
A few folks have come to us recently with the need to trace lineages of nodes of variable depth many hops away. You can run into this need if you are looking at the ancestries of living things, tracing data as it flows through an ETL, large network connectivity maps, etc. These types of queries tend to be murder on relational databases because of the massive recursive joins they have to deal with. Let’s give them a try in Neo4j.
So you don’t have to wonder which came first, the data or the query, I’ll make some data. Let’s start with yours truly:
CREATE (u:Person {name:"1-Max"})
Then let’s add an index so I can don’t lose myself:
CREATE INDEX ON :Person(name);
…and let’s start building a family tree. We’ll enact a 2-child policy and force everyone to have exactly two children. We can do this in Cypher with the following rather crazy query:
WITH ["Jennifer","Michelle","Tanya","Julie","Christie","Sophie","Amanda","Khloe","Sarah","Kaylee"] AS names
MATCH (users:Person) WHERE users.name STARTS WITH "1-"
WITH range(1,2) as children, users, names
FOREACH (id in children | CREATE (users)-[:HAS_CHILD]->(:Person {name:"2-" + names[id% size(names)]+id}) );
We keep incrementing the “1-” and “2-” until we get to level 20, so our final query looks like:
WITH ["Jennifer","Michelle","Tanya","Julie","Christie","Sophie","Amanda","Khloe","Sarah","Kaylee"] AS names
MATCH (users:Person) WHERE users.name STARTS WITH "19-"
WITH range(1,2) as children, users, names
FOREACH (id in children | CREATE (users)-[:HAS_CHILD]->(:Person {name:"20-" + names[id% size(names)]+id}) );
This last query will have added 524288 labels, created 524288 nodes, set 524288 properties, created 524288 relationships, and executed in 26551 ms on my laptop. At the end of all these queries, we will have 1,048,575 Person nodes and 1,048,574 relationships. If we take a look at our graph in the Neo4j Browser, this is what we’ll see:

