
Just the other day I had a conversation with an Investment Risk Manager about one of the data problems his team was working on and he was wondering if Neo4j could help. Imagine you have about 20,000 mutual funds and etfs and you want to track how they measure up against a benchmark like say the returns of the S&P 500. I’m sorry did I say one? I meant all of them, let’s say 2,000 different benchmarks… and you want to track it every day, for a rolling 5 years period. So that’s 20,000 securities * 2000 benchmarks * 5 years * 252 trading days a year (on average)… or 50 billion data points. That’s a BIG join table if we were using a relational database. How can we efficiently model this in Neo4j?
To keep things simple, let’s say we only want to track one measure, and that measure is “R-Squared“. When we compare the change in value of the mutual fund vs the benchmark, how closely did the changes track? R-Squared is always between 0 and 1. A value of zero means the benchmark has nothing to do with the mutual fund, and a value of one means it has everything to do with it. So how could we model this?

Our first option is to model the Fund as a Node, the Benchmark as a Node, and the data point between them as a relationship with both a date and a r_squared property as shown above. We would have 20,000 thousand Fund Nodes, 2,000 Benchmark nodes and 50 Billion relationships… that’s an extremely dense graph.
It’s a start, but let’s try a query and see how our model does. I want to know what the r_squared was on October 31st, 2017 (Halloween) for Fund X and Benchmark Y.
MATCH (f:Fund {name: $fund_name})-[r:HAS_DATA]->(b:Benchmark {name: $benchmark_name})
WHERE r.date = $date
RETURN r.r_squared
I would create an index on :Fund(name) so I can start there quickly, and then this is where this model fails us performance wise. I would have to look at potentially 2,000 relationships (one for each benchmark) x 5 years x 252 days (2.5 Million) relationships in order to find the one I want.
Let’s try a different approach that you know I am a big fan of… using dated relationship types:

Now in order to find the r_squared between a fund and a benchmark I can write my query this way:
MATCH (f:Fund {name: $fund_name})-[r:ON_2017_10_31]->(b:Benchmark {name: $benchmark_name})
RETURN r.r_squared
Now instead of checking up to 2.5 Million relationships for the right one, I only have to check 2,000. One for each benchmark that exists… that’s much faster. Another benefit is that if I want all of the benchmarks for that one fund on a single day, this is easy to get:
MATCH (f:Fund {name: $fund_name})-[r:ON_2017_10_31]->(b:Benchmark)
RETURN b.name, r.r_squared
But let’s try another query. Let’s say we want to see how the r_squared of a fund against a benchmark has changed since the beginning of this year.
MATCH (f:Fund {name: $fund_name})-[r]->(b:Benchmark {name: $benchmark_name})
WHERE TYPE(r) STARTS WITH "ON_2017"
RETURN TYPE(r) AS day, r.r_squared
We would once again start by finding our Fund node in an Index, and then we would have to traverse 2.5 Million relationships again to find the ones we want. Now traversing 2-4 Million relationships is not the end of the world. Neo4j can do that in about a second per core, but we can do better. Let’s try moving the Benchmark name into the relationship instead.

