
Alchemy is a philosophical and protoscientific tradition practiced throughout Europe, Africa and Asia. Its aim is to purify, mature, and perfect certain objects. In popular culture we often see the case of shadowy figures trying to turn lead into gold to make themselves immensely rich or to ruin the world economy. In our case we will not be transmuting lead into gold, but documents into graphs which is just as good. In the past, we had used “Alchemy API” but they were purchased by IBM and retired. You can get similar functionality with IBM Watson, but let’s do something else instead. Let’s add Entity Extraction right into Neo4j.
The concept is to take a document, be it a text file, word file, pdf, power point, excel, etc and have Tika detect and extract metadata and text, then run that text through a set of NLP models from OpenNLP to find interesting Entities. Lets go ahead and build a stored procedure.
If I think I may have too much in the stored procedure itself, sometimes I just make a callable and stream the results. That’s all we are doing here. There is one big spoiler in here already in that we are going to ingest documents in more than just English.
@Procedure(name = "com.maxdemarzi.en.ingest", mode = Mode.WRITE)
@Description("CALL com.maxdemarzi.en.ingest")
public Stream<GraphResult> IngestEnglishDocument(@Name("file") String file) throws Exception {
IngestDocumentCallable callable = new IngestDocumentCallable(file, "English", db, log);
return Stream.of(callable.call());
}
Our procedure is going to return a GraphResultt so we will need a place to hold our nodes and relationships as we find or create them:
@Override
public GraphResult call() {
List<Node> nodes = new ArrayList<>();
List<Relationship> relationships = new ArrayList<>();
We don’t know what the filetype of the document is going to be so we will use an AutoDetectParser to deal with it per these instructions.
BodyContentHandler handler = new BodyContentHandler();
AutoDetectParser parser = new AutoDetectParser();
Metadata metadata = new Metadata();
Next we will parse and capture the text of the document:
String text = "";
try (InputStream stream = new FileInputStream(new File(file))) {
parser.parse(stream, handler, metadata);
text = handler.toString();
} catch (Exception e) {
log.error(e.getMessage());
}
With our text in hand, we can use an OpenNLPNERecogniser to find interesting entities and store them in a map. I’m choosing between two languages here but of course you could add more.
Map<String, Set<String>> recognized;
switch (language) {
case "English":
recognized = ENGLISH_NER.recognise(text);
break;
case "Spanish":
recognized = SPANISH_NER.recognise(text);
break;
default:
recognized = new HashMap<>();
}
So wait, what are ENGLISH_NER and SPANISH_NER anyway? They are OpenNLPNERecogniser objects that take a map as input which directs them to the locations of the language files of the pre-trained models. You can find more pre-trained language models on the web or you can train your own.
private static final Map<String, String> ENGLISH = new HashMap<String, String>() {{
put(PERSON, "models/en-ner-person.bin");
put(LOCATION, "models/en-ner-location.bin");
put(ORGANIZATION, "models/en-ner-organization.bin");
put(TIME, "models/en-ner-time.bin");
put(DATE, "models/en-ner-date.bin");
put(PERCENT,"models/en-ner-percentage.bin");
put(MONEY,"models/en-ner-money.bin");
}};
static final OpenNLPNERecogniser ENGLISH_NER = new OpenNLPNERecogniser(ENGLISH);
With that out of the way, let’s get back to our procedure, we first go ahead and create a new document node with our text, file name and language. Then we add it to our list of nodes to return in our result set.
try(Transaction tx = db.beginTx() ) {
Node document = db.createNode(Labels.Document);
document.setProperty("text", text);
document.setProperty("file", file);
document.setProperty("language", language);
nodes.add(document);
Then for every type of entity our language model recognized, we check to see if the entity already exists, or create it and then add a relationship from the document to this entity. We add our entity and relationships to our result sets as we get them and finally we call success to make sure our transaction gets committed.