Now we can build a Cypher query that can start at the root node “1-Max” and find all the children nodes in the family tree. You may end up with a lot of paths, so I’m adding a limit here just to see data in the web browser.
MATCH pt=(p:Person { name: "1-Max" })-[r:HAS_CHILD*]->(c)
WITH extract(x IN nodes(pt) | x.name) as paths, length(pt) as lengths
RETURN paths, lengths LIMIT 5000
Our results will look like:
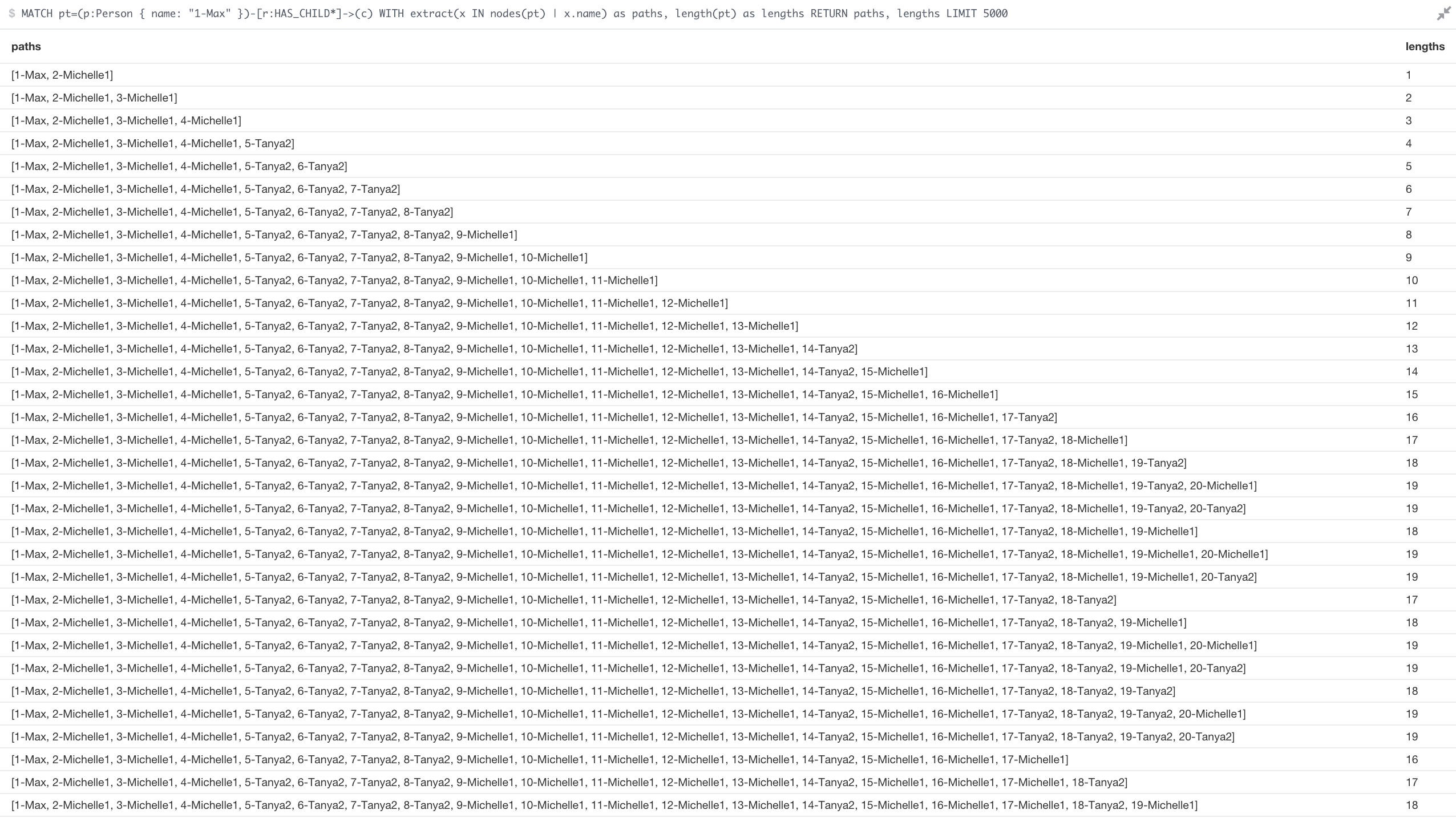
Cool right? Now let’s test the performance. Normally this is where I would start a new Gatling project, but since the query is going to be the same, I’ll be lazy and use Curl and Apache Bench. Substitute “swordfish” below for your Neo4j password and try this query:
curl -u neo4j:swordfish -H "Content-Type: application/json" -X POST -d '{ "statements" : [ { "statement" : "MATCH pt=(p:Person { name: \"1-Max\" })-[r:HAS_CHILD*]->(c) WITH extract(x IN nodes(pt) | x.name) as paths, length(pt) as lengths RETURN paths, lengths" } ]}' http://localhost:7474/db/data/transaction/commit
There is a wall of text dumped on the screen from all the paths it finds. What we really want to do is find out how long it takes to run this query. I recently learned that curl has some nice options to let us check how long queries take. Create a curl-format.txt file and make it look like this:
time_namelookup: %{time_namelookup}\n
time_connect: %{time_connect}\n
time_appconnect: %{time_appconnect}\n
time_pretransfer: %{time_pretransfer}\n
time_redirect: %{time_redirect}\n
time_starttransfer: %{time_starttransfer}\n
----------\n
time_total: %{time_total}\n
Then we’ll try our curl command again, but pass in a few options. The -w tells it to use the format file we just created, -o /dev/null hides the output (use -o NUL on Windows) and -s hides the progress bar.
