
In the movie Blade Runner, “replicants” are engineered biological copies of humans. They are implanted with memories that aren’t real (to them anyway, they are sometimes the recorded memories of other people) in order to provide a sort of replacement to their emotions. The replicants are meant to work in outer space and are illegal on earth. The ones that manage to get to earth are hunted down by Deckard and other blade runners. In order to determine who is a replicant and who is a “real person” blade runners use a “Voight-Kampff” test that measures respiration, heart rate, blushing and eye movement in response to emotionally provocative questions. Today we are going to turn Neo4j into a blade runner and use it to find and retire replicated identities in our data.
I have one word for you: Toaster. Yes, Toaster. Have you ever seen an advertisement from a bank to become a new customer and receive a free toaster? No? Ok, stop what you are doing and watch this video. Back? Great. So, most banks that offered a free toaster had a few conditions. One of them was that you had to be a new customer and that no one else in your household was already a customer. This was so you couldn’t get your husband or wife or kid to open an account and get a new toaster.

At least you weren’t supposed to, but that doesn’t mean some people didn’t still try. Let’s take a look at how this problem may be modeled in a graph and how we may go about solving it. An account gets opened, and it may be attached to a phone number, an email address, a physical address and so on. The banks have rules about knowing your customers so they may pull in a credit check which would have additional information about the person like their previous addresses for example.

A toaster scammer would want to use their spouse to setup the account, so they have different names, emails, phone numbers, but what about their current addresses? Well, they may share an address so they could change the address a little bit by putting “Unit 2” or spelling the street name incorrectly or what have you. So we have to take into account small “fuzzy” variations.
One option when dealing with addresses is to find their latitude and longitude and use that to find nearby addresses. This is going to be much easier to do in Neo4j 3.4 than it currently is in 3.3 (you’ll see why at the bottom of this post) but Neo4j 3.4 has not been released (as of today, future readers should check). Instead we will translate those latitudes and longitudes into a geohash. A GeoHash turns a geographic location into a short string of letters and digits which then makes searching for it and its neighbors easy.
Let’s imagine a very simple graph with just a single account tied, to one email, one phone and one address:
CREATE (a1:Account { id: 'a1' })
CREATE (e1:Email { address: 'max@neo4j.com' })
CREATE (p1:Phone { number: '3125137509' })
CREATE (add1:Address { line1:'175 North Harbor Dr.', city:'Chicago', state:'IL', zip:'60605',
lat: 41.886069, lon:-87.61567, geohash:'dp3wq'})
CREATE (a1)-[:HAS_EMAIL]->(e1)
CREATE (a1)-[:HAS_PHONE]->(p1)
CREATE (a1)-[:HAS_ADDRESS { billing:true, shipping:true, current:true }]->(add1)
If a person tries to get a toaster by opening an account with the same email address, same phone number, or very similar address we want to be able to catch them and let the account manager know not to give them the free toaster. So let’s create a stored procedure that takes the new customer’s data as input, and for output we will display the similar account and why they are similar.
@Procedure(name = "com.maxdemarzi.replicant", mode = Mode.READ)
@Description("CALL com.maxdemarzi.replicant(facts)")
public Stream<NodeListResult> findReplicant(@Name("facts") Map<String, Object> facts) throws IOException, UnirestException {
Map<Node, List<Node>> results = new HashMap<>();
Our first step is to check for an equal e-mail address. We first look for a node with the same email, and if it exists, we add it and the account it belongs to in to our result set.
Node email = db.findNode(Labels.Email, "address", facts.get("email"));
if (email != null) {
email.getRelationships(Direction.INCOMING, RelationshipTypes.HAS_EMAIL)
.forEach(relationship -> {
results.put(relationship.getStartNode(), new ArrayList<Node>(){{ add( email); }});
});
}
The code for phone number looks nearly identical, so we’ll skip it for now. However, for addresses, we need to get the geohash, and for the geohash we need to get the latitude and longitude. We are going to use a geo location service from the “data science toolkit” that uses open street map under the covers. What I like about DSTK is that you can host the whole thing yourself as a self contained VM which means you don’t have to pay for or rely on an external service for this geocoding. In order to do that, we need to prepare our street addresses by encoding them.
