
The Stereo MC’s song “Connected” could be about some recently gained insight and the realization that maybe some of the people you held dear are phonies and while the reality of the situation is scary, you cannot allow yourself to turn a blind eye anymore or allow yourself to backslide by disconnecting from the real world.
Or it could be a warning about how we’ve all been blinded by SQL databases for too long and we must instead look to connect our data with Graph Databases. About how those new connections may be scary (like because of fraud detection) but they are necessary to better understand reality.
Either way, we may want to see if two nodes in Neo4j are connected and I’m going to show you how to do that faster.
I was randomly reading some papers and ran into the K^2 Tree. The idea is to take a graph and represent it compactly as a tree. We start by looking at the adjacency matrix of the graph and cutting it up into smaller and smaller pieces for every level we go down until we can’t split it anymore. Then we take the matrix one level at a time and build a tree putting a 1 if a relationship exists in our piece, or a 0 if it doesn’t.
Take a look at the following image for how it works:
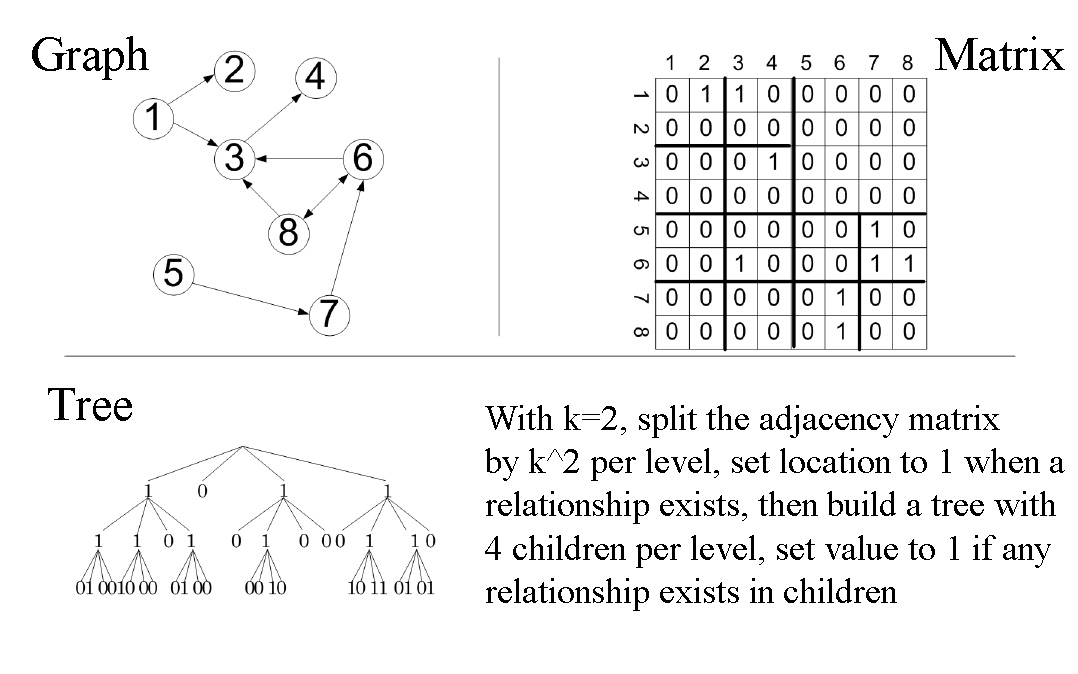
It sure looks a lot like an R-Tree or a Quad-Tree, but what makes it an K^2 Tree is the final representation of the data. The Tree is split and converted into 2 bitmaps. The leaves go into one bitmap and the rest of the tree goes into the other. The paper linked above does a good job of explaining how that works so I’ll leave you to read it if you are really interested.
In our case we are not going to build a real K^2 Tree. It’s construction requires a static graph, and we are all about dynamic data here at Neo4j. There is a Dynamic K^2 Tree data structure in another paper by the same authors, take a look at that if you are interested. We’re not building that either (looks complicated). Instead we’re going to build a simple variant without the compact representation that will save the Neo4j node ids of the relationships we create.
