
Neo4j 2.2 is getting released any day now, so let’s put the Release Candidate through its paces with Gatling. Once we download and start it up, you’ll notice it wants us to authenticate.
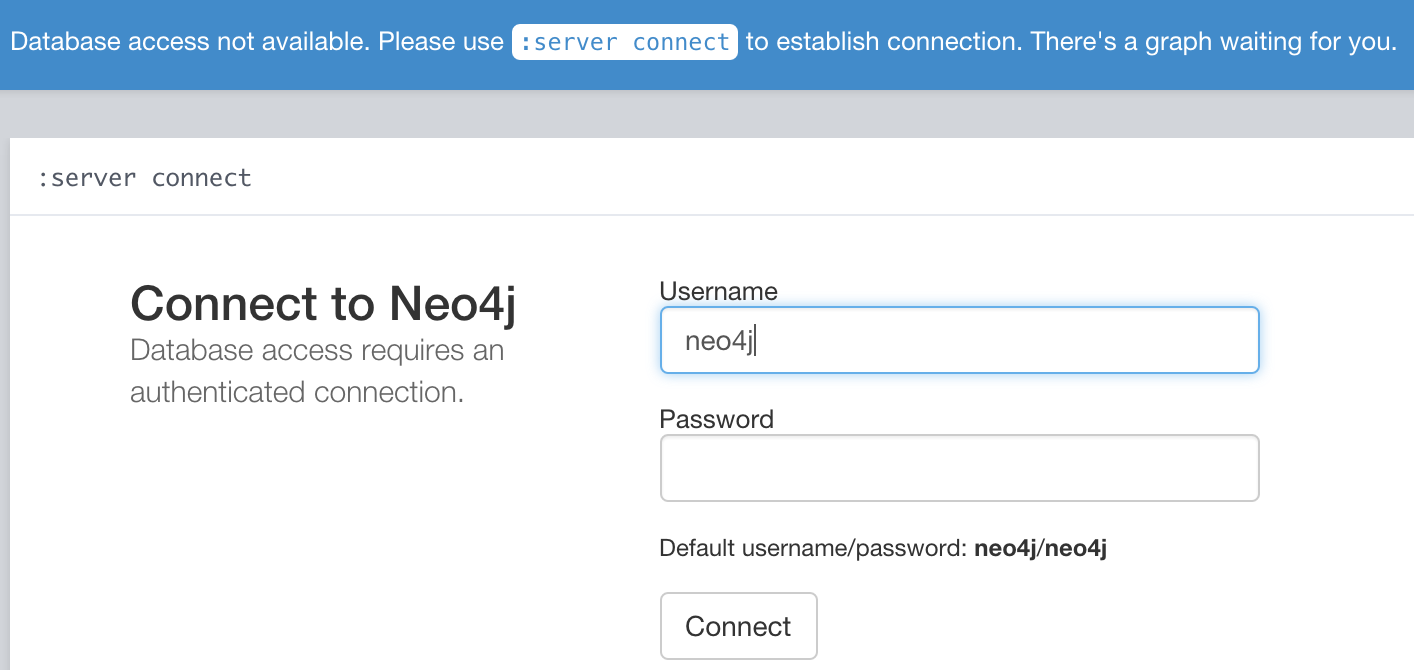
The default username and password is neo4j/neo4j. We’ll use that and it will ask us to change it to something more secure. So give me a minute or two here to come up with something original.

Ok I got it. Now that we’ve connected lets create a dataset. We’re going to create a random social network like we have in the past. So first we’ll create the users:
WITH ["Jennifer","Michelle","Tanya","Julie","Christie","Sophie","Amanda","Khloe","Sarah","Kaylee"] AS names
FOREACH (r IN range(0,100000) | CREATE (:User {username:names[r % size(names)]+r}))
and connect them:
MATCH (u1:User),(u2:User) WITH u1,u2 LIMIT 5000000 WHERE rand() < 0.1 CREATE (u1)-[:FRIENDS]->(u2);
Let’s try running a query. Which users are friends with “Kaylee83639”?
MATCH (me:User {username:'Kaylee83639'})-[:FRIENDS]-(people)
RETURN people.username

Great, that works. Now lets put the browser down and fire up IntelliJ. We’ll create a new project from a Maven Archetype. We are going to be using Gatling to test our cypher query, but we’ll do it directly in our IDE instead of on the console.