curl -u neo4j:swordfish -w "@curl-format.txt" -o /dev/null -s -H "Content-Type: application/json" -X POST -d '{ "statements" : [ { "statement" : "MATCH pt=(p:Person { name: \"1-Max\" })-[r:HAS_CHILD*]->(c) WITH extract(x IN nodes(pt) | x.name) as paths, length(pt) as lengths RETURN paths, lengths" } ]}' http://localhost:7474/db/data/transaction/commit
Now we get an output that looks like:
time_namelookup: 0.005
time_connect: 0.005
time_appconnect: 0.000
time_pretransfer: 0.005
time_redirect: 0.000
time_starttransfer: 0.402
———-
time_total: 32.084
So it looks like it starts getting data right away, but it takes 32 seconds to get the dump of all the paths and that’s just too long. Let’s switch to the Traversal API and see if it can do any better. We’ll create a url endpoint that takes the person’s name as a parameter, find that node in the index, creates a traversal description that follows the HAS_CHILD relationship depth first to the end. Then for each path we find we will collect the names and length of the path and output that.
@GET
@javax.ws.rs.Path("/paths/{name}/")
@Produces({"application/json"})
public Response paths(
@PathParam("name") final String name,
@Context final GraphDatabaseService db) throws IOException {
ArrayList<HashMap> results = new ArrayList<>();
try (Transaction tx = db.beginTx()) {
final Node user = db.findNode(Labels.Person, "name", name);
if (user != null) {
TraversalDescription td = db.traversalDescription()
.depthFirst()
.expand(PathExpanders.forTypeAndDirection(RelationshipTypes.HAS_CHILD, Direction.OUTGOING))
.uniqueness(Uniqueness.RELATIONSHIP_PATH);
for (org.neo4j.graphdb.Path position : td.traverse(user)) {
HashMap<String, Object> result = new HashMap<>();
ArrayList<String> names = new ArrayList<>();
for (Node node : position.nodes()) {
names.add((String) node.getProperty("name"));
}
result.put("paths", names);
result.put("length", position.length());
results.add(result);
}
}
tx.success();
}
return Response.ok().entity(objectMapper.writeValueAsString(results)).build();
}
So if we run this query (after the database is warmed up):
curl -u neo4j:swordfish -w "@curl-format.txt" -o /dev/null -s http://localhost:7474/v1/service/paths/1-Max
What do we get?
time_namelookup: 0.004
time_connect: 0.005
time_appconnect: 0.000
time_pretransfer: 0.005
time_redirect: 0.000
time_starttransfer: 18.639
———-
time_total: 19.316
About 19 seconds. That’s better than 32 seconds, but notice we don’t start receiving any data until 18 seconds into the execution of this query. What’s going on here? Well… we’ve made the mistake of keeping all the results in an ArrayList in memory and then at the end sending the whole list once our traversal has finished. There is a better way. Let’s stream this data by creating a StreamingOutput that generates the JSON as it finds a path instead of all at once at the end:
@GET
@javax.ws.rs.Path("/paths_streaming/{name}/")
@Produces({"application/json"})
public Response pathsStreaming(
@PathParam("name") final String name,
@Context final GraphDatabaseService db) throws IOException {
StreamingOutput stream = new StreamingOutput() {
@Override
public void write(OutputStream os) throws IOException, WebApplicationException {
JsonGenerator jg = objectMapper.getJsonFactory().createJsonGenerator(os, JsonEncoding.UTF8);
try (Transaction tx = db.beginTx()) {
final Node user = db.findNode(Labels.Person, "name", name);
if (user != null) {
TraversalDescription td = db.traversalDescription()
.depthFirst()
.expand(PathExpanders.forTypeAndDirection(RelationshipTypes.HAS_CHILD, Direction.OUTGOING))
.uniqueness(Uniqueness.RELATIONSHIP_PATH);
jg.writeStartArray();
for (org.neo4j.graphdb.Path position : td.traverse(user)) {
jg.writeStartObject();
jg.writeArrayFieldStart("paths");
for (Node node : position.nodes()) {
jg.writeString((String) node.getProperty("name"));
}
jg.writeEndArray();
jg.writeNumberField("length", position.length());
jg.writeEndObject();
}
jg.writeEndArray();
}
tx.success();
}
jg.flush();
jg.close();
}
};
return Response.ok().entity(stream).type(MediaType.APPLICATION_JSON).build();
}
Let’s run it a couple of times to warm up:
curl -u neo4j:swordfish -w "@curl-format.txt" -o /dev/null -s http://localhost:7474/v1/service/paths_streaming/1-Max
What are our results:
time_namelookup: 0.005
time_connect: 0.006
time_appconnect: 0.000
time_pretransfer: 0.006
time_redirect: 0.000
time_starttransfer: 0.012
———-
time_total: 10.979
About 11 seconds. Better than the 32 we started with, but what is Neo4j doing that it is taking so long?
