
When it comes to getting data into Neo4j, you have a ton of options. You can use LOAD CSV from Cypher, you can use the Import Tool, you can use the JDBC connector in APOC, and possibly a few more options I’m forgetting. Some of these require the data to be in a specific format, others that you write a little custom cypher. These work very well most of the time, but sometimes you run into data in weird shapes and coming in from vendors who aren’t willing to change just for you. What do you do in that case? Well, you write a custom importer. I’m going to show you how by importing the Cities database from MaxMind.

MaxMind is a company that provides location data for IP addresses. So when a user connects to your website you can (reasonably) know where they are located and can tailor your results to them. It’s not perfect, and doesn’t work too well when people are traveling… I was on a long vacation in Greece and Turkey this summer and kept getting advertisements in languages I could not understand… but they work fine for things like restaurant recommendations, job boards, travel guides, and…

Let’s take a look at the file format:
geoname_id,locale_code,continent_code,continent_name,country_iso_code,country_name,subdivision_1_iso_code,subdivision_1_name,subdivision_2_iso_code,subdivision_2_name,city_name,metro_code,time_zone 18918,en,EU,Europe,CY,Cyprus,04,Ammochostos,,,Protaras,,Asia/Nicosia 19889,en,EU,Europe,CY,Cyprus,04,Ammochostos,,,"Agios Nikolaos",,Asia/Nicosia 49518,en,AF,Africa,RW,Rwanda,,,,,,,Africa/Kigali 51537,en,AF,Africa,SO,Somalia,,,,,,,Africa/Mogadishu 53654,en,AF,Africa,SO,Somalia,BN,Banaadir,,,Mogadishu,,Africa/Mogadishu
We have a couple of things going on here. Now this is supposed to be City data so the geoname_id is going to be associated with a City. We are also getting the Continent it is on… I bet that gets confusing for Istanbul. We get the Country code and name, a subdivision or two, a Metro area and a Time Zone. We can use Arrows to put it all together in to a nice model:
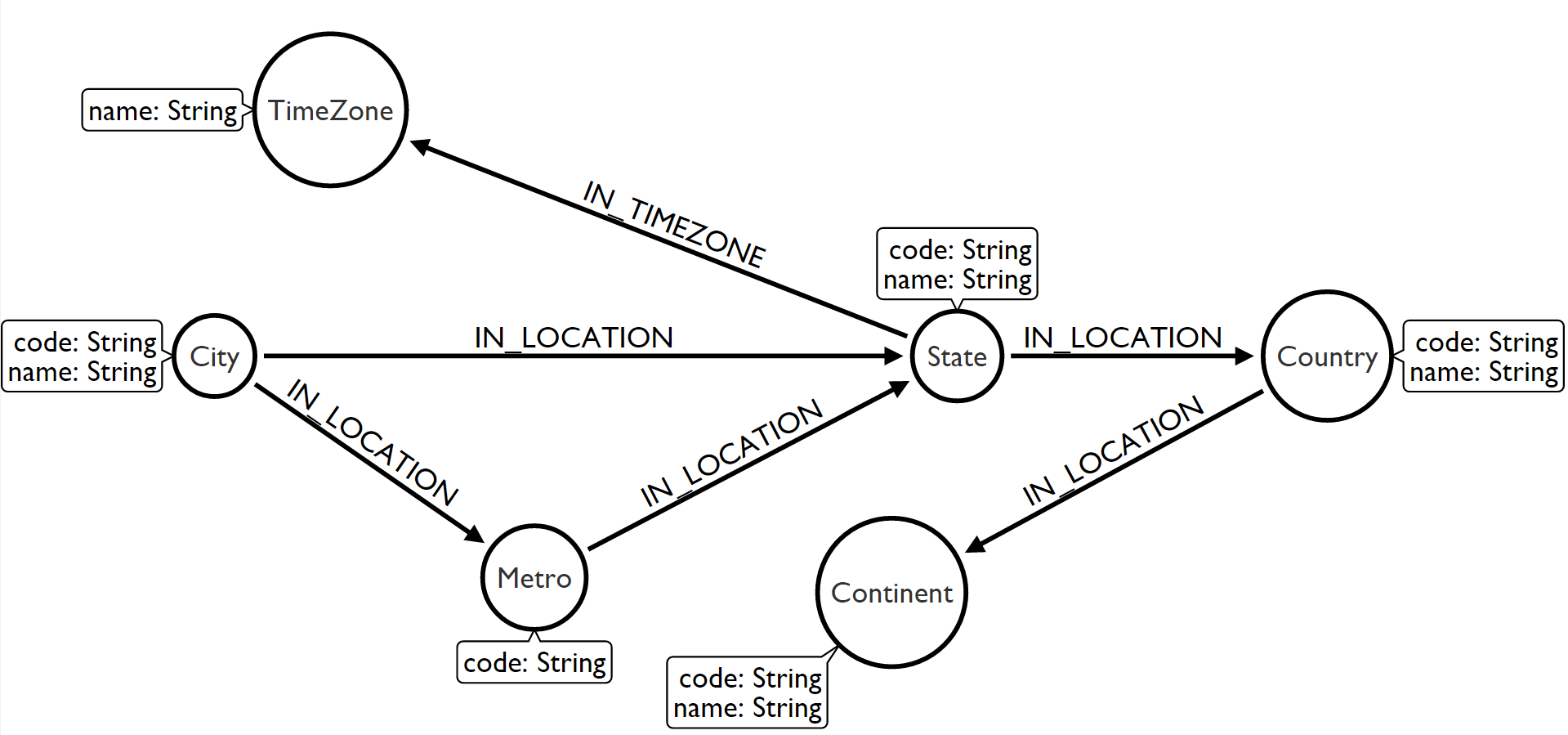
So let’s write the importer. Besides the usual Neo4j extension jars, we will use commons csv and add it to our pom.xml file:
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-csv</artifactId>
<version>1.2</version>
</dependency>
We will call it via an extension and expect the file to be on the server, so the API endpoint is pretty simple:
:POST /v1/import/locations {"file":"path to file"}
# for example:
:POST /v1/import/locations {"file":"/Users/maxdemarzi/Projects/import_maxmind/src/main/resources/data/GeoLite2-City-Locations-en.csv"}
The naive way to write the importer is to read every line in that csv file, create a new transaction find existing nodes, create new nodes and relationships if they don’t exist and close that transaction. But that is going to be slow. Neo4j is an ACID database so every transaction is a write all the way to disk and back. Every lookup is an index query, every relationship exist check is a traversal, etc. So instead we are going to commit every X many lines (let’s go with 1000):
Iterable records = CSVFormat.EXCEL.withHeader().parse(in);
Transaction tx = db.beginTx();
try {
for (CSVRecord record : records) {
count++;
if(!record.get("city_name").isEmpty()) {
city = db.createNode(Labels.City);
city.setProperty("geoname_id", record.get("geoname_id"));
city.setProperty("name", record.get("city_name"));
}
// do rest of work
if (count % 1000 == 0) {
tx.success();
tx.close();
tx = db.beginTx()
}
}
tx.success();
} finally {
tx.close();
}
…and let’s keep often repeated nodes and relationships in memory.
HashMap continents = new HashMap(); HashMap countries = new HashMap(); etc...
We can keep track of the continents, countries, states, etc in a map finding them by their code or name.