ArrayList<String> encodedAddresses = new ArrayList<>();
ArrayList<String> addresses = (ArrayList<String>) facts.get("addresses");
addresses.forEach(address -> {
try {
encodedAddresses.add(URLEncoder.encode(address, StandardCharsets.UTF_8.toString()));
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
log.error(e.getMessage());
}
});
Then we use the service to get the latitude and longitude of the address. In a production application you would change the url to be your own hosted version of DSTK.
HashMap<String, Node> possibleAddresses = new HashMap<>();
for (String encodedAddress : encodedAddresses ) {
HttpResponse<JsonNode> postResponse = Unirest.get("http://www.datasciencetoolkit.org/street2coordinates/" + encodedAddress)
.asJson();
String key = postResponse.getBody().getObject().keySet().iterator().next();
JSONObject data = (JSONObject)postResponse.getBody().getObject().get(key);
Double latitude = data.getDouble("latitude");
Double longitude = data.getDouble("longitude");
With the latitude and longitude in hand, we can use a GeoHash library to convert them. I’m choosing to use a precision of 5 which means all addresses within 2.5 kilometers will have the same geocoding. We could go with a higher precision, but I’m interested in catching typos and slightly different addresses, so I want to leave it pretty loose.
GeoHash hash = GeoHash.withCharacterPrecision(latitude, longitude, 5);
// Get the addresses at this geohash location
Iterator<Node> iter = db.findNodes(Labels.Address, "geohash", hash.toBase32());
while (iter.hasNext()) {
Node node = iter.next();
possibleAddresses.put( getAddress(node), node);
}
…and for good measure I am also going to check the bounding areas around our geohash just in case. If you have lots of customers in the same area, it may make sense to increase that precision.
// Check the neighboring location just in case
GeoHash[] adjacent = hash.getAdjacent();
for (GeoHash adjacentHash : adjacent) {
Iterator<Node> iterAdj = db.findNodes(Labels.Address, "geohash", adjacentHash.toBase32());
while (iterAdj.hasNext()) {
Node node = iterAdj.next();
possibleAddresses.put( getAddress(node), node);
}
}
So now I have a bunch of potential addresses in the same vicinity that may be the one our fraudster is trying to fake. To narrow our search down, we will compare the addresses using DamerauLevenshtein which is measuring the edit distance between two strings and assigning a score. People write addresses with “St”, “St.”, “Street” and my different variations, in order to compare them properly we want to convert them all to use the same style. We could use the USPS address verification tool and compare them that way. In our case we’ll keep it simple and use an address simplifier to clean them up as we have done before.
