
By the end of this blog post, you are going to experience two epiphanies about databases. However, you are going to have to do a little more work than just read. You are going to have to stop and actually think about what you’re reading. I promise it will be worth it. Let’s go!
A relational database has tables with columns of numbers we refer to as keys. User_ID 1, 2, 3, Place_ID 1, 2, 3, Book_ID 1, 2, 3… and so on. These are numbers that are hopefully the same on some other column on some other table. The database itself has absolutely no idea how things are connected until you query it and you tell it exactly how to use these columns to join the tables together. Think about that.
Now, a graph database has explicit relationships. You never have to ask it to search for some id in some column. It knows how things are connected. Tell me about yourself Node A. I am 5’11” and 200 lbs, I have brown eyes… Now tell me how you are related to the world. These are my Friends, these are the Companies I have worked at, these are the Skills I have learned, these are the Things I like. How are you and this other noted related? We are 4 hops away through x, y an z nodes.
That’s it. With that one idea, your database goes from disconnected tables to suddenly knowing about it’s structure, and relationships. The data was always there like some repressed memory, but now it can access it. You get tremendous power with that feature. But it stops there. How things are connected is ALL it knows. We can go much further. Before we do that, let’s talk about what’s going on in the world lately. Massive amounts of AI Tokens are being burned and vendors are talking about semantic layers to quench that fire.

Everyone is trying to add graphs to their AI pipeline. You have vendors selling “GraphRAG” and “knowledge graphs” and “context graphs” and “semantic layers” of all kinds. Some are in actual graph databases, some are in other kinds of databases, some are in markdown or yaml, some use popularity to decide what’s right and what’s wrong. You have projects like graphify that automatically builds a graph of your code and your documents into text to lower your token use. Then you have other projects like graphify md that builds compressed knowledge graphs of your code and your documents into text to lower your token use. Yeah, there are two of them with the same name and a hundred other variants all promising to lower your token use.
When you boil it down to the bare essentials. They all produce words. Words for your Large Language Model to read and try to interpret correctly. Words for your LLM to ingest and hallucinate.

Today is the last day, that you are using words. The song “Bedtime Story” by Madonna warns you about the dangers of relying on words. Take a good look at the lyrics and think about the last time you asked AI to do something and it got it oh so very wrong.
Today is the last day that I’m using words
They’ve gone out, lost their meaning, don’t function anymore
Words are useless, especially sentences
They don’t stand for anything
I’m traveling, traveling, leaving logic and reason
And all that you ever learned, try to forget…I’ll never explain again
The Material Girl, always avant-garde. LLMs appear intelligent because they’ve been trained on word sequences that usually make sense. We’ve encoded the things people know in language, so training LLMs on that language appears true on the surface. But it’s just words. So if adding more words isn’t going to solve things, what is?
It’s right there in the lyrics. Logic and Reason. Today most of the logic that governs how a database responds to complex business questions lives in queries, stored procedures, application code, and many other places that are not directly connected to the data. The only thing that comes close to the data is Views, which are very limited in most databases and graph databases don’t even have.
What if we made logic a first class citizen? What if we could write little fragments of logic that were directly tied to the data? Each composable and chainable, every fragment serving as a sort of “Lego Brick” that when placed together could be used to build large and complex systems? However, each one would be easy to understand and verify by a person. The logic could classify objects based on some aggregate. For example a user may become a “high value customer” when their total purchases over the last 90 days are over some threshold. The logic could derive properties. For example “number of days late” when a shipment is past the promised delivery date. Every day that passed the property would be automatically updated. Similar to a calculated fields but without the volatile data, cross table, and no chaining limitations imposed by most databases. The logic could use that delayed days derived property to connect a Customer to their late Order by a “DELAYED_ORDERS” relationship. Logic could trigger a change to a property, for example those delayed orders should have their status marked as “delayed” the moment we miss the promised delivery date. We could predict which high value customers are likely to leave us for the competition because keep delaying their orders. We could use the logic in the system to optimize our inventory of popular items in various warehouses to reduce delayed orders to lower customer churn. From small little fragments of logic to helping us make decisions about our supply chain.
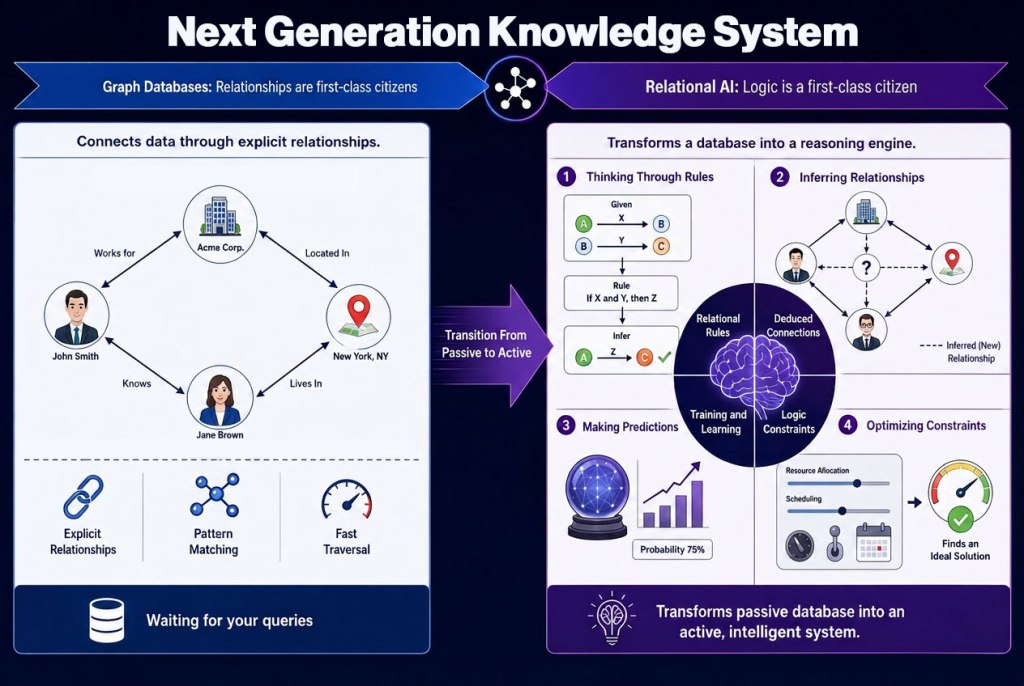
All the logic that currently exists in your queries, in your stored procedures, in your documentation, in your application code, in your “ontology” yaml files or json “graph” documents can all stop being just words and become executable logic. No hallucination is possible when the logic is in the database and not outside of it.
How do we do this? I gave you a hint earlier. In a word: Views. Views without limits, able to use all the relational algebra available. Views that can chain together because they have explicit relationships between them. Even recursively, even in cycles. You can take any View and get a trace of all the other views it is made from. But you also need one more thing to make this work: a Semantic Optimizer. We’ll talk about that another day, but I hope you realize that the semantic layer is in the database.
To all the vendors building these “knowledge graphs”, “agentic memory”, “semantic layers”, “ontologies”, etc.
Thank you. We’ll take it from here.
