Graphs are everywhere. Think about the computer networks that allow you to read this sentence, the road or train networks that get you to work, the social network that surrounds you and the interest graph that holds your attention. Everywhere you look, graphs. If you manage to look somewhere and you don’t see a graph, then you may be looking at an opportunity to build one. Today we are going to do just that. We are going to make use of the new Neo4j Import tool to build a graph of the things that interest Hacker News.
The basic premise of Hacker News is that people post a link to a Story, people read it, and comment on what they read and the comments of other people. We could try to extract a Social Graph of people who interact with each other, but that wouldn’t be super helpful. Want to know the latest comment Patio11 made? You’ll have to find their profile and the threads they participated in. Unlike Facebook, Twitter or other social networks, Hacker News is an open forum.
So instead we are going to be looking at the topics of interest. Hacker News uses Algolia to power its search results and they provide an API we can use.
![]()
We are going to download the story id, the author, the URL and the usernames of commenters of each story. That by itself is a graph. A graph of commenters, but not enough. What would be more useful is to understand what each story is all about. So here we turn to recent Big Blue acquisition Alchemy API.

We will use the Alchemy API ruby gem by Technekes to pass in a story url and get back a list of relevant keywords about that story. Something along the lines of:
require 'alchemy_api' AlchemyAPI.key = "go get your own key" results = AlchemyAPI::KeywordExtraction.new.search(url: "http://my.interesting.story")
Alchemy API is kind enough to give us 1000 calls a day for free, so we’ll use the Glutton Rate Limit gem to be civil and leave this running for a few days. I don’t have the patience to wait for the hundreds of thousands of stories submitted to Hacker News to process, so we’ll just take a sample of them for our purposes.
We’ll take our data, and produce a set of node and relationship files the import tool can use. For example our users file ( user_nodes.csv ) is very simple. We know the usernames of Hacker News are unique, so we’ll use that for our Identifier and label these nodes “User”.
username:ID(User),:LABEL bootload,User eru,User roc,User cabalamat,User cousin_it,User
The story file ( story_nodes.csv ) is very similar, but urls can be repeated, so instead we will use the story id.
story_id:ID(Story),url,:LABEL 363,"http://news.ycombinator.com/item?id=363",Story 9172373,"https://www.apple.com/macbook/",Story 7525198,"https://blog.mozilla.org/blog/2014/04/03/brendan-eich-steps-down-as-mozilla-ceo/",Story 7408055,"http://techcrunch.com/2014/03/15/julie-ann-horvath-describes-sexism-and-intimidation-behind-her-github-exit/",Story
We are just missing Topics ( topic_nodes.csv ) which will use their topic name as their identifier.
name:ID(Topic),:LABEL "best engineers",Topic "startup culture",Topic "project teams",Topic
Next we need the Author to Story relationships ( author_rels.csv ). Our header shows us we are connecting User Nodes to Story Nodes by the “AUTHORED” relationship:
:START_ID(User),:END_ID(Story),:TYPE pg,363,AUTHORED NickSarath,9172373,AUTHORED platz,7525198,AUTHORED
We will do the same for commenters ( comment_rels.csv ) :
:START_ID(User),:END_ID(Story),:TYPE bootload,1000464,COMMENTED eru,1000464,COMMENTED roc,1000464,COMMENTED
Next we have the relationship from Story to Topics ( has_topic_rels.csv ) which has a “relevance” value we received from the entity extraction api that we’ll set to a type “double”:
:START_ID(Story),relevance:double,:END_ID(Topic),:TYPE 1028795,0.957543,"Intel",HAS_TOPIC 1028795,0.808232,"Intel compiler",HAS_TOPIC 1028795,0.734618,"AMD",HAS_TOPIC 1028795,0.725548,"Intel processors",HAS_TOPIC
With those files in place we can run our import which will create a graph.db folder:
neo4j2.2/bin/neo4j-import --into graph.db --nodes story_nodes.csv --nodes user_nodes.csv --nodes topic_nodes.csv --relationships author_rels.csv --relationships comment_rels.csv --relationships has_topic_rels.csv
Here we can go get a cup of coffee while we wait…
Nodes [*>:52.59 MB/s----------------------------|PROPERTIE|NODE:7.63 MB------------------|v:84.98 MB/]880k Done in 1s 752ms Prepare node index [*RESOLVE:19.07 MB-----------------------------------------------------------------------------]870k Done in 1s 683ms Calculate dense nodes [*>:56.53 MB/s------------------------------------|PREPARE(4)==============================|CAL] 1M Done in 1s 696ms Relationships [>:56.53 MB/s---------|*PREPARE(2)=====================================|RELATIONS|v:67.37 MB/s-] 1M Done in 1s 989ms Node --> Relationship [*>:??------------------------------------------|LINK------------------------------------------]880k Done in 134ms Relationship --> Relationship [*LINK-----------------------------------------------------------------------------------------] 1M Done in 265ms Node counts [*COUNT:76.29 MB-------------------------------------------------------------------------------]880k Done in 136ms Relationship counts [*>:??------------------------------------------|COUNT-----------------------------------------] 1M Done in 239ms IMPORT DONE in 8s 908ms
Slow down there tiger, I didn’t even get a chance to get off the couch and the import is already done. Did I fail to mention the new Import Tool is super fast?