private Node getState(@Context GraphDatabaseService db, HashMap<String, Node> states, CSVRecord record) {
Node state = states.get(record.get("subdivision_1_iso_code"));
if (state == null) {
state = db.createNode(Labels.State);
state.setProperty("code", record.get("subdivision_1_iso_code"));
state.setProperty("name", record.get("subdivision_1_name"));
states.put(record.get("subdivision_1_iso_code"), state);
}
return state;
}
For keeping track of relationships, we will use a set and code our relationship by a prefix and their identifiers. For example
HashSet relationships = new HashSet();
// Connect Country to Continent if necessary
if (!relationships.contains("c2c" + record.get("country_iso_code") + "-" + record.get("continent_code"))) {
Node continent = getContinent(db, continents, record);
Node country = getCountry(db, countries, record);
country.createRelationshipTo(continent, RelationshipTypes.IN_LOCATION);
relationships.add("c2c" + record.get("country_iso_code") + "-" + record.get("continent_code"));
}
This code avoids any Lucene index searches as well as any checks to see if relationships already exist making it simple and fast. The source code for this project is available on github as always and instructions are on the readme. I’m going to build the jar, add it and the common-csv jar to my Neo4j plugins directory, restart it and import my data. It takes just a little bit and we can see what the import looks like here:
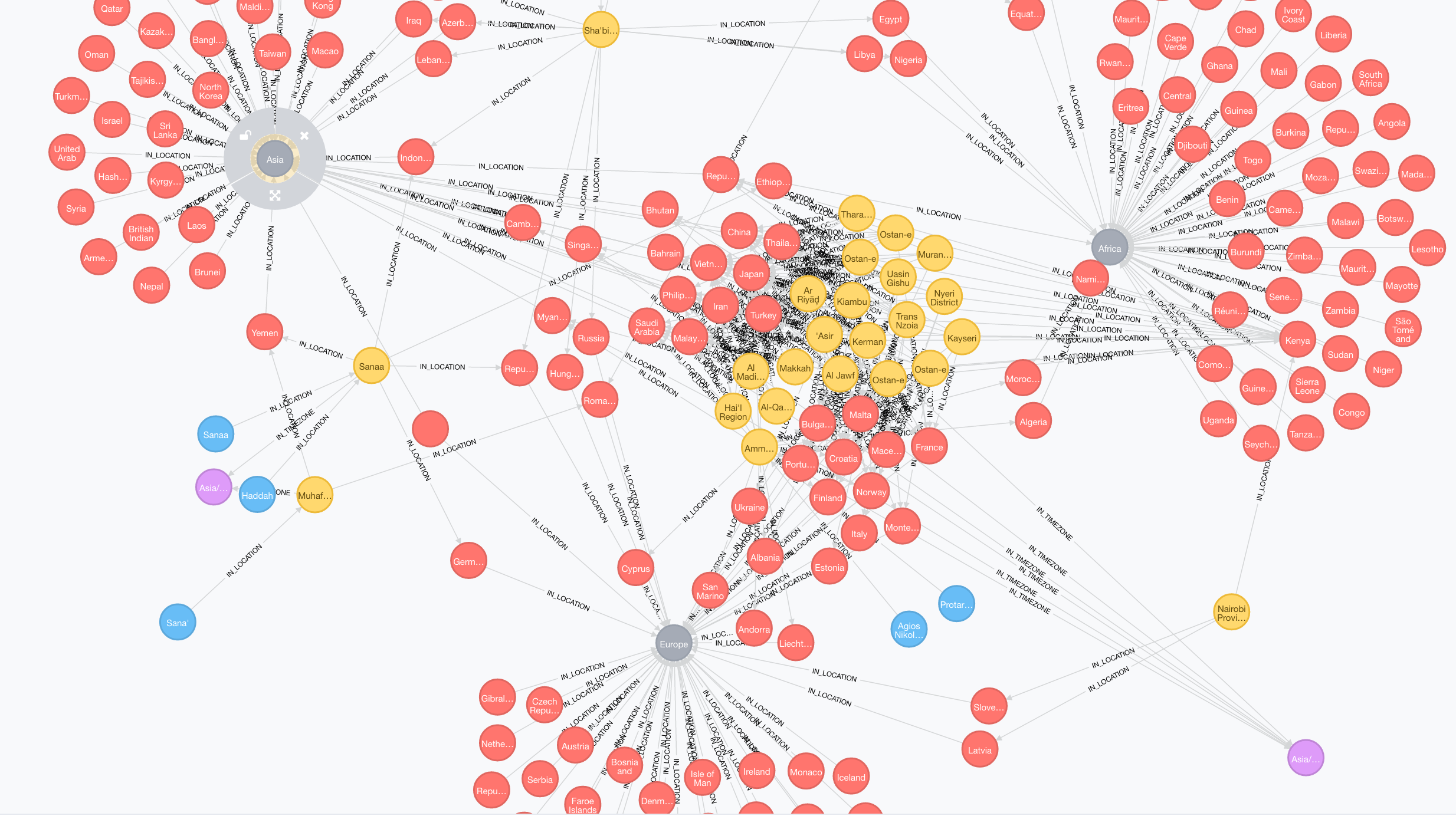
So there you have it. Our very own custom live batch importer into Neo4j. For medium sized datasets (a few million entries) this should work pretty well. For large datasets I still recommend the Neo4j Import tool… even though you may have to spend some time massaging your data to a format it can work with. Don’t forget that 80% of the job is data preparation, so enjoy.

[…] while back I showed you how to write an extension to import the MaxMind city data set. Today is just a repeat of that exercise but instead of using an extension, we will use a stored […]