more obvious let’s complicate things by adding the requirement that a Person can fill out forms one or more times, and that the responses of those forms are linked together.
Take moment to think about how this affects our model. Can you see the missing piece? We’ve mentioned it multiple times as a concept but not materialized it in our model. The missing concept is Responses. In this model a Person will have many Responses which may be of the same form or multiple forms. These responses may be linked together. Instead of going from Person to Field, we now go from Response to Field since the values could be different every time they fill out the form.
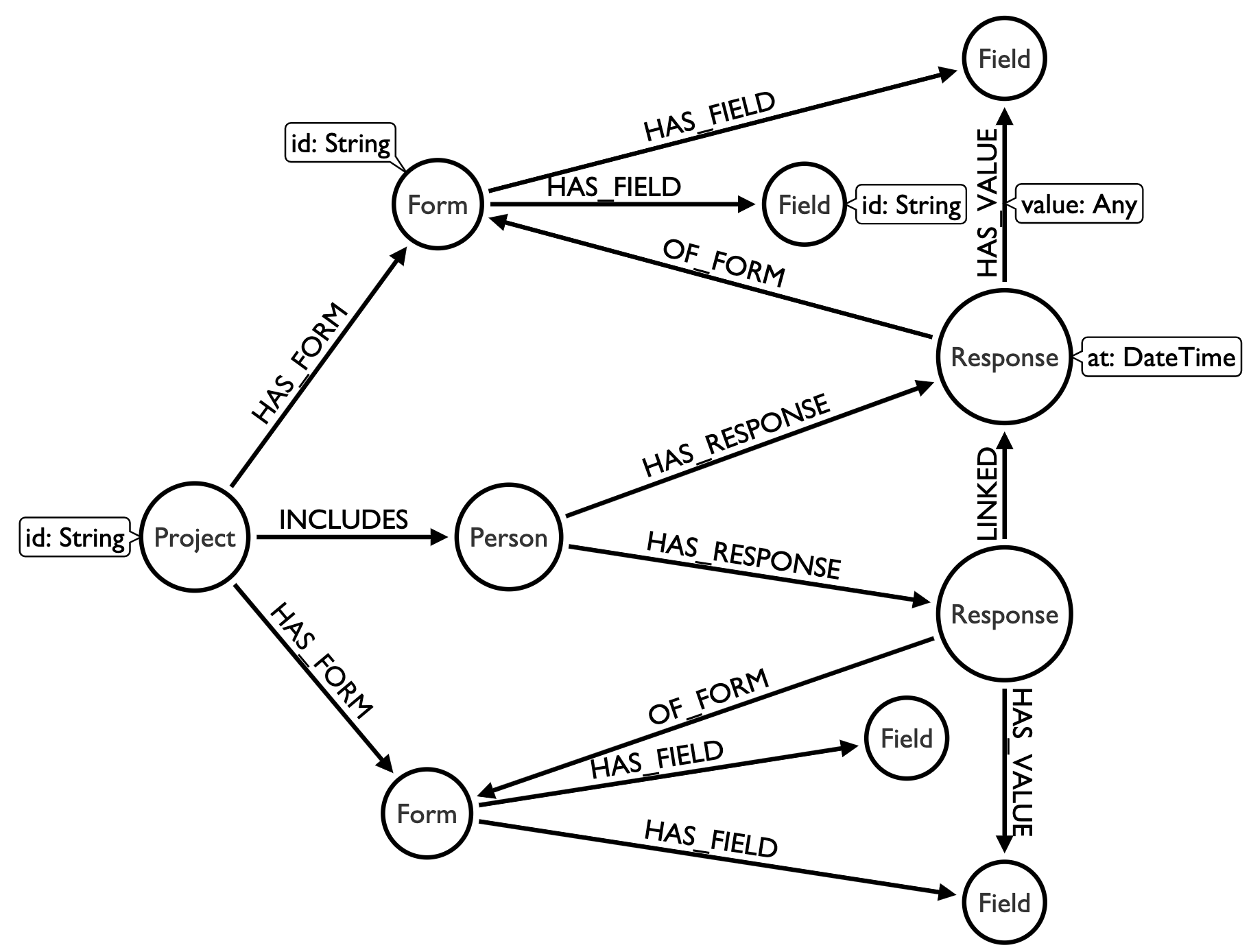
So now how would we write our query? Let’s start by first finding the relevant responses of everyone in the project:
// Start with everyone on the Project
MATCH (prj:Project {id:'Project 1'})-[:INCLUDES]->(p:Person),
// Gather all of their relevant responses
(p)-[:HAS_RESPONSE]-(r:Response)-[:OF_FORM]->(form:Form)
WHERE form.id IN ['Form 1', 'Form 2', 'Form 3']
WITH p, COLLECT(r) AS responses
Since every user can have multiple responses to a form, we can’t use the gather all the field values tactic we did before, but since we’re limiting ourselves to only valid responses anyway it won’t be a big deal to use the tactic from our first query and handle each filter one at a time. I’ll comment in query so you can see what I’m doing:
// First Filter (Field 1, value "abc") // Gather all responses to Field 1 from available relevant responses MATCH (r2)-[:LINKED*0..]-(r)-[hv:HAS_VALUE]->(f:Field) WHERE f.id = 'Field 1' AND r IN responses // track potential linked responses in r2 using "0*" and collect answers WITH p, responses, hv, COLLECT(DISTINCT r2) AS found, COLLECT(hv) AS hvs // Make sure we have at least 1 valid answer from the person WHERE ANY (x IN hvs WHERE x.value = "abc") // Remove responses and their chains for invalid values WITH p, [x IN responses WHERE NOT x IN CASE WHEN hv.value = "abc" THEN [] ELSE found END] AS responses
Now we have eliminated some person nodes all together. The person nodes remaining may have had some of their responses filtered out, but they still have at least one valid response. Now on to the second filter:
// Second Filter (Field 2, value 123) MATCH (r2)-[:LINKED*0..]-(r)-[hv:HAS_VALUE]->(f:Field) WHERE f.id = 'Field 2' AND r IN responses WITH p, responses, hv, COLLECT(DISTINCT r2) AS found, COLLECT(hv) AS hvs WHERE ANY (x IN hvs WHERE x.value = 123) WITH p, [x IN responses WHERE NOT x IN CASE WHEN hv.value = 123 THEN [] ELSE found END] AS responses
Which looks just like the first filter. The third filter is the same, so we’ll omit it and instead see the end of the query:
UNWIND responses AS response // With valid left over responses, gather values for the form we want MATCH (response)-[hv:HAS_VALUE]->(f:Field)<-[:HAS_FIELD]-(form:Form) WHERE form.id = "Form 3" RETURN p, response, f, hv ORDER BY p, response.at, f.id
There we have it. Four lines of code to start, 5 lines of code to end, and 5 lines of code for each filter. Give this a try using SQL in a relational database and let me know when your eyes start to bleed.
People forget that SQL is the 45 year old static typed language of data, isn’t it time we started talking about data differently with Cypher and Neo4j?