With this model, we would start at our Fund node, traverse 5 years x 252 days (or 1,260) relationships and check the date property to answer our last query.
MATCH (f:Fund {name: $fund_name})-[r:FOR_BENCHMARK_X]->(b:Benchmark {name: $benchmark_name})
WHERE r.date > $date
RETURN r.date, r.r_squared
Ok… what about the previous query of getting all the r_squared values for all the benchmarks for a particular day.
MATCH (f:Fund {name: $fund_name})-[r]->(b:Benchmark)
WHERE r.date = $date
RETURN b.name, r.r_squared
We have a bit of a problem here. Since now we’re looking at 5 years * 252 days * 2,000 benchmarks or 2.5M relationships again. We can’t use both the date and the benchmark name as a relationship type. Neo4j can only handle about 32k relationship types, not the 2.5 Million we need. So what can we do?
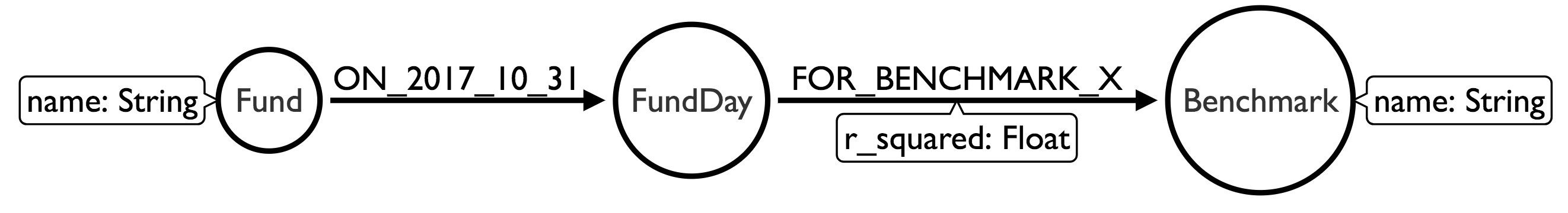
That’s right. We can create a new type of node, a FundDay. One per fund per day, so 20,000 funds * 5 years * 252 days is about 25M nodes. We then connect these to our Funds and to the Benchmarks. Our query to get all the r_squared values for all of the benchmarks for a particular day now looks like this:
MATCH (f:Fund {name: $fund_name})-[:ON_2017_10_31]->()-[r]->(b:Benchmark)
RETURN b.name, r.r_squared
We start from the Fund node, traverse to the FundDay which we will ignore, and then to all the Benchmarks for that FundDay. So our query will traverse 1 relationship for the day plus 2,000 for the benchmarks. Traversing 2,001 relationships is much faster than traversing 2.5M of them.
There is just one tiny little problem. Our graph is now comprised of 20,000 Fund nodes, 2,000 Benchmark nodes, 25M FundDay nodes which is fine… but we still have all the relationships between the 25M FundDay nodes and the 2,000 Benchmarks. 50 Billion relationships is a lot. Can we trim this database down? We can by remembering that Neo4j can handle scalar values like Integers, Strings and Floats as well as Arrays of them. So instead of storing each r_squared separately, what if we stored them in an array.

Instead of storing a single value in our r_square property, we now store an array of 5 year x 252 day r_squared values. Halloween 2017 would be the 210th trading of 2017, plus 4 years times 252 days… The r_squared would be stored in position 1,218 in our array.
MATCH (f:Fund {name: $fund_name})-[r:FOR_BENCHMARK_X]->(b:Benchmark {name: $benchmark_name})
RETURN r.r_squared[1218]
What about all of the r_squared values for a single benchmark from the first trading day of 2017 until Halloween? 4 years x 252 = 1,008, plus one for the start of 2017 until our trading day for Halloween 2017 so our query now looks like:
MATCH (f:Fund {name: $fund_name})-[r:FOR_BENCHMARK_X]->(b:Benchmark {name: $benchmark_name})
RETURN r.r_squared[1009..1218]
We start at our Fund Node, traverse a single relationship to our Benchmark and get a slice of the r_squared property array as values. What about for many benchmarks.
MATCH (f:Fund {name: $fund_name})-[r]->(b:Benchmark)
RETURN b.name, r.r_squared[1009..1218]
The query above costs us just 2,000 relationships traversals (one per benchmark) and 2000 property lookups… and the best part is we’ve reduced the size of our database to just 20,000 Fund Nodes, 2,000 Benchmark nodes, and 40 Million relationships (one for each combination).
There is still one small problem. Neo4j stores array properties in blocks of 120 bytes by default. An overhead of 8-10 bytes, leaves 112 bytes of storage. Since each r_squared value is a float that takes 8 bytes, each block would only take 14 r_squared values at a time… forcing us to jump around from block to block a bunch and slow us down quite a bit.
But since we know ahead of time how many we want to store we can change this parameter (array_block_size) to a value above 10080 (5 years x 252 days x 8 bytes). Neo4j will use that value plus an 8-10 bytes of overhead. Each page is 8192 bytes, so we can reserve a page and a half (12878) or just two pages for each entry (16374) leaving 10 bytes for the overhead. Our database will be about 700 GB in size so we need to grab an x1.16xlarge or an x1e.8xlarge with a monthly reserved 3 year paid up front cost of about $1,365 a month. Another option is that we could buy a big RAM server for about $20,000 and host it ourselves.
Remember there is no “3rd normal form” for modeling data in a graph database. It’s a wild frontier. Use the data you have and the questions you are trying to answer as a guide, but be sure to let your imagination and creativity help you along the way.

The long story short: a lot of data is a lot of problems everywhere, both in relational and in graph db’s. Your final solution is equally applicable to relational db, no need to switch to graph for your client.