for (Map.Entry<String, Set<String>> entry : recognized.entrySet()) {
Label label = Schema.LABELS.get(entry.getKey());
for (String value : entry.getValue()) {
Node entity = db.findNode(label, "id", value);
if (entity == null) {
entity = db.createNode(label);
entity.setProperty("id", value);
}
nodes.add(entity);
Relationship has = document.createRelationshipTo(entity, RelationshipTypes.HAS);
relationships.add(has);
}
}
tx.success();
Let’s compile our procedure, add it to the plugins folder of Neo4j, restar neo4j and try a few documents. But first let’s go ahead and create some indexes for the “id” property for each of our types of entities:
CALL com.maxdemarzi.schema.generate;
Now we can try one by calling:
CALL com.maxdemarzi.en.ingest('data/en_sample.txt');
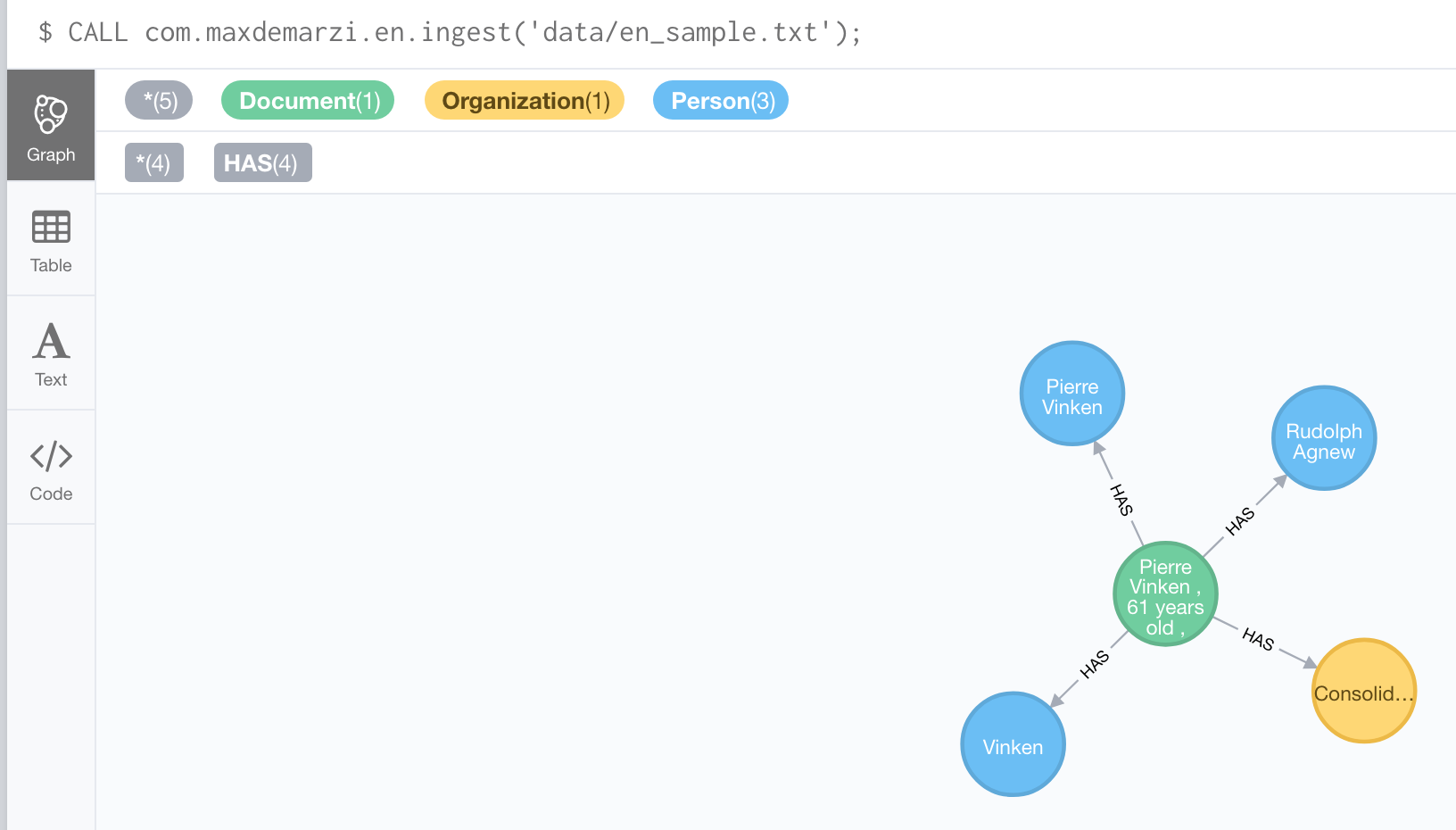
Cool, it works! How about a PDF file instead of a text file:
CALL com.maxdemarzi.en.ingest('data/en_sample.pdf');
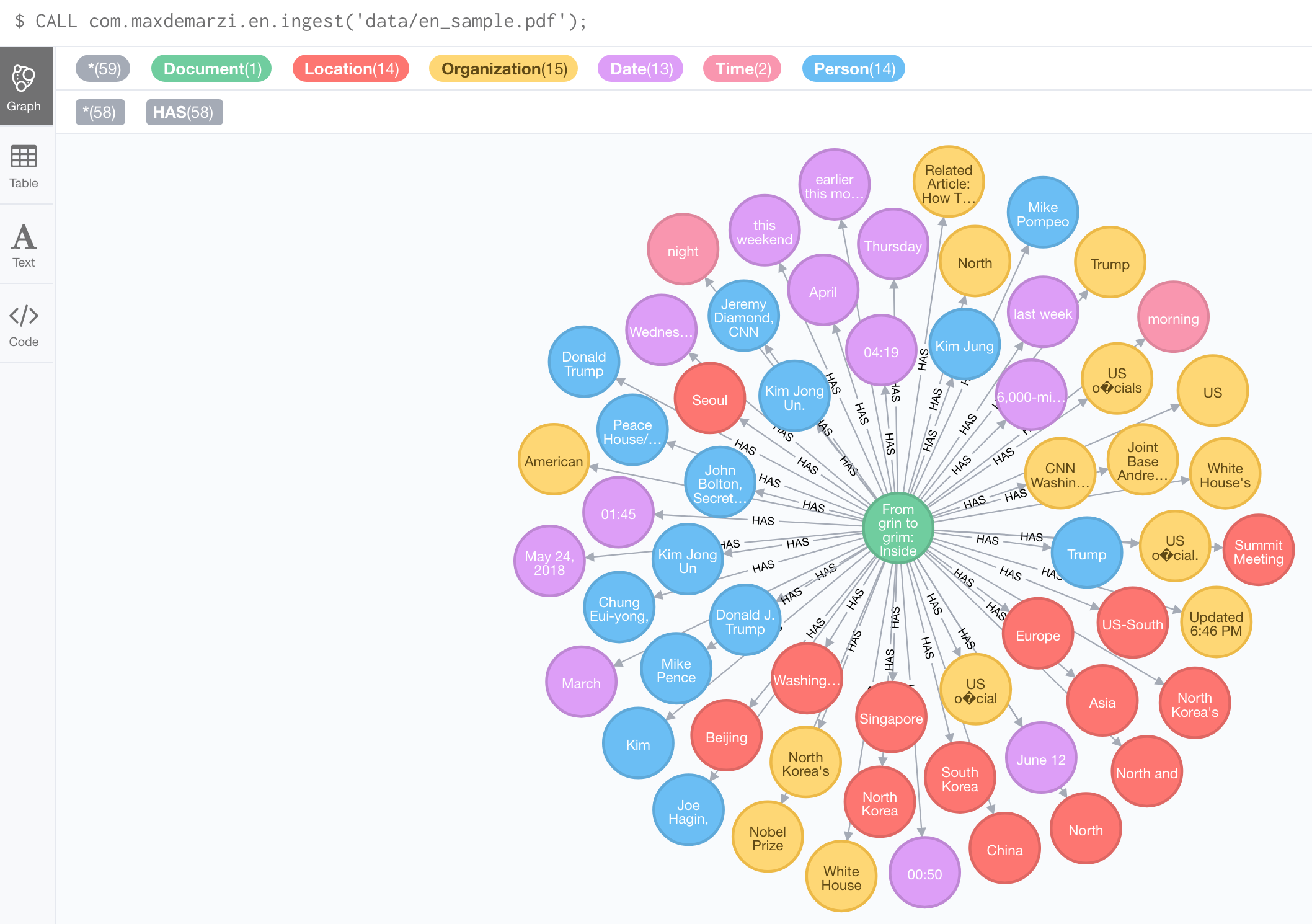
Nice. How about a Spanish PDF:
CALL com.maxdemarzi.es.ingest('data/es_sample.pdf');
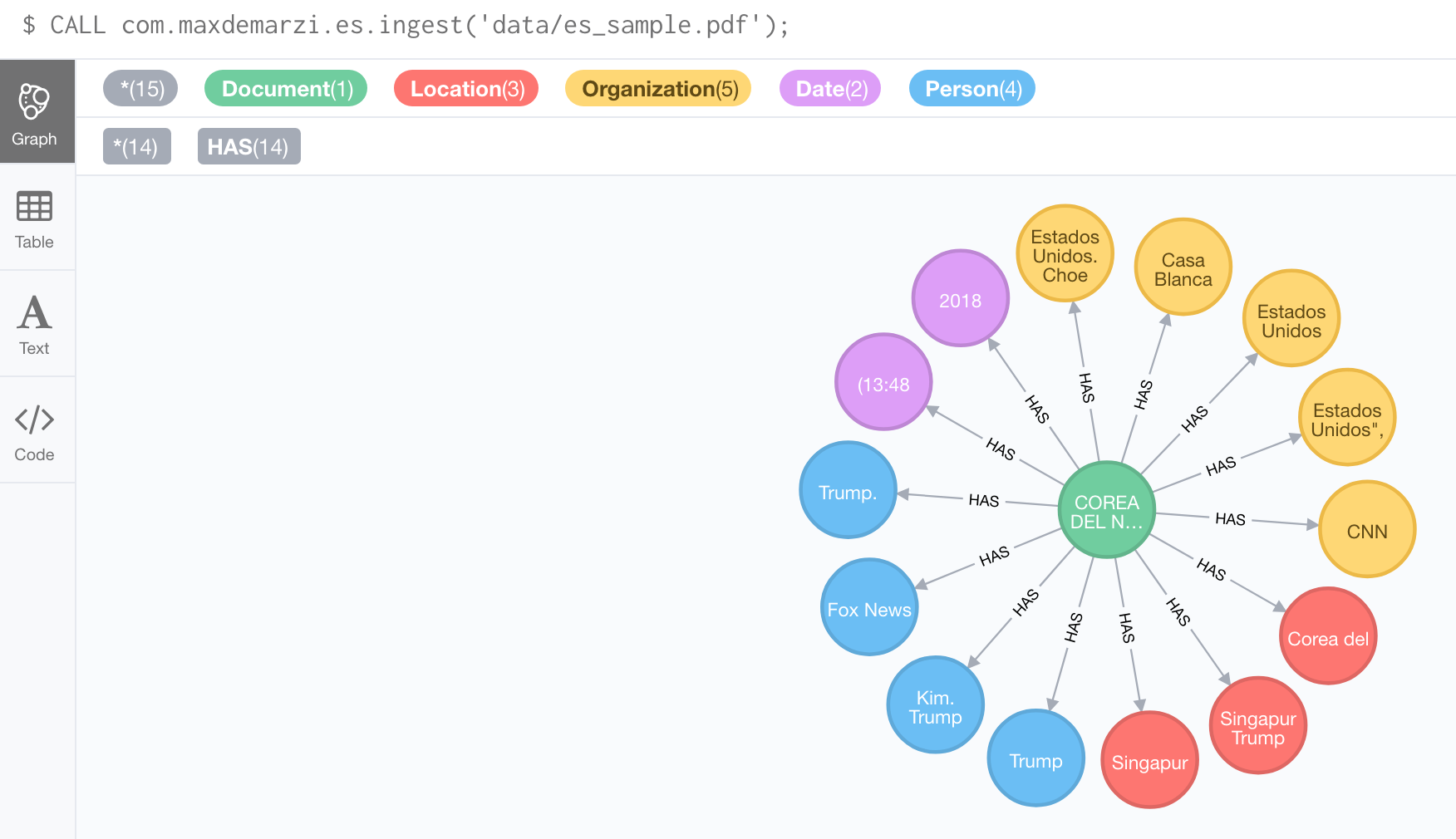
Sweet! It looks like we could use a little disambiguation and some clean up, but this is enough to get us started. The source code as always is on github. Be sure to take a look at the Tika documentation to learn more about what it can do.
Finally if you want to see a plugin with more NLP functionality check out the work our partners at GraphAware have done with their Neo4j NLP plugin.