We’ll connect Yourkit to Neo4j, start the CPU profiler and take a peek:
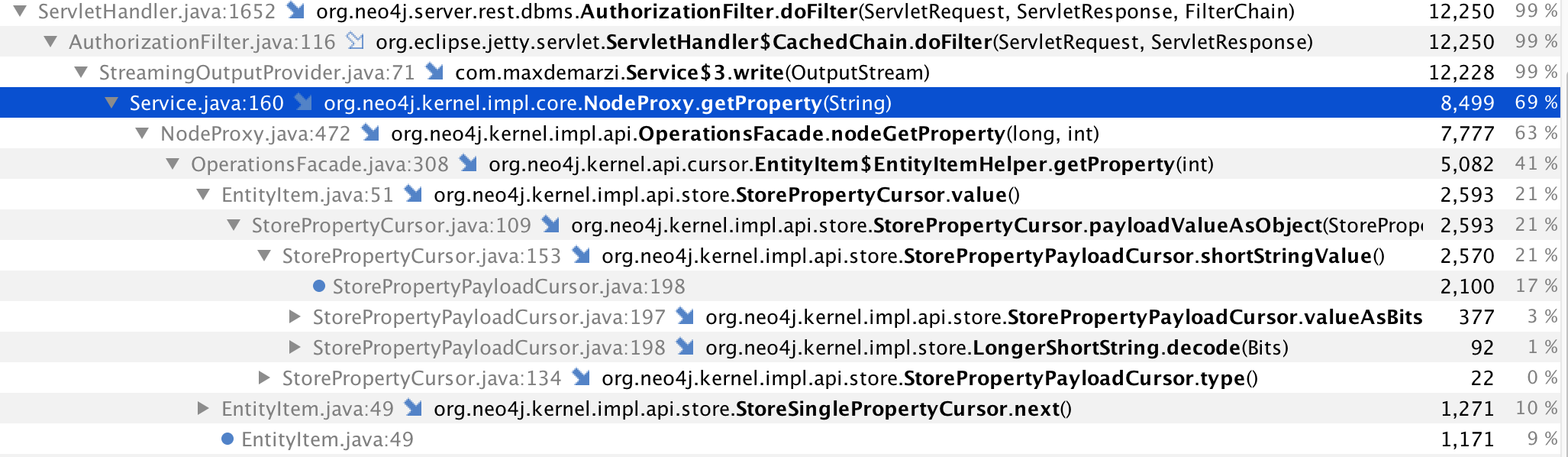
It looks like Neo4j spends the majority of time reading the name property from nodes. Well, it turns out these name properties are not going to change. They are immutable, so we can cache them and skip the work of retrieving them from the node. Let’s add a Google Guava Loading Cache and try it again.
private static final LoadingCache<Long, String> names = CacheBuilder.newBuilder()
.maximumSize(2_000_000)
.build(
new CacheLoader<Long, String>() {
public String load(Long nodeId) {
return getNameForNodeId(nodeId);
}
});
private static String getNameForNodeId(Long nodeId) {
final Node node = db.getNodeById(nodeId);
return (String) node.getProperty("name", "unknown");
}
I’ll skip the code for the endpoint, the only real difference is calling names.get(node.getId()) instead of node.getProperty(“name”). We’ll call it:
curl -u neo4j:swordfish -w "@curl-format.txt" -o /dev/null -s http://localhost:7474/v1/service/paths_streaming_cached/1-Max
…and see how well this one does:
time_namelookup: 0.006
time_connect: 0.006
time_appconnect: 0.000
time_pretransfer: 0.006
time_redirect: 0.000
time_starttransfer: 0.011
———-
time_total: 5.599
5.6 seconds is way better than the 32 seconds we started with. Let’s connect to YourKit again and see what’s going on:

It looks like we’re spending about one third of the time getting values from the cache. If only there was some way to read this value without having to go through the hashing first… like what if we had a String[] backing our names? You can look at the code here.