We’ll start off by building a Tree that has a given height and creates 4 children when we call its constructor.
public class K2Tree {
private K2Tree[] _tree;
private byte _height;
public int[] Values;
public K2Tree(byte height) {
_height = height;
_tree = new K2Tree[4];
}
Next we will need a utility function called getBit that will figure out which region a node id belongs in based on the height of the tree.
private int getBit(int val) {
return (val / (int)Math.pow(2, _height - 1)) % 2;
}
We will use getBit in our set method below. Let’s do this upside down. If we get to the bottom of the tree, we want to save our “from” (our x in the matrix) and “to” (our y in the matrix) node ids and return. If we are not at the bottom of the tree then find out in which part of the tree this relationship belongs (based on the x and y coordinates). Once we know where we belong, create a new tree with a lower height in that part (if it doesn’t already exist) and set the x and y coordinates of that tree. See the code below:
public void set(int x, int y) {
if (_height == 0) {
Values = new int[2];
Values[0] = x;
Values[1] = y;
return;
}
int bit0 = getBit(x);
int bit1 = getBit(y);
int path = 2 * bit0 + bit1;
if (_tree[path] == null) {
_tree[path] = new K2Tree((byte)(_height - 1));
}
_tree[path].set(x, y);
}
Yes, this is going to create a crazy 16 level nested structure of 4 children trees until it gets to the end and then store 2 values in an array. I told you this wasn’t a compact representation earlier… now you believe me. Anyway on to the get method.
Now this is where this K^2 Tree is interesting. When you try to see if a relationship exists between two nodes it checks the top tree first which only has children where a relationship exists. Looking back at the example image above. If we wanted to see if there was a relationship between Node 2 and Node 8, we would go to the top right region and since none of those node combinations have a relationship, our tree doesn’t have a child in that part. It returns false immediately. If we wanted to check a relationship between 1 and 2 (which does exist) it would continue checking down each level until it made sure the values at the last level were not equal to null.
public boolean get(int x, int y) {
if (_height == 0) {
return (Values != null);
}
int bit0 = getBit(x);
int bit1 = getBit(y);
int path = 2 * bit0 + bit1;
if (_tree[path] == null) {
return false;
}
return _tree[path].get(x, y);
}
That’s pretty much all there is to it. Now how do we hook this index into Neo4j? We use a Kernel Extension along with a Transaction Event Handler (aka Trigger). We will have an ArrayList of K2Trees, one for each relationship type and when a new transaction occurs we will check the “createdRelationships” list in the “afterCommit” hook and add those node ids to our tree:
public void afterCommit(TransactionData td, Object o) {
try (Transaction tx = db.beginTx()) {
for (Relationship relationship : td.createdRelationships()) {
K2Trees.set(
relationship.getType().name(),
relationship.getStartNode().getId(),
relationship.getEndNode().getId()
);
Now let’s build a performance test to see if this is any faster than using regular Neo4j code. In Neo4j if we want to check if there is a relationship between two nodes, we first find the nodes, and traverse the relationships (of one of them, hopefully the one with the least amount of relationships) and check to see if we find the second node in our results like so:
public boolean measureSingleLikeNeo4j() throws IOException {
try (Transaction tx = db.beginTx()) {
Node userNode = db.getNodeById(rand.nextInt(userCount));
Node itemNode = db.getNodeById(userCount + rand.nextInt(itemCount));
for (Relationship rel : userNode.getRelationships(Direction.OUTGOING, LIKES)) {
if (rel.getEndNode().equals(itemNode)) {
return true;
}
}
tx.success();
}
return false;
}
In our K2Tree we can do this:
public boolean measureSingleLikeK2() throws IOException {
return K2Trees.get("LIKES", rand.nextInt(userCount), userCount + rand.nextInt(itemCount));
}
So how does it perform? I built a quick JMH test and these are my results:
Benchmark Mode Cnt Score Error Units K2TreeBenchmark.measureSingleLikeNeo4j thrpt 5 149851.911 ± 22897.963 ops/s K2TreeBenchmark.measureSingleLikeK2 thrpt 5 623405.996 ± 11841.250 ops/s K2TreeBenchmark.measureSingleLikeK4 thrpt 5 1278714.147 ± 28553.838 ops/s
So our K2 Relationship index is 4 times faster (600k vs 150k ops/s) than using Neo4j directly… but what’s this K4 thing?
Ah… well I told you it was called a K^2 Tree, but the k can be 2, 4, or higher. I also created a K^2 Tree with k=4 and it is about 8.5 times faster (1.25M vs 150k ops/s) than using Neo4j directly. This is of course on a small dataset with a pretty naive implementation of a K^2 tree.
I think we could do much better if we were serious about this. If you are interested, take a look at the source code on github as always.
SQL ain’t right
Gonna get myself, I’m gonna get myself
Gonna get myself connected
I ain’t gonna join tables
For the index which is neglected
I Cypher you, I Cypher you
I Cypher you, I Cypher you
Ya dirty joins, ya make me sick
I Cypher you, I Cypher you
Gonna query again, gonna query again
I’m (gonna query again, gonna query again)
Gotta do Graphs (gonna query again)
‘Cause somethin’ ain’t right (gonna query again)
Gotta do Graphs, come on

[…] Connected, by Max De Marzi […]