I decided if any address is over 90% similar, then we should verify to see if it’s the same address.
for (String address : addresses) {
String simplifiedAddress = addressSimplifier.simplify(address);
for (Map.Entry<String, Node> entry : possibleAddresses.entrySet()) {
Float score = metric.compare(simplifiedAddress, addressSimplifier.simplify(entry.getKey()));
if (score > 0.90) {
// add to results
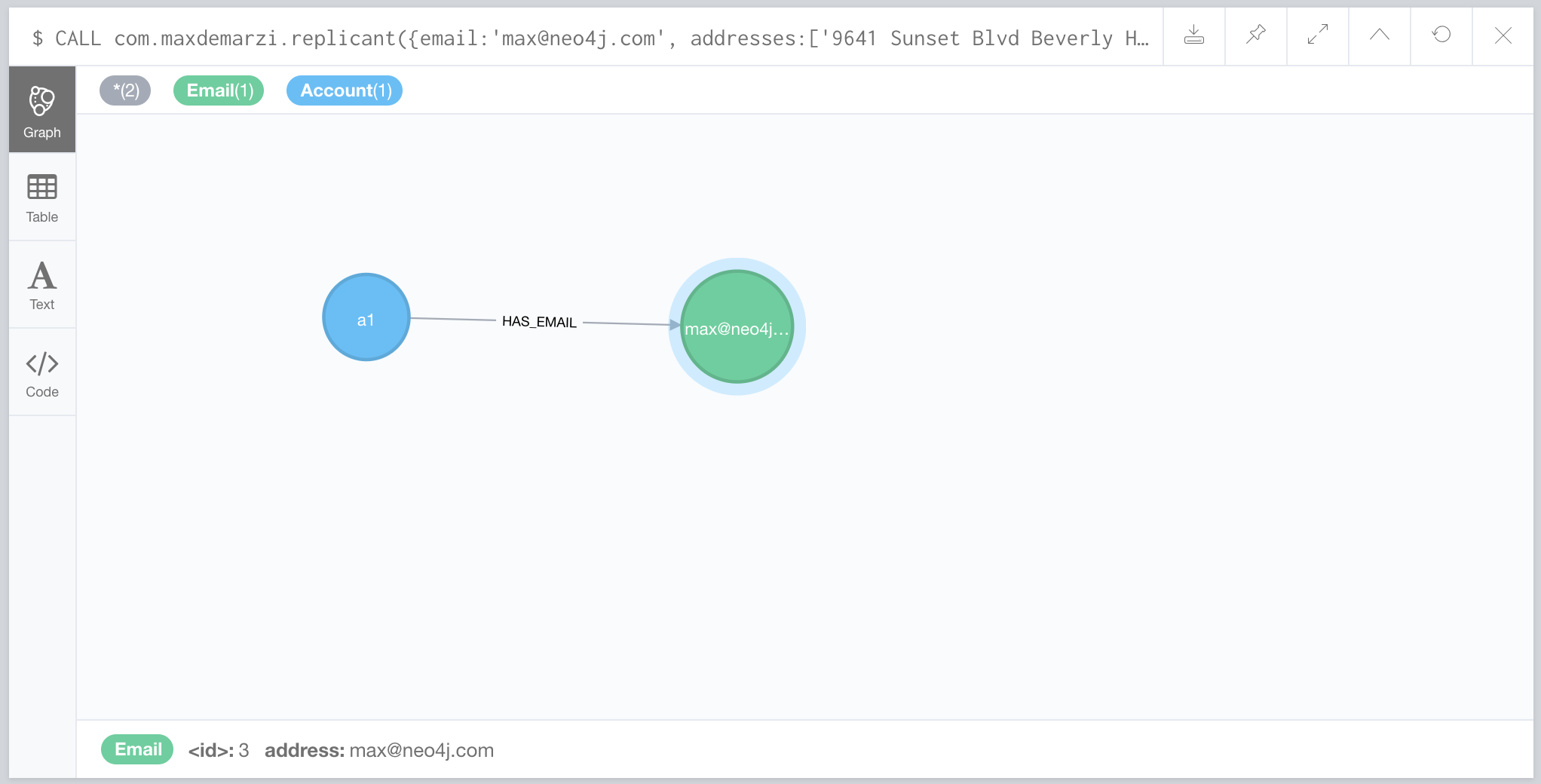
Let’s try calling our stored procedure with the same email address;
CALL com.maxdemarzi.replicant({email:'max@neo4j.com',
addresses:['9641 Sunset Blvd Beverly Hills CA 90210'], phone:'3102762251'})
YIELD nodes
RETURN nodes
How about the same email and a typo of our physical address:
CALL com.maxdemarzi.replicant({email:'max@neo4j.com',
addresses:['175 Norht Hrabro Dr. Chicago IL 60605'], phone:'1235550000'})
YIELD nodes
RETURN nodes

There we have it. You know what other use case this would be good for? Customers who sign up for utilities, don’t pay, and then sign up their family members when they get cut off. If you don’t have electricity, having a new toaster isn’t going to be of much use. As always, the source code is available on github. Give it a shot and leave a comment below if you think of other good use cases.
Oh, and before I go, in Neo4j 3.4 we are adding new Spatial capabilities directly into the product. One of them is index backed spatial distance queries, so if you wanted to look for addresses within 10 km of a certain lat/long you could skip the geohash and do this instead:
CREATE INDEX ON :Address(location);
CREATE (a:Address)
SET a.location = point({latitude: 41.886069, longitude: -87.61567, crs: 'WGS-84'})");
MATCH (a:Address)
WHERE distance(a.location, point({latitude: 41.88, longitude: -87.61, crs: 'WGS-84'})) <= 10
RETURN a
If you want to try it out, grab the Neo4j 3.4 alpha09 (or later) release which will be at the top of this page on March 1st and look here for more examples.
My girlfriend asked why I carry a gun around the house? I looked her dead in the eye and said, “the Decepticons”. She laughed, I laughed, the toaster laughed, I shot the toaster, it was a good time.