curl -u neo4j:swordfish -w "@curl-format.txt" -o /dev/null -s http://localhost:7474/v1/service/paths_streaming_pre_cached/1-Max
time_namelookup: 0.005
time_connect: 0.006
time_appconnect: 0.000
time_pretransfer: 0.006
time_redirect: 0.000
time_starttransfer: 0.011
———-
time_total: 2.721
Great! 2.7 seconds is now 12x faster than our 32 second starting point.
If we take a look at YourKit again, we can see more of the time spent on the traversal and less on fetching the name properties.
![]()
One thing that is kind of annoying is that each and every level of the family tree is coming back. We could create a custom evaluator to check if the last node seen had any outgoing HAS_CHILD relationship and only return those that do not… but I’d like to instead take this opportunity to do something neat.
We’re going to drop the Traversal API and instead we are going to use the Java core api recursively. Yeah, “recursion” is that technique you learned in school that you’d thought you’d never actually use. So first we’ll get our starting node, and we will call a recursive function like this:
final Node user = db.findNode(Labels.Person, "name", name);
if (user != null) {
jg.writeStartArray();
doStuffRecursively(user, 0, jg, new ArrayList<Long>());
jg.writeEndArray();
}
We are passing a depth of 0, our JsonGenerator, and an empty list of node ids as an ArrayList of Longs. Then in our method we will add our node to the nodeIds list, and for each child doStuffRecursively at a +1 depth. If we reach the end of a path, we write out the names from our nodeIds, write out the depth and remove ourselves from the nodeIds list:
private void doStuffRecursively(Node node, int depth, JsonGenerator jg, ArrayList<Long> nodeIds) throws ExecutionException, IOException {
boolean end = true;
nodeIds.add(node.getId());
for (Relationship rel : node.getRelationships(RelationshipTypes.HAS_CHILD, Direction.OUTGOING)) {
end = false;
Node nextNode = rel.getEndNode();
doStuffRecursively(nextNode, depth + 1, jg, nodeIds);
}
if (end) {
jg.writeStartObject();
jg.writeArrayFieldStart("paths");
for (Long nodeId : nodeIds) {
jg.writeString((String) names.get(nodeId));
}
jg.writeEndArray();
jg.writeNumberField("length", depth);
jg.writeEndObject();
}
nodeIds.remove(node.getId());
}
We’ll call it:
curl -u neo4j:swordfish -w "@curl-format.txt" -o /dev/null -s http://localhost:7474/v1/service/longest_paths_streaming_recursively/1-Max
…and see how well this one does:
time_namelookup: 0.005
time_connect: 0.005
time_appconnect: 0.000
time_pretransfer: 0.005
time_redirect: 0.000
time_starttransfer: 0.009
———-
time_total: 3.271
3.2 seconds using Guava to store our property names. That’s a nice 10x from where we started. If we switch to the Array version we get 1.8 seconds for our total time, which is about 17x from where we started. I think that’s pretty sweet. As always, the source code is on github.
We’re growing every day
Getting stronger in every way
I’ll take you to a place
Where we shall find our
Roots Bloody Roots

[…] are going to follow the same steps we took in a previous blog post and create a 2 child per node catalog of about 1 million […]
with this same idea, what is the best way to return all the cycles in the graph and speed up the query? and it would be nice if this code was python! THNKS by the way
We are passing around the node ids traversed per path in ArrayList nodeIds in the code, so you would just check to see if the current node is already on that list.