Now we’ll put that graph.db folder in the neo4j/data directory and start it up. Let’s try a query. Find the Top 20 Relevant Topics of Stories that Paul Graham has authored or commented on (that aren’t too generic to be meaningful):
MATCH (u:User {username:"pg"})-[r:AUTHORED|COMMENTED]->(s:Story)-[ht:HAS_TOPIC]->(t:Topic)
WHERE ht.relevance > 0.50 AND NOT(t.name IN ["people","time","way", "things", "company", "work", "companies", "long time"])
RETURN t, count(*)
ORDER BY count(*) DESC
LIMIT 20
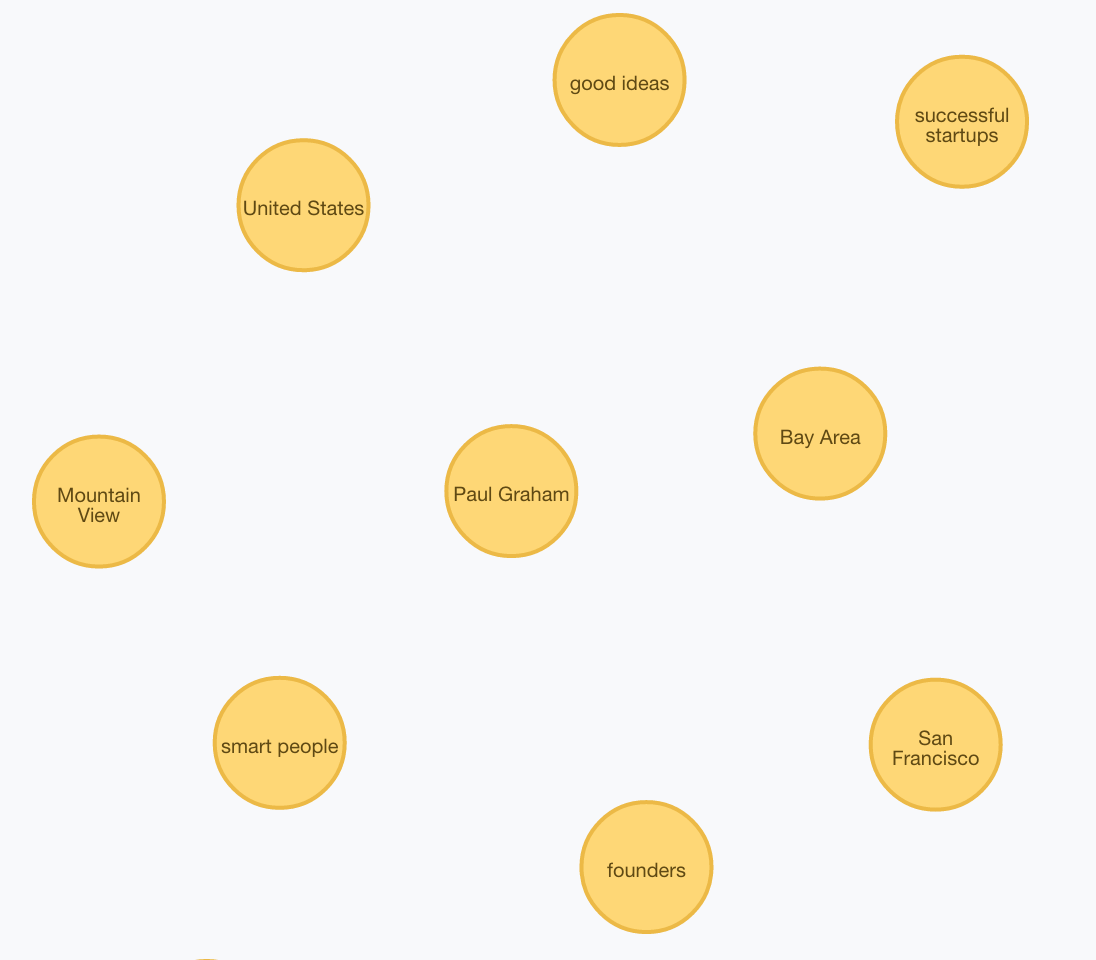
That looks about right. Now we can find topics of interest amongst two people. Authors of stories that are relevant to Topics you care about (this is how you might begin a Social Graph). People who are interested in similar topics… they may not agree with what you have to say, but that’s part of the fun. The data (50MB in Neo4j 2.2 format) is available on my public drop box account, so you can play with it to your hearts content. See this old blog post for some ideas (beware however that Cypher syntax has changed a bit since those days).
Remember that it’s just a sample, so if you want to do this for real you’ll have to shell out a few bucks to Alchemy API or build your own Entity Extraction solution. Also, I didn’t do the best job in the world cleaning this data, but that’s what data scientists are for. J/K


[…] Importing the Hacker News Interest Graph by Max De Marzi. […]
[…] Importing the Hacker News Interest Graph by Max De Marzi […]