We are using “io.gatling.highcharts” for the GroupId, “gatling-highcharts-maven-archetype” for the ArtifactId and “2.1.2” for the version. Give it a few more settings, then wait a few seconds while it creates your project. Next we’ll create a simulation, lets call it “GetFriends” and set it up to connect to our localhost on port 7474.
import io.gatling.core.Predef._
import io.gatling.core.scenario.Simulation
import io.gatling.http.Predef._
import scala.concurrent.duration._
class GetFriends extends Simulation {
val httpConf = http
.baseURL("http://localhost:7474")
.acceptHeader("application/json")
/* Uncomment to see the response of each request.
.extraInfoExtractor(extraInfo => {
println(extraInfo.response.body.string)
Nil
}).disableResponseChunksDiscarding
*/
For debugging purposes, we can print the response of each request to the screen, but I normally leave this off unless something doesn’t make sense. Next we’ll add our cypher query and format it in a way that the Transactional Cypher HTTP endpoint expects.
val query = """MATCH (me:User {username:'Kaylee83639'})-[:FRIENDS]-(people) RETURN people.username"""
val cypherQuery = """{"statements" : [{"statement" : "%s"}]}""".format(query)
Now we can setup our scenario, to run the query 1000 times for each gatling user. We’ll pass our cypher query as the body of a JSON post message to the cypher endpoint and make sure we get an “OK” response from the server.
val scn = scenario("Get Friends")
.repeat(1000) {
exec(
http("get friends")
.post("/db/data/transaction/commit")
.body(StringBody(cypherQuery))
.asJSON
.check(status.is(200))
)
}
Next, we’ll setup our scenario to start with 1 user and ramp up to 10 users over a period of 10 seconds.
setUp(
scn.inject(rampUsers(10) over(10 seconds)).protocols(httpConf)
)
… and now we can run it. Right click on the “Engine” file in our scala directory and run it.
Follow along with the instructions (or just hit enter twice) and lets see what happens:
================================================================================ ---- Global Information -------------------------------------------------------- > request count 10000 (OK=0 KO=10000 ) > min response time 0 (OK=- KO=0 ) > max response time 4 (OK=- KO=4 ) > mean response time 0 (OK=- KO=0 ) > std deviation 0 (OK=- KO=0 ) > response time 50th percentile 0 (OK=- KO=0 ) > response time 75th percentile 1 (OK=- KO=1 ) > mean requests/sec 1047.559 (OK=- KO=1047.559) ---- Response Time Distribution ------------------------------------------------ > t < 800 ms 0 ( 0%) > 800 ms < t < 1200 ms 0 ( 0%) > t > 1200 ms 0 ( 0%) > failed 10000 (100%) ---- Errors -------------------------------------------------------------------- > status.find.is(200), but actually found 401 10000 (100.0%) ================================================================================
Whoa! They all failed. But we can easily tell why. It was expecting a status of 200 and got a 401 instead. If you remember your http status codes, 401 means “Unauthorized”. We need to change our test to pass in the username and password we created earlier.
val scn = scenario("Get Friends")
.repeat(1000) {
exec(
http("get friends")
.post("/db/data/transaction/commit")
.basicAuth("neo4j", "swordfish")
.body(StringBody(cypherQuery))
.asJSON
.check(status.is(200))
)
}
Now it works. I’ll run the test a couple of times to get everything nice and warmed up and we get about 32 requests per second.

That doesn’t look right, let’s see what’s going on. Back to Neo4j, we’ll add the word “PROFILE” to the beginning of our query…
PROFILE MATCH (n:User {username:'Kaylee83639'})-[:FRIENDS]-(people) RETURN people.username
…and Neo4j will give us a visualization of just what is going on.

Take a look at that. It’s scanning 100,000 User nodes looking for a username property that equals “Kaylee83639”. It’s doing that because we created our dataset but forgot to add indexes! So let’s do that now:
CREATE INDEX ON :User(username)
Wait, wait, let’s not do that. In this case, the username property is meant to be unique across all our User nodes. Let’s create a Uniqueness Constraint instead which will make sure only one Kaylee83639 exists in our graph and also create an index for us.
CREATE CONSTRAINT ON (me:User) ASSERT me.username IS UNIQUE
We can verify this by running :schema in our web console.

Lets try our profile again.

That looks better. Now it’s using the User(username) index to find “Kaylee83639” instead of scanning the username properties of all the User Nodes. Yes, I said ALL the User Nodes because it didn’t know that there is only one Kaylee83639. So back to Gatling, what happens if we try our test again?

About 1035 requests per second. That’s a 1000 requests more per second than before and a massive improvement. So please, if you are starting out with Neo4j, don’t forget to add Uniqueness Constraints or Schema Indexes to any properties that will be used as a starting point to your traversals.
Now we know how fast we can get Kaylee83639’s friends, but what the other users in our database? Let’s modify our performance test to query different people. First we’ll need a sample of say 1000 users.
MATCH (n:User) RETURN n.username AS username ORDER BY rand() limit 1000
Let’s export and save that as a CSV file.

We’ll put that file in our project under the src/test/resources/data directory as usernames.csv and change our code to reference it.
val feeder = csv("usernames.csv").circular
Then we’ll change our cypher query to make use of the parameter.
val query = """MATCH (me:User {username:{username}})-[:FRIENDS]-(people) RETURN people.username"""
val cypherQuery = """{"statements" : [{"statement" : "%s", "parameters" : { "username": "${username}" }}]}""".format(query)
You may have to scroll the code above to the right, but you’ll notice this little nugget:
"${username}"
This is Gatling magic (technically it’s a session attribute being modified by Gatling’s Expression Language which automagically parses it and dynamically changes its value). It will replace that ${username} with a username value from the usernames.csv file if we feed it that value when we execute our tests. So we will change the scenario to use the feed:
val scn = scenario("Get Friends")
.repeat(1000) {
feed(feeder)
.exec(
http("get friends")
...
Finally we’ll run the test again.

No surprise here, it takes about the same time as getting just one user because the operation is the same, find a node in the User(username) schema index and traverse from there. Whether you have 100K users, 10M users of 1B users it should still take approximately the same time to find their friends.
So make use of the new PROFILE capabilities of the Neo4j Browser to get a better idea of what that cypher query is doing. Look for NodeByLabelScans that can be replaced with NodeUniqueIndexSeeks or NodeIndexSeeks by adding unique constraints or indexes where you need them. Lastly be sure you always test everything before heading in to production. If you’ve been following my blog, you know there are always ways to make Neo4j go faster. If you aren’t seeing the performance you need, make sure you reach out and let me know.
As always, the code is on github.
